ESRGAN:基于GAN的增强超分辨率方法(附代码解析)

作者丨左育莘
学校丨西安电子科技大学
研究方向丨计算机视觉
之前看的文章里有提到 GAN 在图像修复时更容易得到符合视觉上效果更好的图像,所以也是看了一些结合 GAN 的图像修复工作。
ESRGAN: Enhanced Super-Resolution Generative Adversarial Networks 发表于 ECCV 2018 的 Workshops,作者在 SRGAN 的基础上进行了改进,包括改进网络的结构、判决器的判决形式,以及更换了一个用于计算感知域损失的预训练网络。


超分辨率生成对抗网络(SRGAN)是一项开创性的工作,能够在单一图像超分辨率中生成逼真的纹理。这项工作发表于 CVPR 2017。
但是,放大后的细节通常伴随着令人不快的伪影。为了更进一步地提升视觉质量,作者仔细研究了 SRGAN 的三个关键部分:1)网络结构;2)对抗性损失;3)感知域损失。并对每一项进行改进,得到 ESRGAN。
具体而言,文章提出了一种 Residual-in-Residual Dense Block (RRDB) 的网络单元,在这个单元中,去掉了 BN(Batch Norm)层。此外,作者借鉴了 Relativistic GAN 的想法,让判别器预测图像的真实性而不是图像“是否是 fake 图像”。
最后,文章对感知域损失进行改进,使用激活前的特征,这样可以为亮度一致性和纹理恢复提供更强的监督。在这些改进的帮助下,ESRGAN 得到了更好的视觉质量以及更逼真和自然的纹理。
改进后的效果图(4 倍放大):
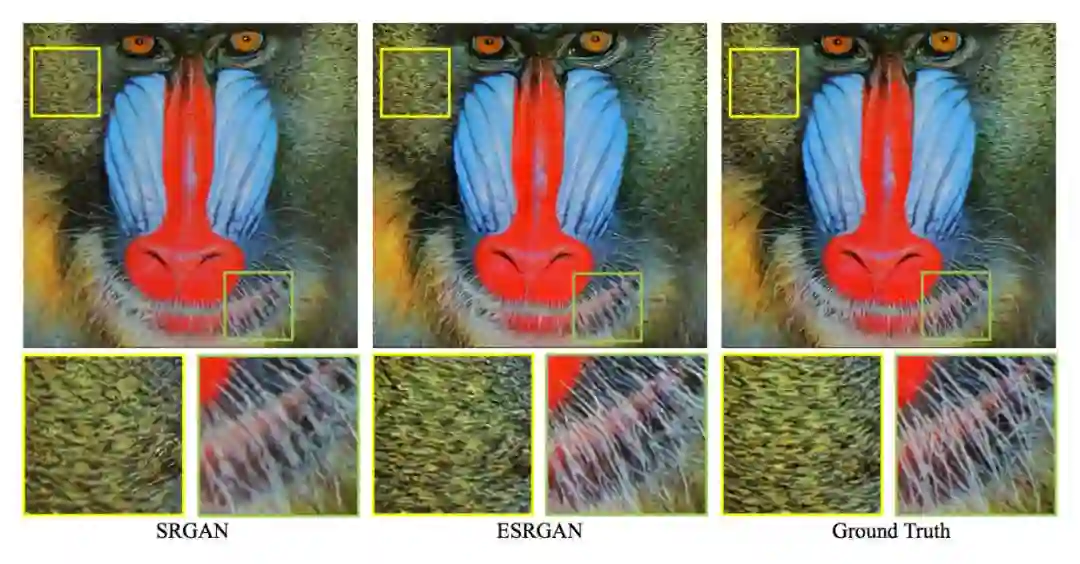
▲ 在纹理和细节上,ESRGAN都优于SRGAN
SRGAN的思考与贡献
现有的超分辨率网络在不同的网络结构设计以及训练策略下,超分辨的效果得到了很大的提升,特别是 PSNR 指标。但是,基于 PSNR 指标的模型会倾向于生成过度平滑的结果,这些结果缺少必要的高频信息。PSNR 指标与人类观察者的主观评价从根本上就不统一。
一些基于感知域信息驱动的方法已经提出来用于提升超分辨率结果的视觉质量。例如,感知域的损失函数提出来用于在特征空间(instead of 像素空间)中优化超分辨率模型;生成对抗网络通过鼓励网络生成一些更接近于自然图像的方法来提升超分辨率的质量;语义图像先验信息用于进一步改善恢复的纹理细节。
通过结合上面的方法,SRGAN 模型极大地提升了超分辨率结果的视觉质量。但是 SRGAN 模型得到的图像和 GT 图像仍有很大的差距。
ESRGAN的改进
文章对这三点做出改进:
1. 网络的基本单元从基本的残差单元变为 Residual-in-Residual Dense Block (RRDB);
2. GAN 网络改进为 Relativistic average GAN (RaGAN);
3. 改进感知域损失函数,使用激活前的 VGG 特征,这个改进会提供更尖锐的边缘和更符合视觉的结果。
网络结构及思想
生成器部分
首先,作者参考 SRResNet 结构作为整体的网络结构,SRResNet 的基本结构如下:
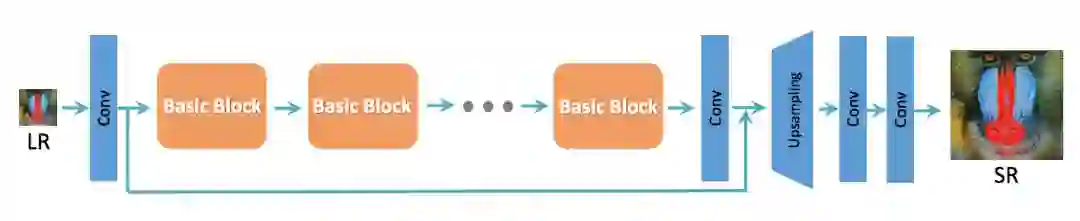
▲ SRResNet基本结构
为了提升 SRGAN 重构的图像质量,作者主要对生成器 G 做出如下改变:
1. 去掉所有的 BN 层;
2. 把原始的 block 变为 Residual-in-Residual Dense Block (RRDB),这个 block 结合了多层的残差网络和密集连接。
如下图所示:
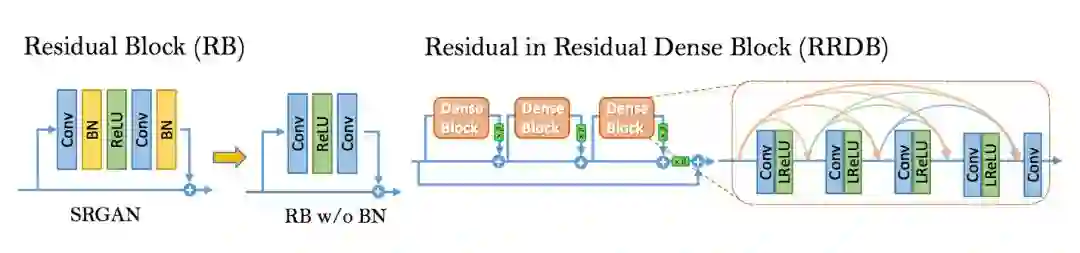
思想
BN 层的影响:对于不同的基于 PSNR 的任务(包括超分辨率和去模糊)来说,去掉 BN 层已经被证明会提高表现和减小计算复杂度。
BN 层在训练时,使用一个 batch 的数据的均值和方差对该 batch 特征进行归一化,在测试时,使用在整个测试集上的数据预测的均值和方差。当训练集和测试集的统计量有很大不同的时候,BN 层就会倾向于生成不好的伪影,并且限制模型的泛化能力。
作者发现,BN 层在网络比较深,而且在 GAN 框架下进行训练的时候,更会产生伪影。这些伪影偶尔出现在迭代和不同的设置中,违反了对训练稳定性能的需求。所以为了稳定的训练和一致的性能,作者去掉了 BN 层。此外,去掉 BN 层也能提高模型的泛化能力,减少计算复杂度和内存占用。
Trick
除了上述的改进,作者也使用了一些技巧来训练深层网络:
1. 对残差信息进行 scaling,即将残差信息乘以一个 0 到 1 之间的数,用于防止不稳定;
2. 更小的初始化,作者发现当初始化参数的方差变小时,残差结构更容易进行训练。
判别器部分
除了改进的生成器,作者也基于 Relativistic GAN 改进了判别器。判别器 D 使用的网络是 VGG 网络,SRGAN 中的判别器 D 用于估计输入到判别器中的图像是真实且自然图像的概率,而 Relativistic 判别器则尝试估计真实图像相对来说比 fake 图像更逼真的概率。
如下图所示:
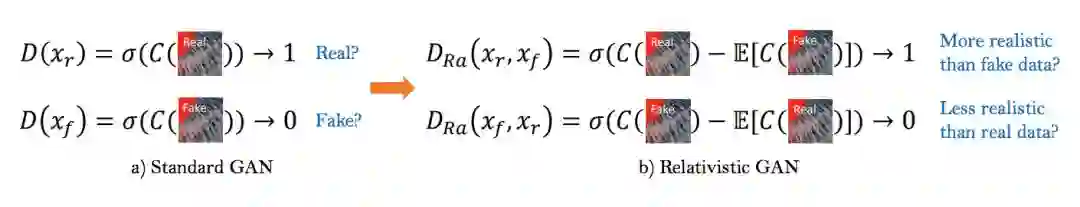
具体而言,作者把标准的判别器换成 Relativistic average Discriminator(RaD),所以判别器的损失函数定义为:
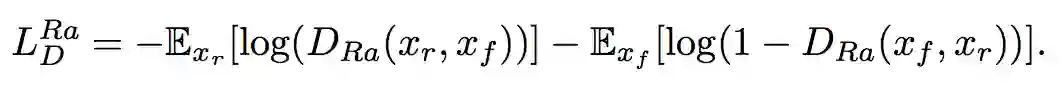
对应的生成器的对抗损失函数为:
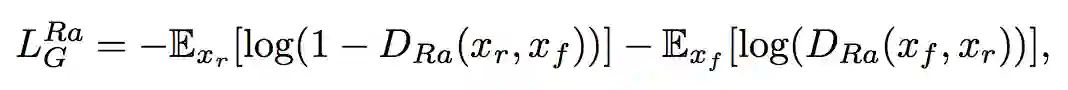
求均值的操作是通过对 mini-batch 中的所有数据求平均得到的,xf 是原始低分辨图像经过生成器以后的图像。
可以观察到,对抗损失包含了 xr 和 xf,所以这个生成器受益于对抗训练中的生成数据和实际数据的梯度,这种调整会使得网络学习到更尖锐的边缘和更细节的纹理。
感知域损失
文章也提出了一个更有效的感知域损失,使用激活前的特征(VGG16 网络)。
感知域的损失当前是定义在一个预训练的深度网络的激活层,这一层中两个激活了的特征的距离会被最小化。
与此相反,文章使用的特征是激活前的特征,这样会克服两个缺点。第一,激活后的特征是非常稀疏的,特别是在很深的网络中。这种稀疏的激活提供的监督效果是很弱的,会造成性能低下;第二,使用激活后的特征会导致重建图像与 GT 的亮度不一致。
如图所示:
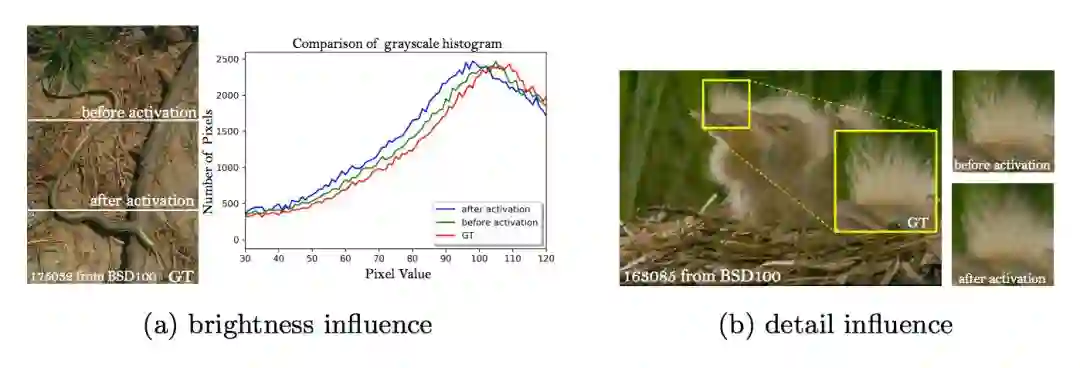
▲ 使用激活前与激活后的特征的比较:a. 亮度 b. 细节
作者对使用的感知域损失进行了探索。与目前多数使用的用于图像分类的 VGG 网络构建的感知域损失相反,作者提出一种更适合于超分辨的感知域损失,这个损失基于一个用于材料识别的 VGG16 网络(MINCNet),这个网络更聚焦于纹理而不是物体。尽管这样带来的增益很小,但作者仍然相信,探索关注纹理的感知域损失对超分辨至关重要。
损失函数
经过上面对网络模块的定义和构建以后,再定义损失函数,就可以进行训练了。
对于生成器 G,它的损失函数为:
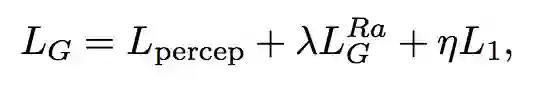
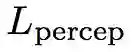
即为上面定义的生成器损失,而 L1 则为 pixel-wise 损失,即
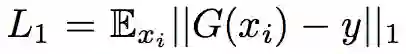
对于判别器,其损失函数就是上面提到的:
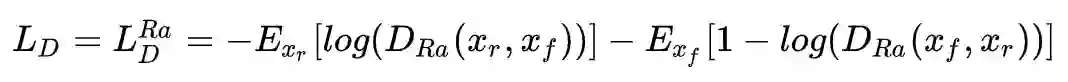
网络细节
生成器网络G
要定义 RDDB 模块,首先要定义 Dense Block,而 Dense Block 里面又有卷积层,LReLU 层以及密集连接,所以首先将卷积层和 LReLU 层进行模块化,这部分的代码如下(PyTorch):
def conv_block(in_nc, out_nc, kernel_size, stride=1, dilation=1, groups=1, bias=True, \
pad_type='zero', norm_type=None, act_type='relu', mode='CNA'):
'''
Conv layer with padding, normalization, activation
mode: CNA --> Conv -> Norm -> Act
NAC --> Norm -> Act --> Conv (Identity Mappings in Deep Residual Networks, ECCV16)
'''
assert mode in ['CNA', 'NAC', 'CNAC'], 'Wong conv mode [{:s}]'.format(mode)
padding = get_valid_padding(kernel_size, dilation)
p = pad(pad_type, padding) if pad_type and pad_type != 'zero' else None
padding = padding if pad_type == 'zero' else 0
c = nn.Conv2d(in_nc, out_nc, kernel_size=kernel_size, stride=stride, padding=padding, \
dilation=dilation, bias=bias, groups=groups)
a = act(act_type) if act_type else None
if 'CNA' in mode:
n = norm(norm_type, out_nc) if norm_type else None
return sequential(p, c, n, a)
elif mode == 'NAC':
if norm_type is None and act_type is not None:
a = act(act_type, inplace=False)
# Important!
# input----ReLU(inplace)----Conv--+----output
# |________________________|
# inplace ReLU will modify the input, therefore wrong output
n = norm(norm_type, in_nc) if norm_type else None
return sequential(n, a, p, c)
注意这里的 pad_type='zero' 并不是指 padding=0,源码中定义了两个函数,针对不同模式下的 padding:
def pad(pad_type, padding):
# helper selecting padding layer
# if padding is 'zero', do by conv layers
pad_type = pad_type.lower()
if padding == 0:
return None
if pad_type == 'reflect':
layer = nn.ReflectionPad2d(padding)
elif pad_type == 'replicate':
layer = nn.ReplicationPad2d(padding)
else:
raise NotImplementedError('padding layer [{:s}] is not implemented'.format(pad_type))
return layer
def get_valid_padding(kernel_size, dilation):
kernel_size = kernel_size + (kernel_size - 1) * (dilation - 1)
padding = (kernel_size - 1) // 2
return padding
所以当 pad_type='zero' 时,执行的是 get_valid_padding 函数,根据输入参数可知此时 padding=1。
模块化以后,对 Dense Block 进行定义:
class ResidualDenseBlock_5C(nn.Module):
'''
Residual Dense Block
style: 5 convs
The core module of paper: (Residual Dense Network for Image Super-Resolution, CVPR 18)
'''
def __init__(self, nc, kernel_size=3, gc=32, stride=1, bias=True, pad_type='zero', \
norm_type=None, act_type='leakyrelu', mode='CNA'):
super(ResidualDenseBlock_5C, self).__init__()
# gc: growth channel, i.e. intermediate channels
self.conv1 = conv_block(nc, gc, kernel_size, stride, bias=bias, pad_type=pad_type, \
norm_type=norm_type, act_type=act_type, mode=mode)
self.conv2 = conv_block(nc+gc, gc, kernel_size, stride, bias=bias, pad_type=pad_type, \
norm_type=norm_type, act_type=act_type, mode=mode)
self.conv3 = conv_block(nc+2*gc, gc, kernel_size, stride, bias=bias, pad_type=pad_type, \
norm_type=norm_type, act_type=act_type, mode=mode)
self.conv4 = conv_block(nc+3*gc, gc, kernel_size, stride, bias=bias, pad_type=pad_type, \
norm_type=norm_type, act_type=act_type, mode=mode)
if mode == 'CNA':
last_act = None
else:
last_act = act_type
self.conv5 = conv_block(nc+4*gc, nc, 3, stride, bias=bias, pad_type=pad_type, \
norm_type=norm_type, act_type=last_act, mode=mode)
def forward(self, x):
x1 = self.conv1(x)
x2 = self.conv2(torch.cat((x, x1), 1))
x3 = self.conv3(torch.cat((x, x1, x2), 1))
x4 = self.conv4(torch.cat((x, x1, x2, x3), 1))
x5 = self.conv5(torch.cat((x, x1, x2, x3, x4), 1))
return x5.mul(0.2) + x
前面提到的对残差信息进行 scaling,在这里可以看出来,系数为 0.2。可以看到在 kernel size(3×3)和 stride=1,padding=1 的设置下,特征图的大小始终不变,但是通道数由于 concat 的原因,每次都会增加 gc 个通道,但是会在最后一层由变回原来的通道数 nc,这里的参数 norm_type=None,表示不要 Batch Norm。
定义了 Dense Block 以后,就可以组成 RDDB 了:
class RRDB(nn.Module):
'''
Residual in Residual Dense Block
(ESRGAN: Enhanced Super-Resolution Generative Adversarial Networks)
'''
def __init__(self, nc, kernel_size=3, gc=32, stride=1, bias=True, pad_type='zero', \
norm_type=None, act_type='leakyrelu', mode='CNA'):
super(RRDB, self).__init__()
self.RDB1 = ResidualDenseBlock_5C(nc, kernel_size, gc, stride, bias, pad_type, \
norm_type, act_type, mode)
self.RDB2 = ResidualDenseBlock_5C(nc, kernel_size, gc, stride, bias, pad_type, \
norm_type, act_type, mode)
self.RDB3 = ResidualDenseBlock_5C(nc, kernel_size, gc, stride, bias, pad_type, \
norm_type, act_type, mode)
def forward(self, x):
out = self.RDB1(x)
out = self.RDB2(out)
out = self.RDB3(out)
return out.mul(0.2) + x
因为特征图大小始终不变,所以需要定义上采样模块进行放大,得到最后的结果:
def upconv_blcok(in_nc, out_nc, upscale_factor=2, kernel_size=3, stride=1, bias=True, \
pad_type='zero', norm_type=None, act_type='relu', mode='nearest'):
# Up conv
# described in https://distill.pub/2016/deconv-checkerboard/
upsample = nn.Upsample(scale_factor=upscale_factor, mode=mode)
conv = conv_block(in_nc, out_nc, kernel_size, stride, bias=bias, \
pad_type=pad_type, norm_type=norm_type, act_type=act_type)
return sequential(upsample, conv)
参考 SRResNet,还需要一个 Shortcut 连接模块:
class ShortcutBlock(nn.Module):
#Elementwise sum the output of a submodule to its input
def __init__(self, submodule):
super(ShortcutBlock, self).__init__()
self.sub = submodule
def forward(self, x):
output = x + self.sub(x)
return output
def __repr__(self):
tmpstr = 'Identity + \n|'
modstr = self.sub.__repr__().replace('\n', '\n|')
tmpstr = tmpstr + modstr
return tmpstr
定义好上面的模块以后,就可以定义生成器网络 G(RDDBNet):
class RRDBNet(nn.Module):
def __init__(self, in_nc, out_nc, nf, nb, gc=32, upscale=4, norm_type=None, \
act_type='leakyrelu', mode='CNA', upsample_mode='upconv'):
super(RRDBNet, self).__init__()
n_upscale = int(math.log(upscale, 2))
if upscale == 3:
n_upscale = 1
fea_conv = B.conv_block(in_nc, nf, kernel_size=3, norm_type=None, act_type=None)
rb_blocks = [B.RRDB(nf, kernel_size=3, gc=32, stride=1, bias=True, pad_type='zero', \
norm_type=norm_type, act_type=act_type, mode='CNA') for _ in range(nb)]
LR_conv = B.conv_block(nf, nf, kernel_size=3, norm_type=norm_type, act_type=None, mode=mode)
if upsample_mode == 'upconv':
upsample_block = B.upconv_blcok
elif upsample_mode == 'pixelshuffle':
upsample_block = B.pixelshuffle_block
else:
raise NotImplementedError('upsample mode [{:s}] is not found'.format(upsample_mode))
if upscale == 3:
upsampler = upsample_block(nf, nf, 3, act_type=act_type)
else:
upsampler = [upsample_block(nf, nf, act_type=act_type) for _ in range(n_upscale)]
HR_conv0 = B.conv_block(nf, nf, kernel_size=3, norm_type=None, act_type=act_type)
HR_conv1 = B.conv_block(nf, out_nc, kernel_size=3, norm_type=None, act_type=None)
self.model = B.sequential(fea_conv, B.ShortcutBlock(B.sequential(*rb_blocks, LR_conv)),\
*upsampler, HR_conv0, HR_conv1)
def forward(self, x):
x = self.model(x)
return x
注意到这里有个参数 nb,这个参数控制网络中 RDDB 的数量,作者取的是 23。
判别器网络D
前面提到,判别器 D 的网络结构为 VGG 网络,定义如下(输入图像 size 为 128×128):
# VGG style Discriminator with input size 128*128
class Discriminator_VGG_128(nn.Module):
def __init__(self, in_nc, base_nf, norm_type='batch', act_type='leakyrelu', mode='CNA'):
super(Discriminator_VGG_128, self).__init__()
# features
# hxw, c
# 128, 64
conv0 = B.conv_block(in_nc, base_nf, kernel_size=3, norm_type=None, act_type=act_type, \
mode=mode)
conv1 = B.conv_block(base_nf, base_nf, kernel_size=4, stride=2, norm_type=norm_type, \
act_type=act_type, mode=mode)
# 64, 64
conv2 = B.conv_block(base_nf, base_nf*2, kernel_size=3, stride=1, norm_type=norm_type, \
act_type=act_type, mode=mode)
conv3 = B.conv_block(base_nf*2, base_nf*2, kernel_size=4, stride=2, norm_type=norm_type, \
act_type=act_type, mode=mode)
# 32, 128
conv4 = B.conv_block(base_nf*2, base_nf*4, kernel_size=3, stride=1, norm_type=norm_type, \
act_type=act_type, mode=mode)
conv5 = B.conv_block(base_nf*4, base_nf*4, kernel_size=4, stride=2, norm_type=norm_type, \
act_type=act_type, mode=mode)
# 16, 256
conv6 = B.conv_block(base_nf*4, base_nf*8, kernel_size=3, stride=1, norm_type=norm_type, \
act_type=act_type, mode=mode)
conv7 = B.conv_block(base_nf*8, base_nf*8, kernel_size=4, stride=2, norm_type=norm_type, \
act_type=act_type, mode=mode)
# 8, 512
conv8 = B.conv_block(base_nf*8, base_nf*8, kernel_size=3, stride=1, norm_type=norm_type, \
act_type=act_type, mode=mode)
conv9 = B.conv_block(base_nf*8, base_nf*8, kernel_size=4, stride=2, norm_type=norm_type, \
act_type=act_type, mode=mode)
# 4, 512
self.features = B.sequential(conv0, conv1, conv2, conv3, conv4, conv5, conv6, conv7, conv8,\
conv9)
# classifier
self.classifier = nn.Sequential(
nn.Linear(512 * 4 * 4, 100), nn.LeakyReLU(0.2, True), nn.Linear(100, 1))
def forward(self, x):
x = self.features(x)
x = x.view(x.size(0), -1)
x = self.classifier(x)
return x
可以看到,这里使用了 batch norm,层间的激活函数为 leakyReLU,base_nf参数为基础通道数,为 64。经过特征提取以后,原本为 128×128×1(/3) 的输入图像输出为 4×4×512。再经过其定义的 classifier 得到输出值。
提取感知域损失的网络(Perceptual Network)
文章使用了一个用于材料识别的 VGG16 网络(MINCNet)来提取感知域特征,定义如下:
class MINCNet(nn.Module):
def __init__(self):
super(MINCNet, self).__init__()
self.ReLU = nn.ReLU(True)
self.conv11 = nn.Conv2d(3, 64, 3, 1, 1)
self.conv12 = nn.Conv2d(64, 64, 3, 1, 1)
self.maxpool1 = nn.MaxPool2d(2, stride=2, padding=0, ceil_mode=True)
self.conv21 = nn.Conv2d(64, 128, 3, 1, 1)
self.conv22 = nn.Conv2d(128, 128, 3, 1, 1)
self.maxpool2 = nn.MaxPool2d(2, stride=2, padding=0, ceil_mode=True)
self.conv31 = nn.Conv2d(128, 256, 3, 1, 1)
self.conv32 = nn.Conv2d(256, 256, 3, 1, 1)
self.conv33 = nn.Conv2d(256, 256, 3, 1, 1)
self.maxpool3 = nn.MaxPool2d(2, stride=2, padding=0, ceil_mode=True)
self.conv41 = nn.Conv2d(256, 512, 3, 1, 1)
self.conv42 = nn.Conv2d(512, 512, 3, 1, 1)
self.conv43 = nn.Conv2d(512, 512, 3, 1, 1)
self.maxpool4 = nn.MaxPool2d(2, stride=2, padding=0, ceil_mode=True)
self.conv51 = nn.Conv2d(512, 512, 3, 1, 1)
self.conv52 = nn.Conv2d(512, 512, 3, 1, 1)
self.conv53 = nn.Conv2d(512, 512, 3, 1, 1)
def forward(self, x):
out = self.ReLU(self.conv11(x))
out = self.ReLU(self.conv12(out))
out = self.maxpool1(out)
out = self.ReLU(self.conv21(out))
out = self.ReLU(self.conv22(out))
out = self.maxpool2(out)
out = self.ReLU(self.conv31(out))
out = self.ReLU(self.conv32(out))
out = self.ReLU(self.conv33(out))
out = self.maxpool3(out)
out = self.ReLU(self.conv41(out))
out = self.ReLU(self.conv42(out))
out = self.ReLU(self.conv43(out))
out = self.maxpool4(out)
out = self.ReLU(self.conv51(out))
out = self.ReLU(self.conv52(out))
out = self.conv53(out)
return out
再引入预训练参数,就可以进行特征提取:
class MINCFeatureExtractor(nn.Module):
def __init__(self, feature_layer=34, use_bn=False, use_input_norm=True, \
device=torch.device('cpu')):
super(MINCFeatureExtractor, self).__init__()
self.features = MINCNet()
self.features.load_state_dict(
torch.load('../experiments/pretrained_models/VGG16minc_53.pth'), strict=True)
self.features.eval()
# No need to BP to variable
for k, v in self.features.named_parameters():
v.requires_grad = False
def forward(self, x):
output = self.features(x)
return output
网络插值思想
为了平衡感知质量和 PSNR 等评价值,作者提出了一个灵活且有效的方法——网络插值。具体而言,作者首先基于 PSNR 方法训练的得到的网络 G_PSNR,然后再用基于 GAN 的网络 G_GAN 进行 finetune。
然后,对这两个网络相应的网络参数进行插值得到一个插值后的网络 G_INTERP:
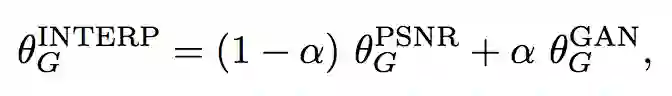
这样就可以通过 α 值来调整效果。
训练细节
放大倍数:4;mini-batch:16。
通过 Matlab 的 bicubic 函数对 HR 图像进行降采样得到 LR 图像。
HR patch 大小:128×128。实验发现使用大的 patch 时,训练一个深层网络效果会更好,因为一个增大的感受域会帮助模型捕捉更具有语义的信息。
训练过程如下:
1. 训练一个基于 PSNR 指标的模型(L1 Loss),初始化学习率:2×1e-4,每 200000 个 mini-batch 学习率除以 2;
2. 以 1 中训练的模型作为生成器的初始化。
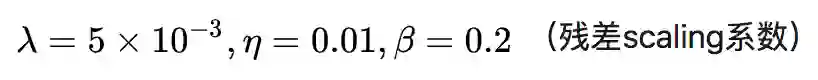
初始学习率:1e-4,并在 50k,100k,200k,300k 迭代后减半。
一个基于像素损失函数进行优化的预训练模型会帮助基于 GAN 的模型生成更符合视觉的结果,原因如下:
1. 可以避免生成器不希望的局部最优;
2. 再预训练以后,判别器所得到的输入图像的质量是相对较好的,而不是完全初始化的图像,这样会使判别器更关注到纹理的判别。
优化器:Adam (β1=0.9, β2=0.999);交替更新生成器和判别器,直到收敛。
生成器的设置:1.16 层(基本的残差结构);2.23层(RDDB)。
数据集:DIV2K,Flickr2K,OST(有丰富纹理信息的数据集会是模型产生更自然的结果)。
对比实验(4倍放大)
针对文中提到的各种改进,包括移除 BN,使用激活前特征作为感知域特征,修改 GAN 的判别条件,以及提出的 RDDB,作者做了详细的对比试验,结果如下:
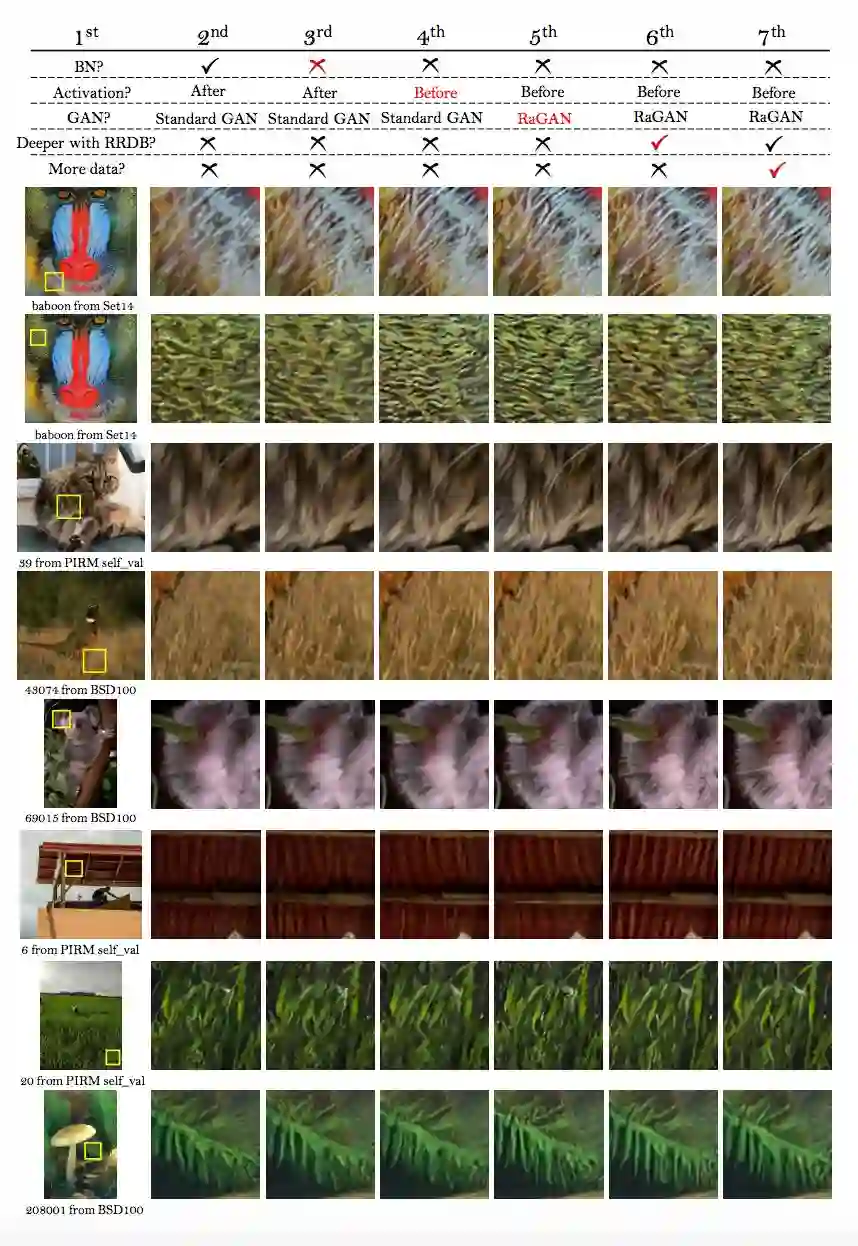
经过实验以后,作者得出结论:
1. 去掉 BN:并没有降低网络的性能,而且节省了计算资源和内存占用。而且发现当网络变深变复杂时,带 BN 层的模型更倾向于产生影响视觉效果的伪影;
2. 使用激活前的特征:得到的图像的亮度更准确,而且可以产生更尖锐的边缘和更丰富的细节;
3. RaGAN:产生更尖锐的边缘和更丰富的细节;
4. RDDB:更加提升恢复得到的纹理(因为深度模型具有强大的表示能力来捕获语义信息),而且可以去除噪声。
网络插值实验
为了平衡视觉效果和 PSNR 等性能指标,作者对网络插值参数 α 的取值进行了实验,结果如下:

此外,作者还对比了网络插值和图像插值的效果。图像插值即指分别由两个网络输出的图像进行插值。通过对比实验可以看到,图像插值对消除伪影的效果不如网络插值。
与SOTA方法对比(4倍放大)

可以看到,ESRGAN 得到的图像 PSNR 值不高,但是从视觉效果上看会更好,Percpetual Index 值更小(越小越好),而且 ESRGAN 在 PIRM-SR 竞赛上也获得了第一名(在 Percpetual Index 指标上)。
总结
文章提出的 ESRGAN 在 SRGAN 的基础上做出了改进,包括去除 BN 层,基本结构换成 RDDB,改进 GAN 中判别器的判别目标,以及使用激活前的特征构成感知域损失函数,实验证明这些改进对提升输出图像的视觉效果都有作用。
此外,作者也使用了一些技巧来提升网络的性能,包括对残差信息的 scaling,以及更小的初始化。最后,作者使用了一种网络插值的方法来平衡输出图像的视觉效果和 PSNR 等指标值。

请为PaperWeekly打call!
PaperWeekly 曾于 2016 年入选“年度十大学术公众号”(2016年度学术公众号TOP10重磅发布),并连续入围“2017 年度学术公众号”评选。
如果您喜欢 PaperWeekly,请在本文底部点击“阅读原文”-勾选“PaperWeekly”,为我们投上您宝贵的一票。

🔍
现在,在「知乎」也能找到我们了
进入知乎首页搜索「PaperWeekly」
点击「关注」订阅我们的专栏吧
关于PaperWeekly
PaperWeekly 是一个推荐、解读、讨论、报道人工智能前沿论文成果的学术平台。如果你研究或从事 AI 领域,欢迎在公众号后台点击「交流群」,小助手将把你带入 PaperWeekly 的交流群里。

点击“阅读原文”,为“PaperWeekly”投票!

