
今天给大家推荐美国陆军研究实验室最新发布的“COA-GPT:军事作战中加速行动方案(COA)制定的生成式预训练Transformer”一文。文中引入了 COA-GPT,这是一种采用大型语言模型 (LLM) 的新型算法,可快速高效地生成有效的 COA。研究结果表明,COA-GPT 在更迅速地生成战略上合理的 COA 方面具有优势,同时还具有增强适应性和与指挥官意图保持一致的额外优势。

军事作战中行动方案(COA)的制定历来是一个耗时且复杂的过程。为应对这一挑战,本研究引入了 COA-GPT,这是一种采用大型语言模型 (LLM) 的新型算法,可快速高效地生成有效的 COA。COA-GPT 通过上下文学习将军事条令和领域专业知识融入 LLM,让指挥员可以输入任务式指挥信息(文本和图像格式),并接收与战略相匹配的 COA 供审查和批准。与众不同的是,COA-GPT 不仅能加快 COA 开发速度,在数秒内生成初始 COA,还能根据指挥官的反馈进行实时改进。这项工作在军事化版本的《星际争霸 II》游戏中的军事相关场景中评估了 COA-GPT,并将其性能与最先进的强化学习算法进行了比较。研究结果表明,COA-GPT 在更迅速地生成战略上合理的 COA 方面具有优势,同时还具有增强适应性和与指挥官意图保持一致的额外优势。COA-GPT 在任务期间快速调整和更新 COA 的能力为军事规划带来了变革潜力,特别是在解决规划差异和利用突发机会窗口方面。
一、引言
未来战场对指挥与控制(C2)人员提出了一系列复杂多变的挑战,需要在多方面领域做出快速、明智的决策。随着战争的不断发展,整合和同步空中、陆地、海上、信息、网络和太空领域的各种资产和效果变得越来越重要。包括计划、准备、执行和持续评估在内的 C2 行动流程必须适应这些复杂性,同时还要处理实时数据集成以及在拒绝、降级、间歇和有限(DDIL)通信条件下的行动。
在这种高风险环境下,保持决策优势--比对手更快做出及时有效决策的能力--至关重要。军事决策流程(MDMP)是 C2 规划的基石,随着现代战争[5]步伐的加快和复杂性的增加,MDMP 面临着不断发展的迫切需要。这就要求在越来越短的时间内执行 MDMP,以利用稍纵即逝的机会,并对战场的动态条件做出适应性反应。
行动方案(COA)的制定是决策过程的基础,它体现了这些挑战。制定行动方案历来是一个细致而耗时的过程,在很大程度上依赖于军事人员的经验和专业知识。然而,现代战争的快速发展需要更高效的方法来开发和分析 COA。
大型语言模型(LLM)是自然语言处理领域的一项变革性技术。LLM 通过处理大量数据,从给定的提示中生成类似人类的文本,在包括灾难响应和机器人技术在内的各种应用中展现了巨大的潜力。本研究论文提出了 COA-GPT,这是一个探索应用 LLM 的框架,通过上下文学习加速军事行动中的 COA 开发。
COA-GPT 利用 LLMs 快速开发有效的 COA,将军事条令和领域专业知识直接整合到系统的初始提示中。指挥员可以输入任务的具体内容和部队描述(文本和图像格式),在几秒钟内就能收到多个战略上一致的作战行动指令。这一突破大大缩短了 COA 的开发时间,促进了更敏捷的决策过程。它使指挥官能够快速迭代和完善作战行动方案,跟上战场上不断变化的情况,并保持对对手的战略优势。
主要贡献有
- COA-GPT 是一种利用 LLMs 加速 COA 开发和分析的新型框架,有效地整合了军事条令和领域专业知识。
- 经验证据表明,COA-GPT 生成 COA 的速度和与军事战略目标的一致性均优于现有基线。
- 证明 COA-GPT 能够通过人机交互改进 COA 开发,确保生成的 COA 与指挥官的意图密切吻合,并能动态适应战场场景。
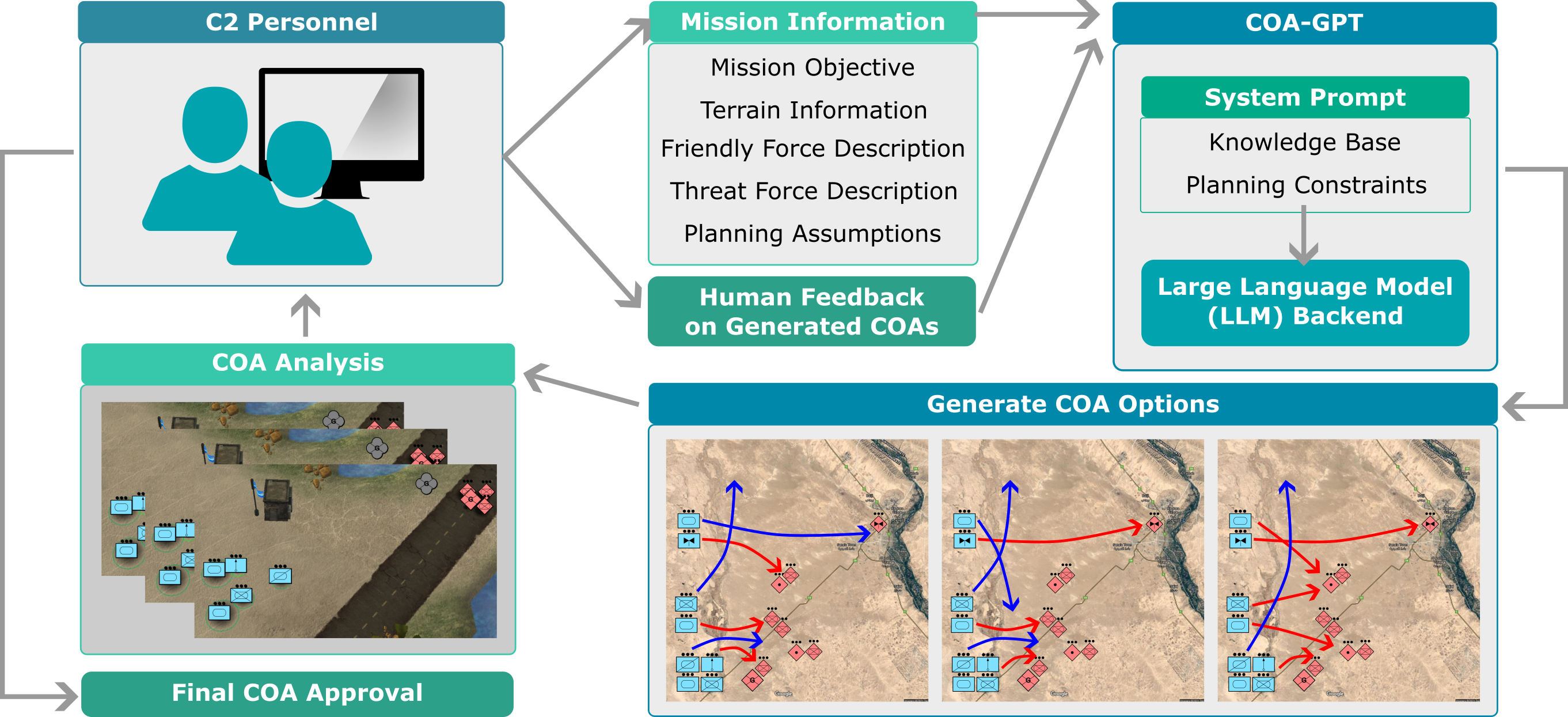
图 1:COA-GPT 拟议方法概述。COA-GPT 包括一个大型语言模型 (LLM),该模型通过上下文学习进行学习,在 COA 开发过程中,该模型最初会被提示一个知识库和需要遵守的其他约束条件。指挥和控制人员提供任务式信息,COA-GPT 利用这些信息生成 COA 选项,并通过自然语言与人类反复交互,直到选出最终的 COA。
二、军事相关性
当前军事行动中的 C2 流程主要是线性的,涉及许多连续的步骤,在现代战争的快节奏环境中显得繁琐而缓慢。人工智能在军事规划中的应用,尤其是 COA-GPT 系统的出现,为从根本上简化这些流程提供了机会。COA-GPT 能够快速生成、分析和完善多个 COA,从而改变传统的 C2 行动,将多个规划步骤结合起来并同时执行,以优化效率。
有了 COA-GPT,MDMP 可以得到显著增强。COA-GPT 可同时开发和分析 COA,从而促进更快的决策和更有效的行动控制。这样就能更快地生成可操作的情报,从而使指挥官能迅速做出更明智的决策。将 COA-GPT 等基于人工智能的工具集成到 C2 流程中,可以减少军事行动的实际足迹,降低对大量人员和后勤支持的需求,支持分布式指挥所的愿景。
拟议的 COA-GPT 系统可快速生成、分析和比较多个 COA 备选方案,从而有可能彻底改变 C2 行动。该系统可与战争游戏模拟器集成,实时处理来自战场传感器的数据,为指挥官提供快速适应动态战场环境的能力。这一愿景与文献[5]中提出的观点不谋而合,后者强调在开发阶段整合 COA 分析,以快速优化和比较多个 COA。然而,COA-GPT 利用人类专业技能和人工智能的综合优势,在整个 C2 流程中促进创造力、探索和知情决策,从而扩展了这一概念。
COA-GPT 的设计目的是使用语言和注释地图,以直观的方式向人员展示 COA,促进对 COA 备选方案的分析,并允许 C2 人员利用其领域专长和态势感知调整人工智能生成的 COA,最终就最终 COA 选择做出明智的决策。
在实际操作中,C2 人员将与 COA-GPT 进行动态交互,以修改建议的 COA。他们可以指定目标、输入文本和图像格式的数据、发布修正以微调计划,以及设置限制以避免不良行动。针对不可预见的变化,可向 COA-GPT 转达反馈意见,使计划适应新的风险和机遇。人员还可以调整 COA 选择标准,以平衡多个目标,例如优先控制敌方资产或尽量减少对部队的危险。这种互动过程可确保最终选择的 COA 符合指挥官的战略意图和形势要求。
三、相关工作
3.1 使用大型语言模型进行规划
将大型语言模型(LLM)整合到行动计划制定中,正在给包括灾害管理和军事行动在内的各个领域带来革命性的变化。在灾难响应领域,DisasterResponseGPT算法脱颖而出。该算法利用 LLM 的功能快速生成可行的行动计划,并在初始提示中整合了基本的灾难响应指南。与提议的 COA-GPT 类似,DisasterResponseGPT 也能根据用户输入的场景快速生成多个计划,从而大大缩短响应时间,并能根据持续反馈实时调整计划。这种方法与 COA-GPT 的目标相似,但还没有证明它能在 COA 生成过程中结合 COA 分析和空间信息。
与军事行动类似,灾难响应要求在严重的时间限制和高压条件下做出快速、明智的决策。传统上,在这种情况下制定行动计划是一个费力的过程,严重依赖相关人员的经验和专业知识。鉴于其中的利害关系,延误可能导致生命损失,因此亟需更高效、更可靠的计划制定方法。COA-GPT 解决了军事行动中的类似挑战,为 COA 生成和分析提供了一种快速、适应性强的方法。
Ahn 等人(2022 年)和 Mees 等人(2023 年)最近的研究扩大了 LLM 的应用范围,将机器人和视觉能力纳入其中,说明了 LLM 如何立足于现实世界。这些发展对于缩小高级语义知识与动态环境中可执行的实际行动之间的差距至关重要。同样,COA-GPT 试图将 LLMs 应用于军事环境,将抽象的战略概念和战场信息转化为具体的、可执行的军事计划。
为了继续展示 LLMs 在规划方面的潜力,Wang 等人(2023 年)在 Minecraft 中引入了 Voyager,这是一个由 LLM 驱动的体现式终身学习智能体,代表着在复杂多变的环境中自主、持续学习和获取技能方面迈出了开创性的一步。同样,STEVE-1模型利用文本条件图像生成和决策算法的进步,展示了 LLM 在虚拟环境中指导智能体遵循复杂指令的潜力。这些模型所展示的适应性和学习能力正是 COA-GPT 可用于实时生成和完善军事场景中 COA 的特质。
3.2 人工智能在军事规划和作战中的应用
人工智能和 LLM 在军事规划和作战中的应用是一个日益受到关注且潜力巨大的领域。ARL主任战略倡议的第一年报告重点关注人工智能在多域行动指挥与控制 (C2) 中的应用,该报告体现了这一趋势。报告讨论了正在进行的研究,即深度强化学习(DRL)是否能支持多域部队的敏捷和自适应 C2。这对于旨在利用战场上迅速变化的局势和稍纵即逝的优势窗口的指挥官和参谋人员来说尤为重要。COA-GPT 体现了这一敏捷性和适应性概念,利用 LLM 快速制定和修改 COA,以应对不断变化的战场条件。这种方法有效地克服了 DRL 方法固有的脆性和大量的训练需求。
Goecks 等人(2023 年)在探索游戏平台与军事训练之间的协同作用时,深入探讨了人工智能算法如何与游戏和模拟技术相结合,以复制军事任务的各个方面。同样,COA-GPT 也可被视为这一趋势的一部分,它利用 LLMs 加强军事行动的战略规划阶段,并利用游戏和模拟技术对其进行评估。
同样,Waytowich 等人(2022 年)以《星际争霸 II》中的军事场景为模型,展示了 DRL 在模拟指挥与控制任务中指挥多个异构行动者方面的应用。他们的研究结果表明,通过自动生成的课程训练出来的智能体,其表现可以媲美甚至超越人类专家和最先进的 DRL 基线。这种在复杂场景中训练人工智能系统的方法与 COA-GPT 的目标一致,即在生成军事 COA 时将人类的专业知识与人工智能的效率结合起来。
除了这些发展,Schwartz(2020)还深入研究了人工智能在陆军 MDMP 中的应用,特别是在 COA 分析阶段。这项研究与 COA-GPT 尤为相关,因为它展示了人工智能如何帮助指挥官及其参谋人员快速制定和优化多种行动方案,以应对现代战场的复杂性和高度竞争性。该研究还强调了多域作战(MDO)日益增加的重要性,以及装备有先进反介入区域拒止(A2AD)能力的近邻对手所带来的挑战。COA-GPT 与这一愿景不谋而合,它提供了一种增强 MDMP 的工具,特别是在快速生成和分析 COA 方面。
与这些人工智能驱动的方法不同,美国陆军 ATP 5-0.2中概述的传统军事规划流程涉及大规模作战行动中参谋人员的综合指南。虽然这些传统方法提供了关键规划工具和技术的综合来源,但往往缺乏现代人工智能系统在快速变化的作战环境中提供的灵活性和适应性。COA-GPT 代表了这些传统方法的范式转变,为军事规划流程带来了 LLM 的速度和灵活性。
四、研究方法
这项研究利用 LLM 的场景学习功能创建了 COA-GPT,这是一个旨在为军事行动高效生成 COA 的虚拟助手。
COA-GPT 被提示要了解自己是军事指挥官的助手,帮助 C2 人员制定 COA。它知道自己的输入将包括任务式指挥提供的任务目标、地形信息以及友军和威胁部队的详细情况,这些信息以文本和/或图像格式提供。此外,COA-GPT 还可获取浓缩版的军事条令,内容包括机动形式(包围、侧翼攻击、正面攻击、渗透、穿透和转向运动)、进攻任务(运动接触、攻击、利用和追击)和防御任务(区域防御、机动防御和后退)。
如图 1 所示,COA-GPT 助手通过自然语言与 C2 人员通信。它接收与任务相关的信息,如目标、地形细节、友军和威胁部队的描述和安排,以及 C2 人员可能有的任何计划假设。对于后备的 LLM,我们使用 OpenAI 的 GPT-4-Turbo(在其 API 中名为 "gpt-4-1106-preview")进行纯文本实验,并使用 GPT-4-Vision(名为 "gpt-4-vision-preview")进行任务信息同时以文本和图像格式提供的任务。
收到这些信息后,COA-GPT 会生成多个 COA 选项,每个选项都有指定的名称、目的和拟议行动的可视化表示。用户可以选择自己喜欢的 COA,并通过文本建议对其进行完善。COA-GPT 会处理这些反馈,对选定的 COA 进行微调。一旦指挥官批准了最终的 COA,COA-GPT 就会进行分析并提供性能指标。
COA-GPT 生成 COA 的速度非常快,几秒钟就能完成。包括与指挥官互动的时间在内,只需几分钟就能生成最终 COA。这种效率突出表明,COA-GPT 有潜力改变军事行动中的 COA 开发,促进针对计划阶段的差异或新出现的机会进行快速调整。
五、实验
5.1 场景和实验设置
在 "虎爪行动"(Operation TigerClaw)场景中对所提出的方法进行了评估,该场景是作为《星际争霸 II》学习环境(PySC2)中的自定义地图实现的。该平台可让人工智能(AI)体参与《星际争霸 II》游戏。"虎爪行动"展示了一个战斗场景,其中 1-12 CAV 特遣部队的任务是通过穿越塔尔塔尔谷发动攻击,消灭威胁部队,从而夺取 OBJ Lion。该目标如图 2 所示。
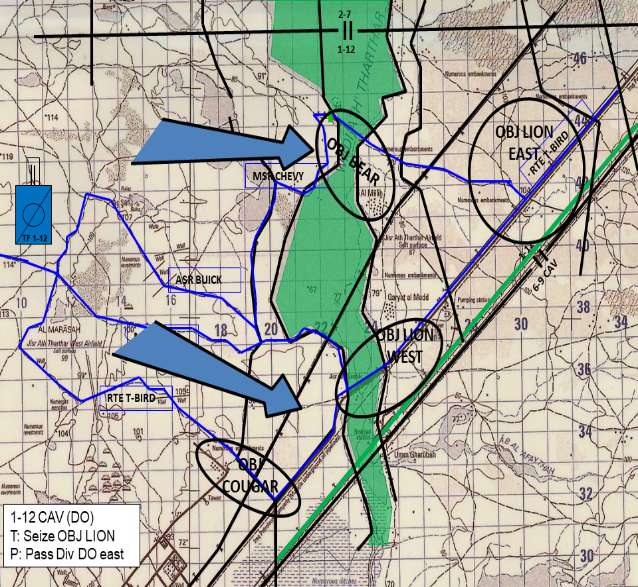
图 2:TF 1-12 CAV 在虎爪行动区的作战区域。
在 PySC2 中,通过将《星际争霸 II》中的单元映射到其军事等同物,调整武器射程、伤害、单元速度和健康状况等属性,实现了这一场景。例如,M1A2 艾布拉姆斯战斗装甲单元由坦克模式下的改进型攻城坦克(Siege Tanks)表示,机械化步兵由 "地狱犬"(Hellions)表示,等等。友军包括 9 个装甲单元、3 个机械化步兵单元、1 个迫击炮单元、2 个航空单元和 1 个侦察单元。威胁部队包括 12 个机械化步兵、1 个航空兵、2 个炮兵、1 个反装甲兵和 1 个步兵单元。如图 3 所示,一张专门设计的《星际争霸 II》地图[24] 描述了 "虎爪 "行动区。
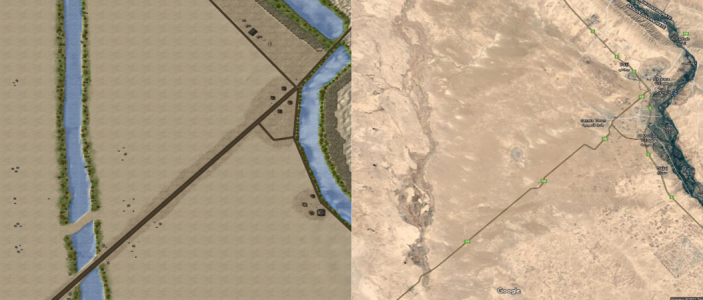
图 3:行动区卫星图(右)及其在《星际争霸 II》中的表现(左)。
5.2 COA生成
COA-GPT 以文本格式处理所有实验场景的任务目标和地形信息,具体描述如下:
- 任务目标。"通过多座桥梁将友军从河西移动到河东,消灭所有敌对势力,并最终夺取地图右上角的目标 OBJ Lion East(坐标 x:200,y:89)"。
- 地形信息。"地图被一条贯穿南北的河流分成两大部分(西侧和东侧)。有四座桥可以用来横跨这条河。桥梁名称和出口坐标如下: 1) 桥山猫(x: 75,y: 26),2) 桥狼(x: 76,y: 128),3) 桥熊(x:81,y: 179),4) 桥狮(x: 82,y: 211)"。
此外,在使用具有图像处理功能的 LLM 的实验中,COA-GPT 将共同作战图像 (COP) 的一帧作为输入,该图像在地形的卫星图像中叠加了兵力安排,如图 4 所示。
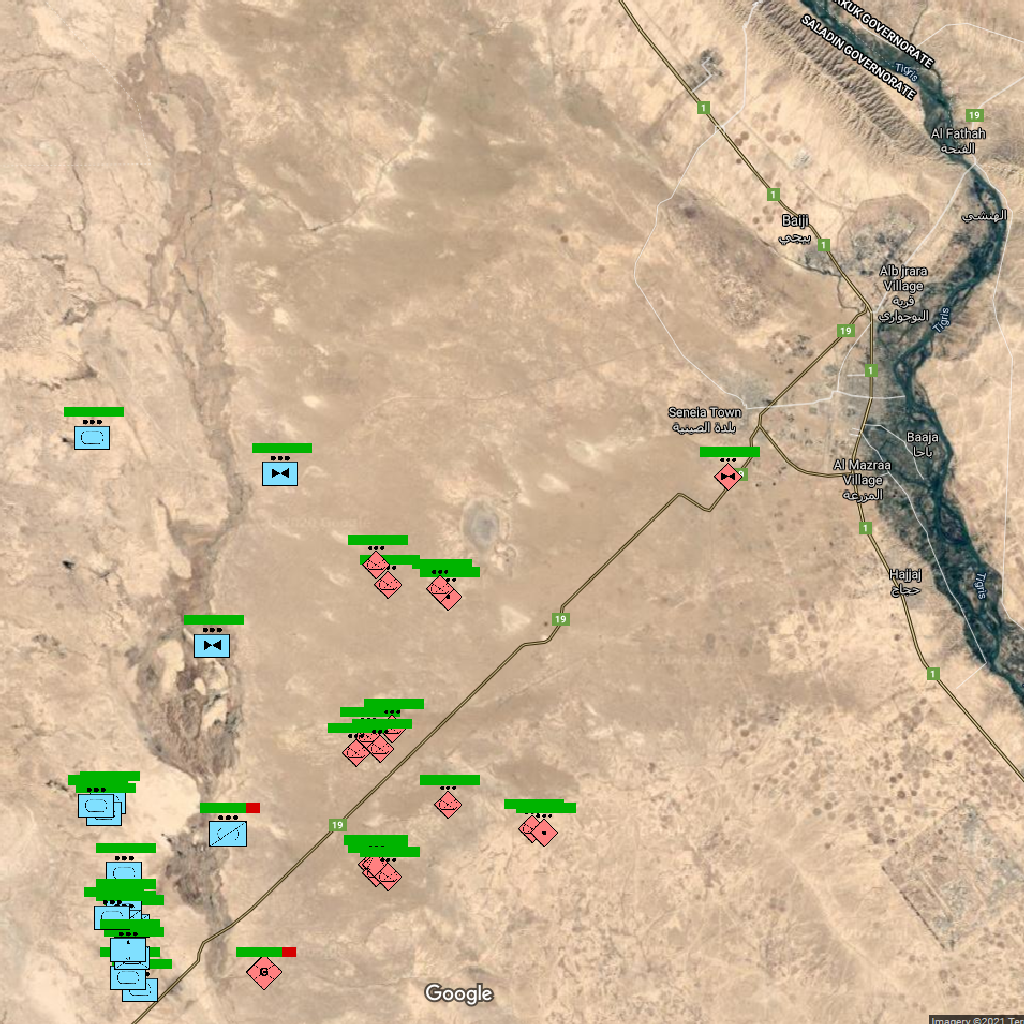
图 4:提供给 COA-GPT 的图像示例,作为具有视觉功能的 LLM 试验任务信息的一部分。该图像叠加了战场地形卫星图像中的兵力安排。
以 JSON 格式向 COA-GPT 提供友军和威胁部队的信息,详细说明场景中存在的所有资产:
- 友军资产示例:"{'unit_id': 4298113025,'unit_type': 'Armor','alliance': 'Friendly','position': 'x': 12.0, 'y': 203.0}"
- 威胁部队资产示例:"{'unit_id': 4294967297,'unit_type':'机械化步兵','alliance':'敌对','position':'x': 99.0, 'y': 143.0}"
此外,COA-GPT 的编程还包含特定游戏引擎功能的知识,用于指挥每种资产,例如
- attack_move_unit(unit_id, target_x, target_y): 指示友军单元移动到指定坐标,与途中遇到的敌军单元交战。
- engate_target_unit(unit_id、target_unit_id、target_x、target_y): 命令友军单元与指定的敌对单元交战。如果目标不在攻击范围内,友军单元将移动到目标位置后再交战。

图 5:COA-GPT 生成的 COA 样本,包括可视化表示、任务名称和战略描述,供人类审查。
为了与 PySC2 游戏引擎集成,COA-GPT 以 JSON 格式生成 COA。这些内容随后会被翻译成 PySC2 引擎可理解的函数调用。一个完整的 COA 包括任务名称、策略描述和针对每个资产的特定指挥。在每次模拟启动时,每个资产在整个游戏过程中都要遵守指定的命令,COA-GPT 只限制在模拟开始时对每个资产发出一条命令。
5.3 人类反馈
如图 5 所示,由我们的系统生成的 COA 会转换成图形格式,并附有简明的任务摘要,以提交给人类评估人员。评估人员可提供文字反馈,COA-GPT 会利用这些反馈来完善并生成新的 COA,供后续反馈轮使用。
为确保对所有生成的 COA 进行一致、公平的比较,我们对人类反馈流程进行了标准化。在每次反馈迭代中,针对包含人类输入的 COA 所提供的具体说明如下:
- 第一次迭代: "确保我方两个航空单元直接与敌方航空单元交战"。
- 第二次迭代: "确保只命令我方侦察兵单元控制桥式山猫(x:75 y:26),我方其他资产(非航空兵)分成两组,并命令其使用 attack_move 命令向敌方两门火炮移动。"
在获得人类评估人员的最终批准后,COA-GPT 开始多次模拟该场景,收集并汇编各种评估指标以供分析。
5.4 评估指标
对生成的特遣队所属装备的评估基于特遣队所属装备分析过程中记录的两个关键指标:总奖励和伤亡数字。这些指标包括
- 总奖励。该指标代表游戏总得分,专为虎爪任务场景定制。它包括战略推进和消灭敌方单元的正奖励,以及撤退和友军单元损失的负奖励。具体来说,智能体每推进一座桥梁,每消灭一个敌方单元,都会获得 +10 分。反之,如果他们从先前通过的桥梁上撤退,以及每损失一个友军单元,就会损失 -10 分。
- 友军伤亡。该指标计算在模拟交战中损失的友军单元数量。它反映了以友军单元损失为单位的作战成本。
- 威胁部队伤亡。该指标跟踪模拟交战中被消灭的敌方(威胁部队)单元的数量,表明作战行动方案在解除对手作战能力方面的有效性。
5.5 基准
在本研究中,将提出的方法与已发表的两种表现最佳的方法进行比较:从单个人类演示中进行自动课程强化学习和强化学习中的异步优势行动者-批评者(A3C)算法。比较包括:
- 自动课程强化学习。该方法利用单个人类示范,通过 A3C 算法为训练强化学习智能体开发量身定制的课程。智能体单独控制每个友好单元,接受来自环境的图像输入或详细说明单元位置的矢量表示。在结果部分,将针对这两种输入模式(分别称为 "Autocurr.-Vec "和 "Autocurr.-Im")对我们的方法进行评估。
- 强化学习。该基线采用 A3C 算法,使用图像或向量表示作为输入。与前一种方法不同的是,它没有为学习智能体设置指导课程。两种输入方案都与我们的方法进行了评估,在结果中分别标记为 "RL-Vec "和 "RL-Im"。
- COA-GPT。这是对提出的方法进行的消融研究,但没有人类反馈。该版本被标记为 "COA-GPT"(纯文本输入)和 "COA-GPT-V"(用于带有视觉模型、文本和图像输入的实验),仅根据 C2 人员提供的初始任务数据生成 COA,无需进一步的人类输入。
- 带人类反馈的 COA-GPT。这是完全实现的方法,将在第四节中概述。除了 C2 人员提供的初始任务信息外,该版本还纳入了人类反馈对 COA 性能的影响。我们评估了第一次迭代反馈后的变化,在结果中标记为 "COA-GPT+H1",第二次迭代后标记为 "COA-GPT+H2"。同样,对于使用具有视觉功能的 LLM 进行的实验,将其标记为 "COA-GPT-V+H1 "和 "COA-GPT-V+H2"。
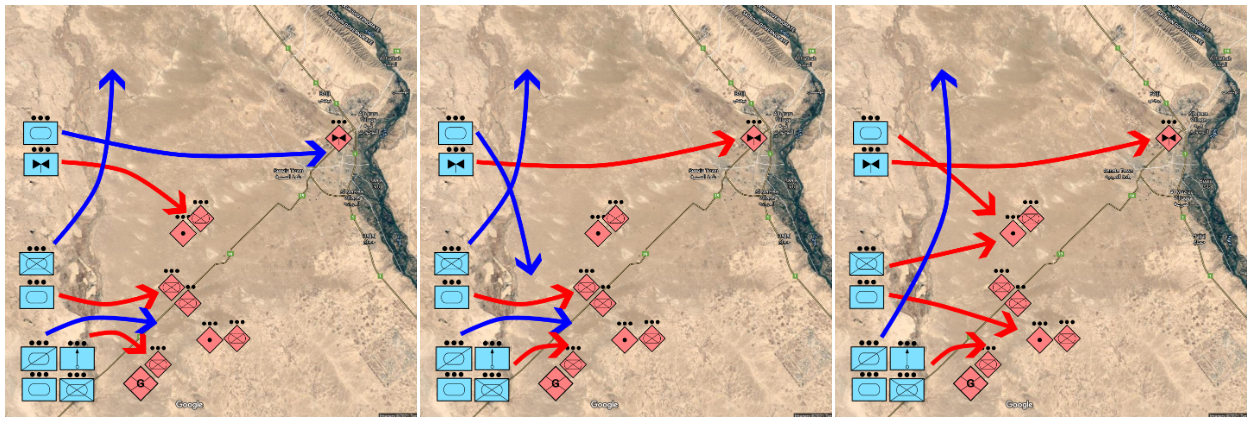
(a) 无人类反馈。(b) 首次人类反馈之后。(c) 第二次人类反馈后。
图 6:说明受人类反馈影响的作战行动的顺序发展。(a) 描述了最初的作战行动,显示了部队通过桥梁的移动(蓝色箭头)和针对敌方单元的交战指令(红色箭头),这些都是在没有人类输入的情况下生成的。(b) 反映了人类指挥官所做的调整,指定友军航空兵直接与敌方航空兵交战。(c) 代表对主要作战行动的进一步改进,命令部队分头对付敌方两座炮塔,并指示仅侦察单元向北面桥梁推进。
5.6 评估结果
为了对 COA-GPT 进行全面评估,我们为每种方法变体生成了五个 COA,并对每个变体进行了十次模拟,每个基线共进行了 50 次评估。本节讨论的所有结果均代表这 50 次滚动中每个评估指标的平均值和标准偏差。强化学习基线和自动课程强化学习基线的数据直接来源于各自已发表的作品。
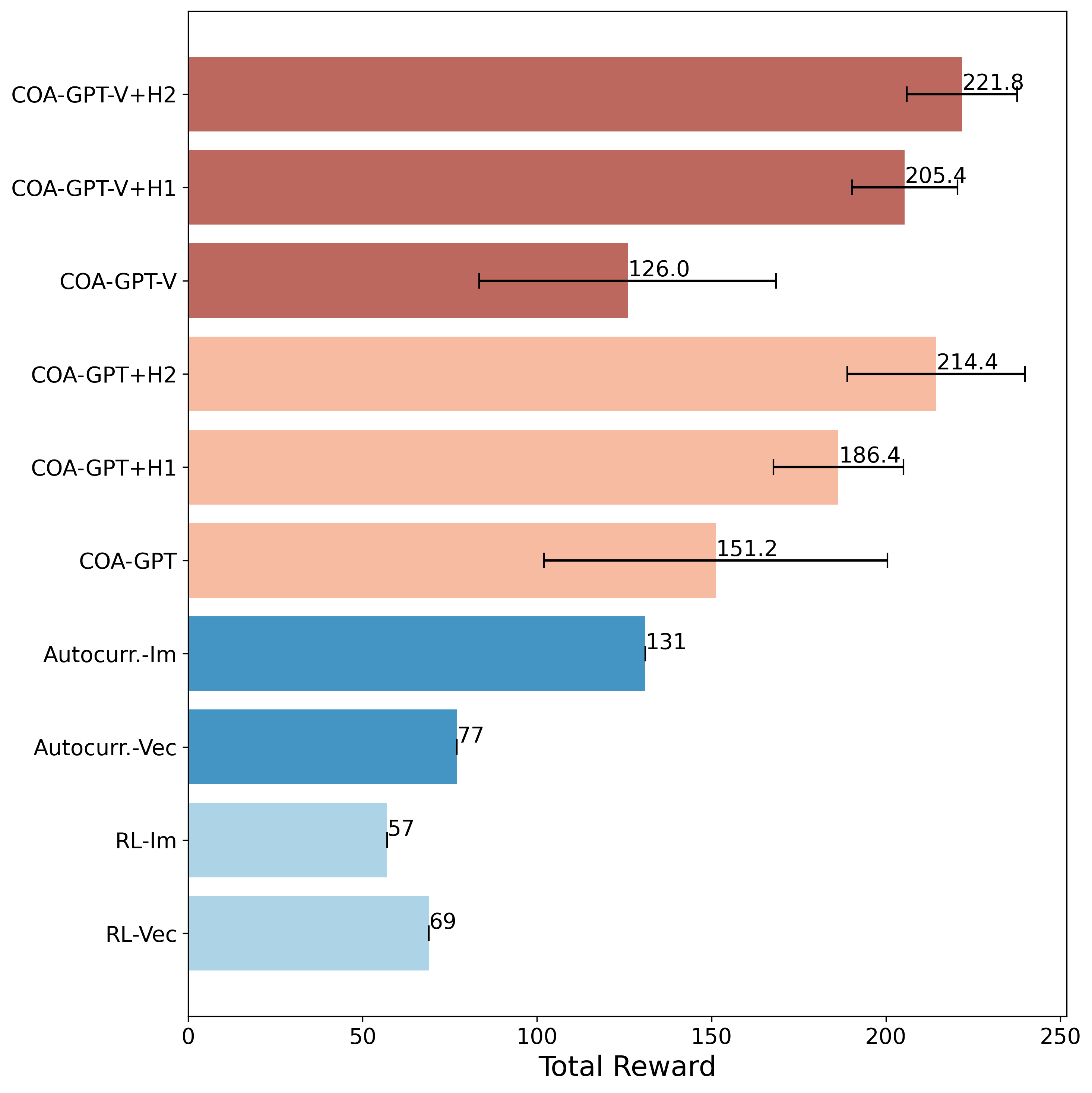
图 7:所有基线的总奖励平均值和标准偏差比较。COA-GPT 在收到人类反馈后生成了更好的 COA,表现优于所有基线方法。
图 7 显示了所有基线方法在评估推广期间获得的总奖励的平均值和标准偏差的比较。COA-GPT 即使在没有人机交互的情况下,仅依靠文本场景表征,其生成的行动方案(COA)的平均性能也超过了所有基线方法。这其中包括之前确立的最先进方法--利用图像数据的自动课程强化学习。COA-GPT-V 也使用单张图像作为额外输入,其性能与之前的基线相当。此外,图 7 显示 COA-GPT 生成的 COA 的有效性在连续接受人类反馈时得到了进一步提高(如更高的平均总奖励所示),并显示出更低的可变性(如更低的标准偏差所示)。考虑到人类反馈后的表现,与之前的所有基线相比,带有视觉模型的 COA-GPT (COA-GPT-V+H1 和 COA-GPT-V+H2)获得了更高的平均总奖励。
图 6 展示了根据人类反馈生成的 COA 的演变过程。最初,在没有人类输入的情况下生成的 COA(图 6a)描述了友军按计划过桥以及与敌方单元交战的情况。在第一轮人类反馈("确保我方航空单元直接与敌方航空单元交战")之后,我们看到了一个战略支点(图 6b);友军航空单元现在被指示直接与敌方航空资产交战。这一调整反映了人类指挥官优先考虑空中优势的意图。反馈的第二次迭代--"确保只命令我方侦察兵单元控制桥式山猫(x:75 y:26),我方其他资产(非航空资产)分成两组,使用 attack_move 命令命令其向敌方两门火炮移动"。- 如图 6c),结果是一种更细致的方法:友军部队被分割,特定单元的任务是瞄准敌方炮兵阵地。此外,侦察单元被命令确保北面桥梁的安全,而友军航空兵的任务仍然是与威胁航空兵交战,这表明 COA-GPT 成功遵循了指挥官通过文本反馈传达的意图。
图 8 和图 9 分别对评估展开期间友军和威胁部队伤亡的平均值和标准偏差进行了比较分析。在图 8 中,我们观察到 COA-GPT 和 COA-GPT-V 即使通过人工反馈进行了增强(COA-GPT+H1、COA-GPT+H2、COA-GPT-V+H1 和 COA-GPT-V+H2 模型),与其他基线相比,友军伤亡也更高。这一结果可能与 COA-GPT 较低的控制分辨率有关,它在事件开始时提供单一的战略命令,而不是像基线方法那样在整个事件中提供连续的命令输入。虽然这种方法有助于为人类操作员提供更易于理解的 COA 制定过程,但由于 COA 执行期间的战术调整有限,它可能会增加伤亡率。
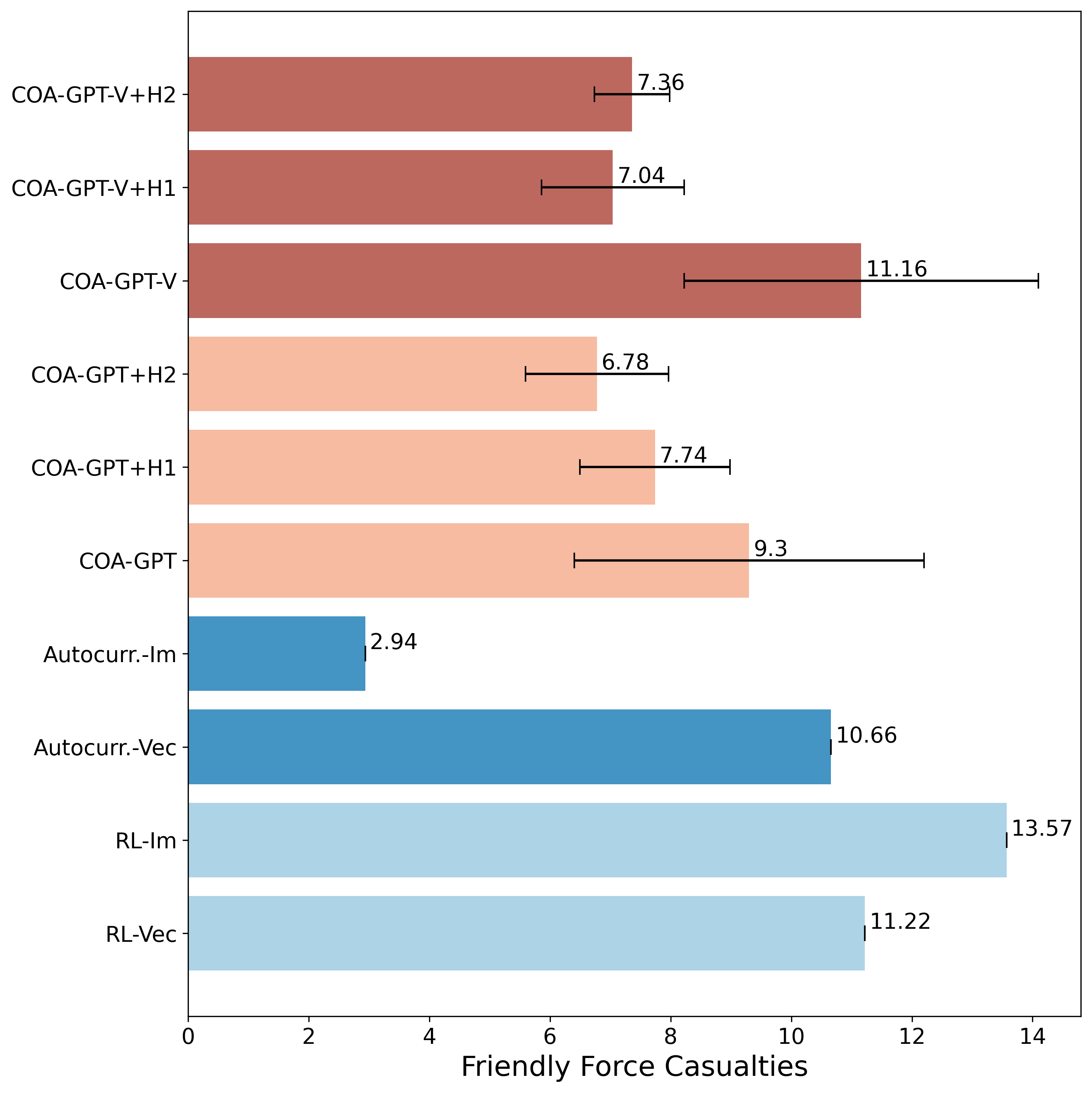
图 8:所有基线中友军伤亡的平均值和标准偏差比较。尽管有人类反馈,COA-GPT 仍显示出更高的平均伤亡率,这表明精确控制可能会带来额外风险。
相比之下,图 9 显示,尽管 COA-GPT 的控制分辨率较低,但其对威胁部队的杀伤力仍与其他基线一致。这表明,COA-GPT 和 COA-GPT-V 变体在消除威胁方面能够与其他方法的有效性相媲美,即使存在指挥能力粒度较低的潜在缺陷。
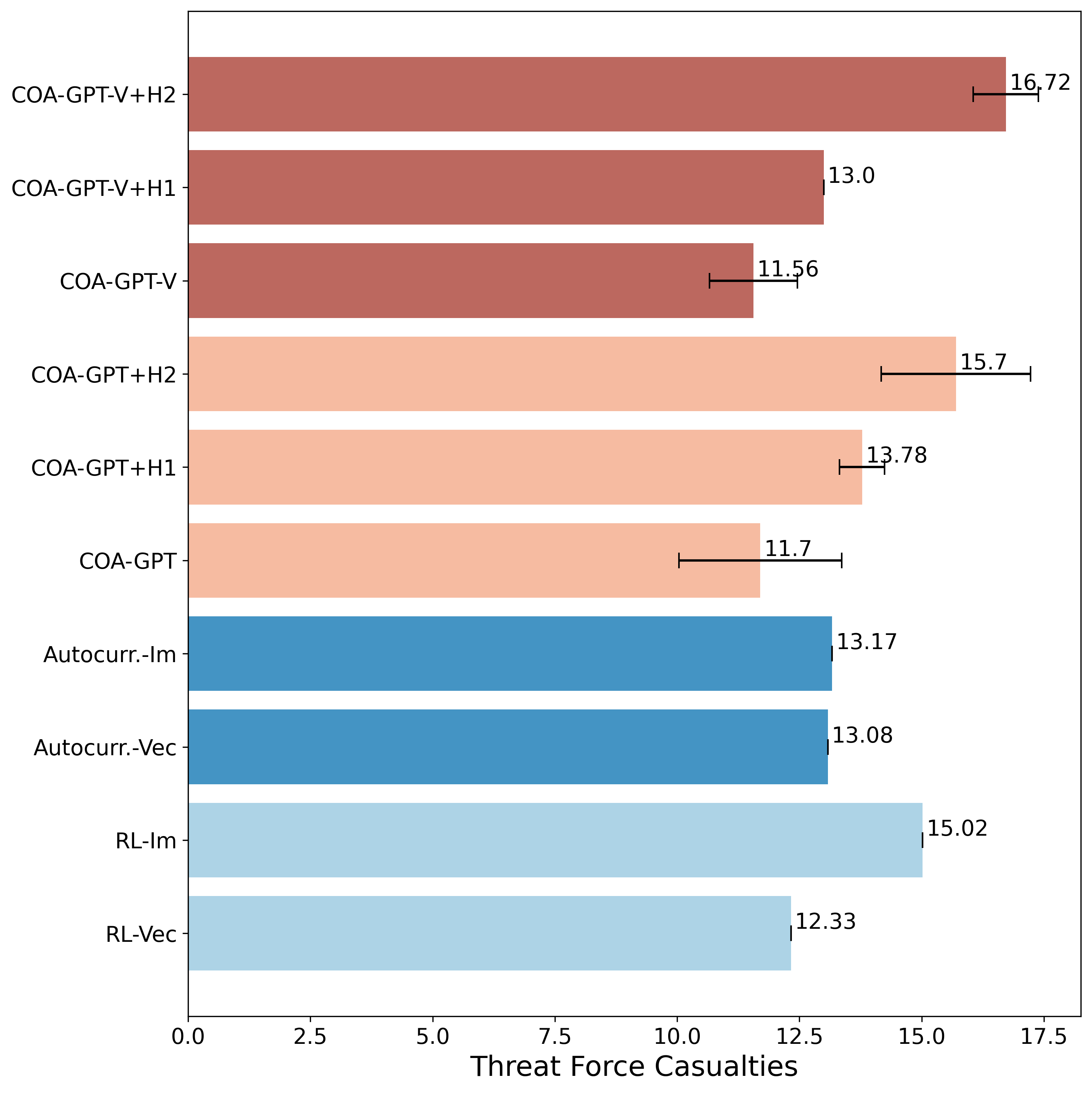
图 9:所有基线中威胁部队伤亡的平均值和标准偏差比较。COA-GPT 保持了与其他方法相当的杀伤力,表明无论控制粒度如何,都能有效地与威胁交战。
作为作战效率的一个重要方面,我们评估了在所有基线中生成 COA 所需的时间。Autocurriculum 方法需要大量的训练时间,包括 11.2 万次模拟战斗,相当于在 35 个并行工作者中进行 7000 万次时间步,才能使其最终训练策略达到最佳性能[26]。相比之下,COA-GPT 能在数秒内生成可操作的 COA,在快速部署方面具有显著优势。此外,COA-GPT 还具有出色的灵活性,能适应新的友军和威胁部队配置以及地形变化,而无需重新训练。这种适应性延伸到人类指挥官,他们可以直观地调整 COA-GPT 生成的 COA。自动课程和传统的强化学习方法不具备这种即时适应性,因为它们在部署前依赖于在固定条件下进行大量的预训练,灵活性较差。
研究结论
本研究通过 COA-GPT 的开发,展示了军事规划和决策领域的进步。面对日益复杂多变的未来战场,COA-GPT 解决了 C2 操作中对快速知情决策的关键需求。COA-GPT 充分利用了 LLM 的强大功能,无论是纯文本输入还是文本和图像输入,都能大大加快 COA 的开发和分析速度,通过上下文学习将军事条令和领域专业知识融为一体。
综合评估结果进一步验证了 COA-GPT 的有效性。值得注意的是,它在开发符合指挥官意图的 COA 方面表现出色,优于包括最先进的自动课程强化学习算法在内的其他方法。COA-GPT 的适应性得到了增强,人类反馈的可变性也有所降低,这凸显了 COA-GPT 在现实世界场景中的潜力,在这些场景中,动态适应不断变化的条件至关重要。
此外,COA-GPT 能够在几秒钟内生成可操作的 COA,而无需进行大量的预训练,这充分体现了它在各种军事场景中快速部署的潜力。这一特点,加上其适应新情况的灵活性,以及与人类指挥官的直观互动,突出了 COA-GPT 的实用性和作战效率。
总之,COA-GPT 代表了军事指挥作战中的一种变革性方法,有助于更快、更敏捷地做出决策,并在现代战争中保持战略优势。它的开发和成功应用为军事人工智能的进一步创新铺平了道路,有可能重塑未来军事行动的规划和执行方式。

