CVPR 2022 | FAIR提出MaskFeat:自监督视觉预训练新方法!灵感之一来自16年前CVPR论文
点击下方卡片,关注“CVer”公众号
AI/CV重磅干货,第一时间送达
点击下方卡片,关注“CVer”公众号
AI/CV重磅干货,第一时间送达
转载自:新智元 | 编辑:小咸鱼 好困
转载自:新智元 | 编辑:小咸鱼 好困
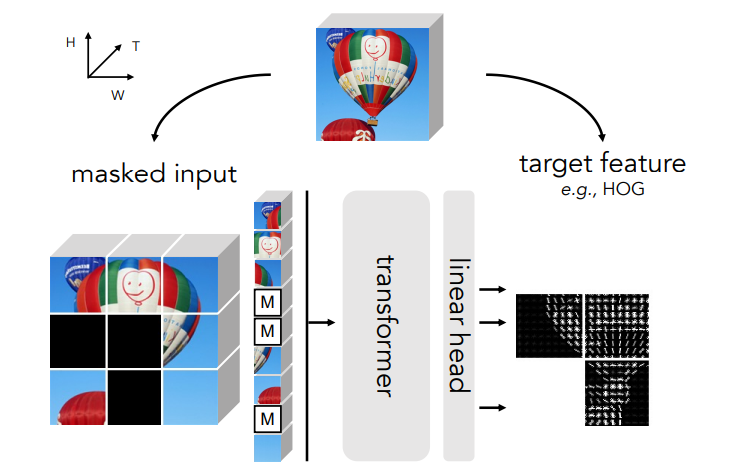
【导读】近日,北大校友、约翰·霍普金斯大学博士生提出了一种新的方法:MaskFeat,摘下12个SOTA!


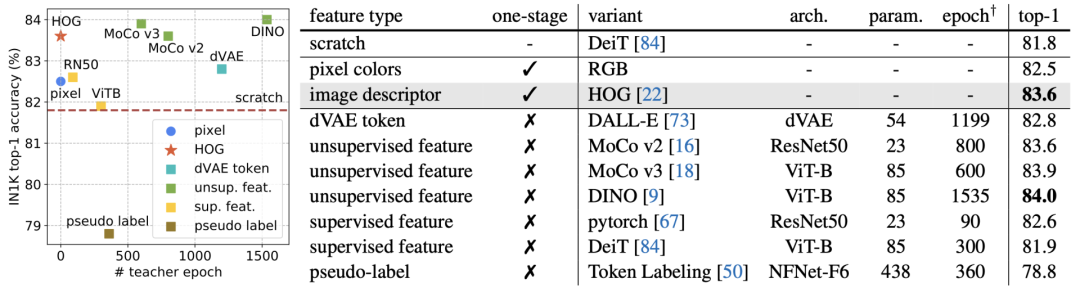
HOG VS Pixel Colors
HOG VS Pixel Colors
 图像HOG特征向量
图像HOG特征向量




结果分析
结果分析
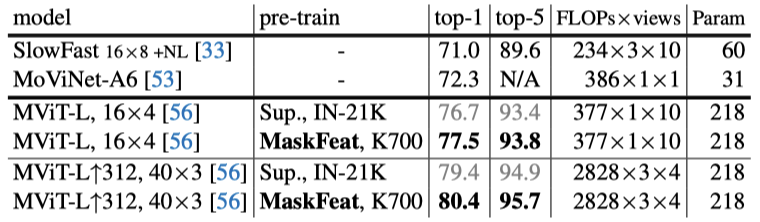
Kinetics-400数据集

Kinetics-600 & Kinetics-700数据集

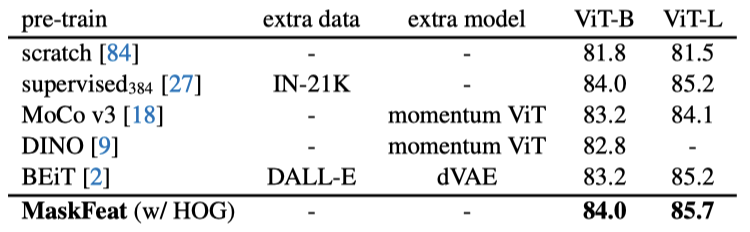
ImageNet-1K数据集
对此,来自清华大学的知友「谢凌曦」表示:
视觉自监督领域做了这么些年,从最早的生成式学习出发,绕了一圈,又回到生成式学习。 到头来,我们发现像素级特征跟各种手工特征、tokenizer、甚至离线预训练网络得到的特征,在作为判断生成图像质量方面,没有本质区别。
也就是说,自监督也许只是把模型和参数调得更适合下游任务,但在「新知识从哪里来」这个问题上,并没有任何实质进展。
参考资料:
https://arxiv.org/pdf/2112.09133.pdf
https://www.zhihu.com/question/506657286/answer/2275700206
上面论文代码下载
后台回复:MaskFeat,即可下载上述论文
后台回复:CVPR2021,即可下载CVPR 2021论文和代码开源的论文合集
后台回复:ICCV2021,即可下载ICCV 2021论文和代码开源的论文合集
后台回复:Transformer综述,即可下载最新的3篇Transformer综述PDF
重磅!Transformer交流群成立
扫码添加CVer助手,可申请加入CVer-Transformer 微信交流群,方向已涵盖:目标检测、图像分割、目标跟踪、人脸检测&识别、OCR、姿态估计、超分辨率、SLAM、医疗影像、Re-ID、GAN、NAS、深度估计、自动驾驶、强化学习、车道线检测、模型剪枝&压缩、去噪、去雾、去雨、风格迁移、遥感图像、行为识别、视频理解、图像融合、图像检索、论文投稿&交流、Transformer、PyTorch和TensorFlow等群。
一定要备注:研究方向+地点+学校/公司+昵称(如Transformer+上海+上交+卡卡),根据格式备注,可更快被通过且邀请进群

▲长按加小助手微信,进交流群
▲点击上方卡片,关注CVer公众号
整理不易,请点赞和在看
登录查看更多
相关内容
Arxiv
1+阅读 · 2022年7月31日
Arxiv
0+阅读 · 2022年7月28日
Arxiv
12+阅读 · 2021年5月30日



相关VIP内容
相关资讯
相关论文
Arxiv
1+阅读 · 2022年7月31日
Arxiv
0+阅读 · 2022年7月28日
Arxiv
12+阅读 · 2021年5月30日