ICCV 2019|DewarpNet: 基于2D和3D回归网络的单幅图像文档矫正方法(已开源)
加入极市专业CV交流群,与6000+来自腾讯,华为,百度,北大,清华,中科院等名企名校视觉开发者互动交流!更有机会与李开复老师等大牛群内互动!
同时提供每月大咖直播分享、真实项目需求对接、干货资讯汇总,行业技术交流。关注 极市平台 公众号 ,回复 加群,立刻申请入群~

本文简要介绍ICCV2019 论文“DewarpNet: Single-Image Document Unwarping With Stacked 3D and 2D Regression Networks”的主要工作。该论文主要针对手持设备拍摄文档图像时,存在纸张含有物理形变、相机拍摄角度和光照条件多变的问题提出矫正方法。作者先通过对形变纸张进行3维信息的采集,再将平整文档图像渲染到形变的纸张图像上,得到了形变的文档图像。形变的文档图像作为输入,纸张的3维信息、渲染过程的逆变换、平整文档图像共同作为Ground-truth,构成了含有丰富标注信息的数据集Doc3D。作者利用这些标注信息训练一个深度学习模型DewarpNet,在不需要额外硬件和多角度图像的情况下对该类文档图像进行矫正,可以得到接近平面扫描仪的效果,处理后的图像可以显著提高OCR性能。最终取得了State-of-the-art的结果。

一、研究背景
纸质文档在我们生活中十分重要且常见,上面具有丰富的信息。而数字文档则易于存储、传播以及检索。如今移动摄像头拍摄文档图像是方便且常见的文档数字化方法,但得到的图像由于纸张的物理形变、相机拍摄角度和光照条件多变的原因,不利于自动化信息提取和内容分析。有的研究通过低维的模型来对文档的形变进行建模,这是较难实现的;还有的研究直接假定一个网格(Mesh)对形变图像进行表征,然后直接预测网格上每个顶点对应于输出图像的位置,但很多都需要额外的硬件设备或多角度图像,而且计算量大且费时。近期的研究[1]中虽然提出了更快的方法,但由于训练数据只包含2维形变信息,所以对真实图片测试效果不鲁棒。
二、方法原理简述
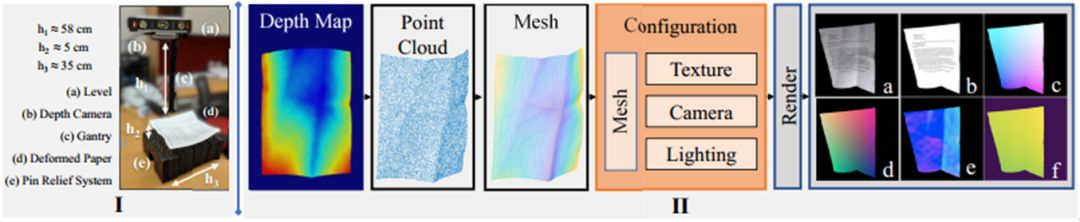
图2是文章提出的数据采集方法的流程,主要分为I和II两个阶段。在I阶段,作者利用一个工作台,得到真实纸张的Depth Map,工作台关键部件有深感相机(用于拍摄纸张的深度图)、针浮雕系统(Pin Relief System,含有64个独立的针,可以改变纸张不同位置的高度,实现多种形变并保持)。有了Depth Map后,通过相机的参数可以直接计算得到Point Cloud。计算点云时作者对同一图拍了6张并取平均以减少零均值噪声(Zero-mean Noise),同时用一些算法对点云进行平滑处理。之后用球旋转算法(Ball Pivoting Algorithm)[3]得到网格,下采样为100x100大小。为网格中每个顶点指定UV坐标,便于后续渲染。之后还对网格进行了旋转、裁剪(裁剪后插值回100x100)的增广操作。贴图渲染过程中,综合改变贴图内容、角度、光照、背景。最终每张图都可以生成3D Coordinate Map, Depth Map, Normals, UV Map, Albedo Map标注信息。
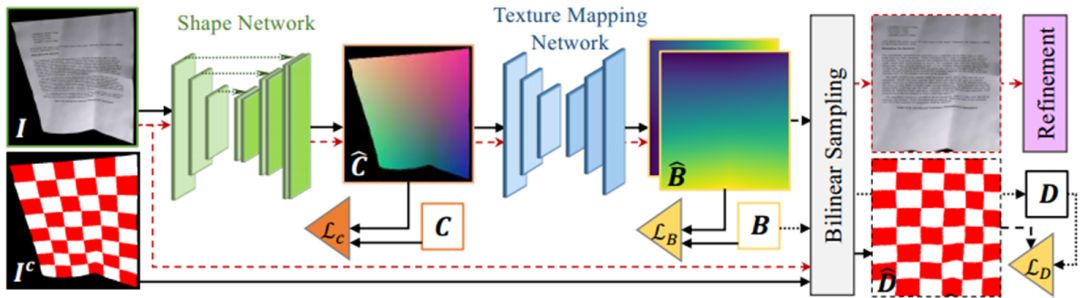
DewarpNet主要包含两个子网络Shape Network和Texture Mapping Network。前者为一个U-net[4]网络,以原图I∈Rh×w×3作为输入,预测3D Coordinate Map Ĉ∈Rh×w×3(每个像素的值是一个三维向量,代表纸张该点的空间坐标)。后者为由多个DenseNet Block[5]构成,以Ĉ 作为输入,预测Backward Mapping B̂∈Rh×w×2(每个像素的值是一个二维向量,代表I的像素在矫正后图像中的位置),因为该子网络实现了3维坐标到2维坐标的转换,作者使用了在坐标转换任务中能提高泛化能力的Coordinate Convolution (CoordConv)[6]。Ic是I以棋盘图案为贴图内容时生成的图像,模型预测出的B̂作用于Ic得到预测D̂∈Rh×w×3,这一做法的目的是让损失函数LD(见下文)损失函数不受贴图内容的影响,使得模型对形变相同但贴图内容的不同的图像的矫正参数是相同的,Ic只用在训练过程中。训练的损失函数为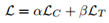
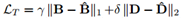
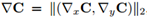

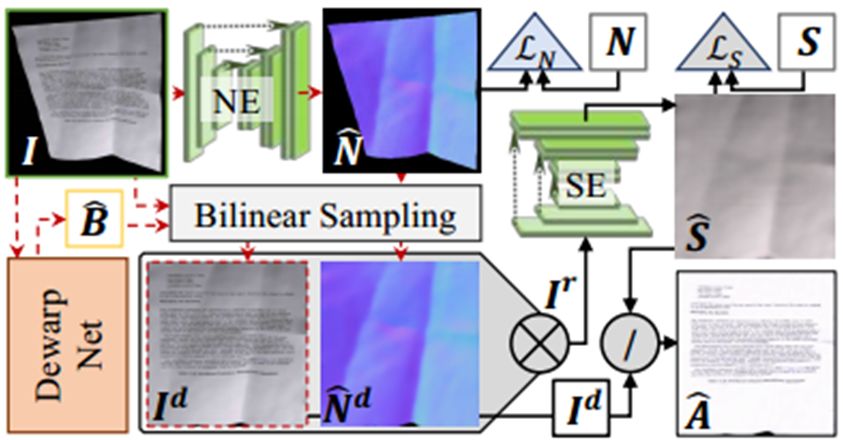
后处理网络对矫正后图像Id的光照情况进一步优化,提高了视觉质量和OCR性能。网络包含两个U-net网络,一个U-net以原图I作为输入,预测Surface Norm N̂∈Rh×w×3。N̂矫正后得到N̂d。另一个U-net以Id和N̂d作为输入,预测Shading Map Ŝ∈Rh×w×3(表征了图像的光照情况和颜色),利用Id和Ŝ可运算得到去阴影的图像Â(具体计算过程可见论文的补充材料)。
三、主要实验结果及可视化结果
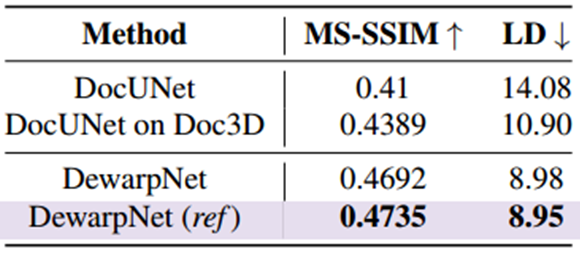

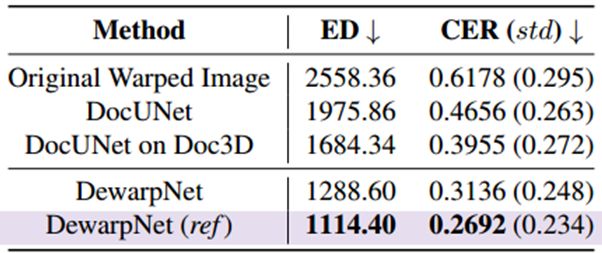



表1中DocUNet和DocUNet on Doc3D 分别代表DocUNet在原数据集和在Doc3D上训练出来的模型;DewarpNet和DewarpNet (ref)分别代表不包含和包含后处理。可以看到本文模型在该Benchmark[1]下的MM-SSIM 和 LD指标都取得了State‑of‑the‑art的结果,同时也证明了数据集Doc3D的有效性。为进一步探究,作者把[1]的Benchmark按照难度分为了a~f 6类,由a到f,难度依次增加,结果展示在图5中。前5类中本文模型都优于DocUNet,最难的f中本文模型取得了与DocUNet相近和稍好一点结果。
四、总结及讨论
-
提出了一个新颖的DewarpNet网络,通过对纸张3维结构的显式建模,训练出来的模型对不同的文档内容、光照、背景等都有很好的鲁棒性,取得了state-of-the-art的结果。 -
提出了一个新的含有丰富标注信息(2D和3D)的数据集Doc3D,以及其采集方法。 -
不足: 1、深度相机精度不足导致对一些纸张复杂的细节处的建模不够好。 2、模型对遮挡十分敏感,遮挡会导致结果性能的下降。
五、相关资源
DewarpNet: Single-Image Document Unwarping With Stacked 3Dand 2D Regression Networks论文、论文补充材料、代码、DewarpNetdemo、Doc3D数据集下载地址:https://sagniklp.github.io/dewarpnet-webpage/
-
DocUNet[1]中的benchmark下载地址: https://www3.cs.stonybrook.edu/~cvl/docunet.html
原文作者:Sagnik Das, Ke Ma, Zhixin Shu, Dimitris Samaras, Roy Shilkrot
-End-
*延伸阅读
极市 OCR 技术交流群
添加极市小助手微信(ID : cv-mart),备注:研究方向-姓名-学校/公司-城市(如:文本检测-小极-北大-深圳),即可申请加入极市OCR技术交流群(已经添加小助手的好友直接私信),更有每月大咖直播分享、真实项目需求对接、干货资讯汇总,行业技术交流,一起来让思想之光照的更远吧~

△长按添加极市小助手

△长按关注极市平台
觉得有用麻烦给个在看啦~




