

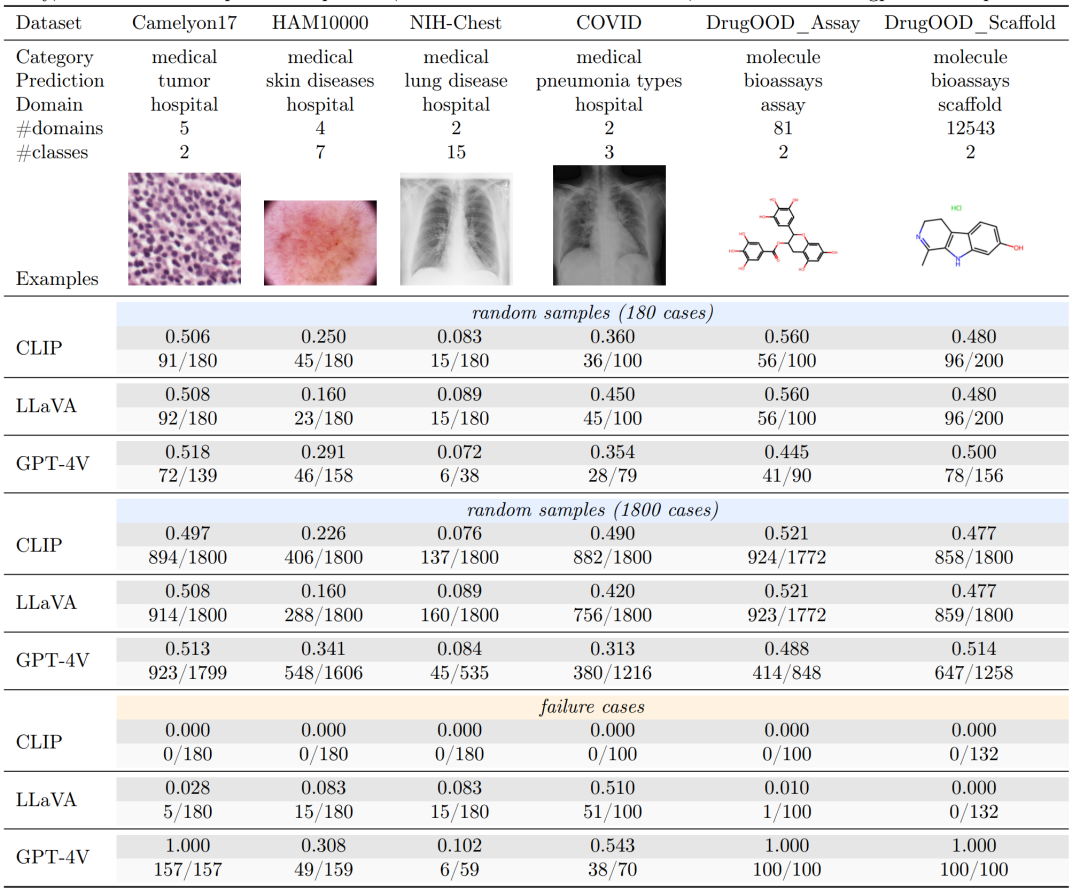
引言在机器学习领域,针对分布偏移(即部署条件与训练场景不同)的泛化能力至关重要,尤其是在气候建模、生物医学和自动驾驶等领域。基础模型的出现,以其广泛的预训练和任务多样性而著称,增加了人们对其适应分布偏移能力的兴趣。GPT-4V(ision) 作为目前公开可获取的最先进的多模态基础模型之一,在异常检测、视频理解、图像生成和医疗诊断等多个领域都有广泛应用。然而,其针对数据分布的鲁棒性在很大程度上尚未被深入探索。 为了填补这一研究空白,本研究严格评估了 GPT-4V 在分布变化环境中的适应性和泛化能力,并与 CLIP 和 LLaVA 等著名模型进行了对比。如图1所示,我们深入研究了 GPT-4V 在 13 个不同数据集上的零样本泛化能力,这些数据集涵盖了自然、医学和分子领域。我们进一步探讨了它对受控数据干扰的适应性,并考察了上下文学习作为提高其适应性的工具的有效性。我们的发现勾勒出了 GPT-4V 在分布偏移上的能力边界,揭示了它在各种情景中的优势和局限。重要的是,这项研究有助于我们理解 AI 基础模型如何泛化到分布偏移,为它们的适应性和鲁棒性提供了关键洞察。 本报告的贡献在于首次全面探讨了 GPT-4V 对分布偏移的适应性,提供了基于定量的基准结果和比较(表1和表2),并通过严格的实验得到了深入的分析和洞见。这些成果为理解和提升多模态基础模型在面对数据多样性时的表现提供了重要的基础。
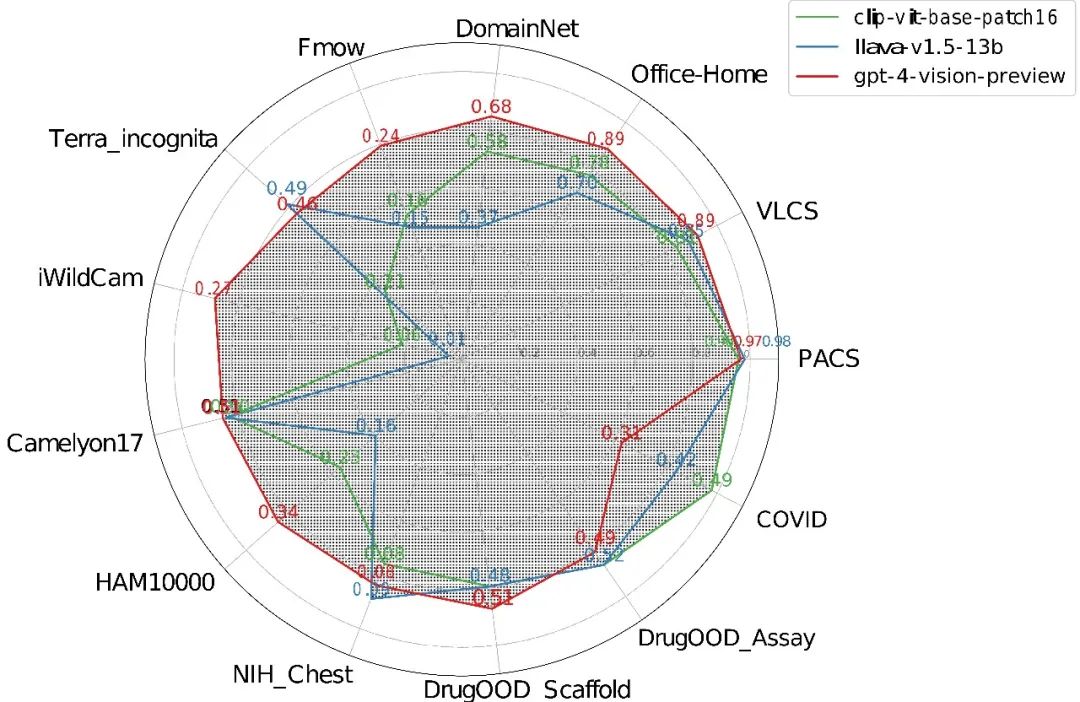
图1 跨多样领域零样本泛化的比较分析图。此图展示了对 13 个不同数据集进行了零样本泛化性能的比较分析结果,这些数据集涵盖了自然、医疗和分子领域。 表1 各种自然数据集上零样本泛化性能的总结
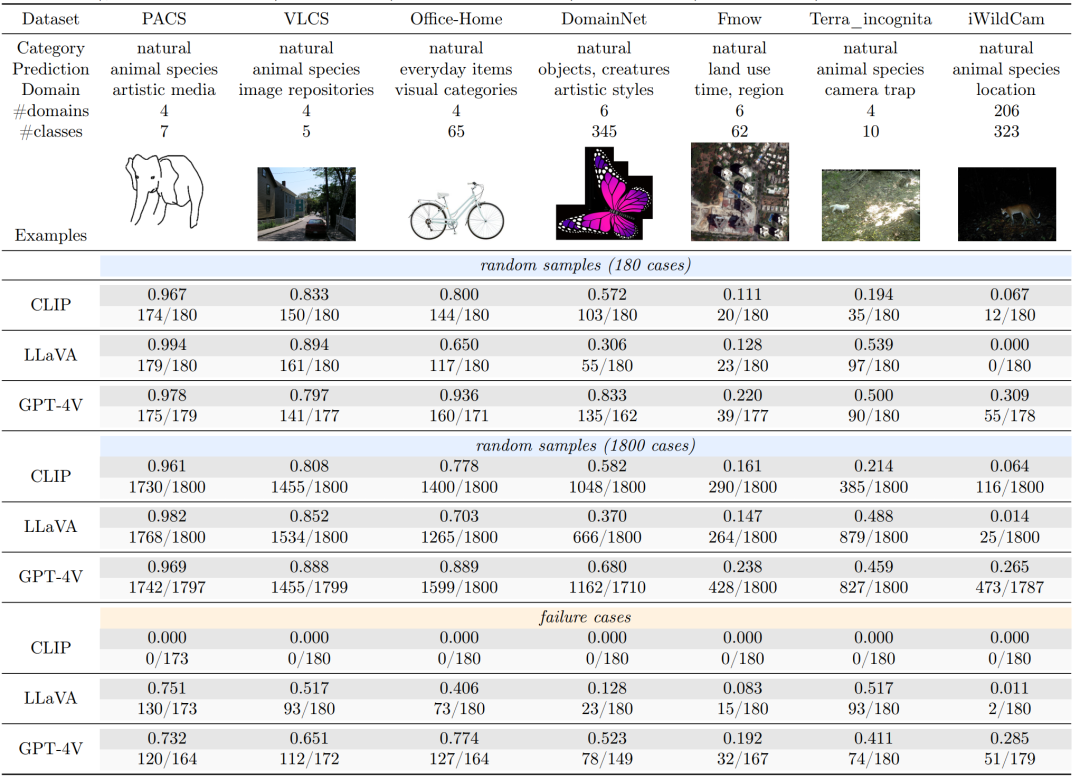
表2 医学和分子数据集上分布偏移情况下零样本泛化性能的主要结果
主要研究问题
本研究探究的主要问题如下: 1.GPT-4V 如何有效地处理多样领域中的分布偏移?
我们旨在衡量 GPT-4V 在多样领域固有的独特分布偏移中的零样本适应能力。我们计划评估 GPT-4V 如何理解和应对数据分布的变化,并将其性能与如 CLIP(以对自然分布偏移的鲁棒性而知名)以及开源的多模态基础模型 LLaVA等模型进行对比。 2.GPT-4V 对故意改变的数据分布有何反应? 传统上对分布偏移的处理通常考虑模型从源域到目标域的泛化能力,其中包含数据分布的固有偏移。然而,在零样本情境中,这种适应能力可能与传统设置有所不同,因为测试数据可能与 GPT-4V 的预训练数据大相径庭。鉴于其预训练数据的不透明性,我们调查了对我们设计的分布偏移的反应。我们首先从 GPT-4V 最初表现出有前景的领域中选择图像,这表明这些图像可能与其预训练分布一致或成为其一部分。随后,我们打算对这些选定的图像引入高斯噪声并实施风格转换(使用ControlNet)。这些操作旨在创建特定的分布偏移,以评估模型在这些受控干扰下的泛化能力。 3.上下文学习是否是增强 GPT-4V 适应分布偏移的有效方法? 基础模型中处理分布偏移的常规方法通常涉及调整模型参数,通常通过高效调优或微调等方法。考虑到微调 GPT-4V 庞大参数的不切实际性,我们转而探究上下文学习的潜力,这是大型语言模型中突现能力的核心技术,作为模拟传统领域泛化方法的替代方案。这种方法包括使用来自源域的代表性图像作为上下文实例,随后引入一个来自新目标域的测试图像。本研究关注于上下文实例提高 GPT-4V 在面对分布偏移时的性能的能力。 主要结果与发现
1.跨领域的零样本泛化能力:GPT-4V在自然图像领域表现出强大的鲁棒性,但在医学和化学等特殊领域的表现则不够理想。如表2所示,在 Camelyon17、NIH-Chest、DrugOOD Assay 和 DrugOOD Scaffold 等数据集中,GPT-4V 的分类结果类似于随机猜测。这一模式表明在这些特定领域需要有针对性的改进。 2.对控制数据扰动的适应性:在对数据进行人为扰动的实验中,GPT-4V表现出优于其他模型的稳定性和准确性。如表3所示,GPT-4V展现了优秀的性能,特别是在处理具有挑战性的样本和 CLIP 出错的情况下。这些结果强调了 GPT-4V 在面对受控干扰和新的数据分布时的稳定性和可靠性,突显了其泛化能力。 表3 ControlNet创建的分布变化中零样本泛化性能的主要结果
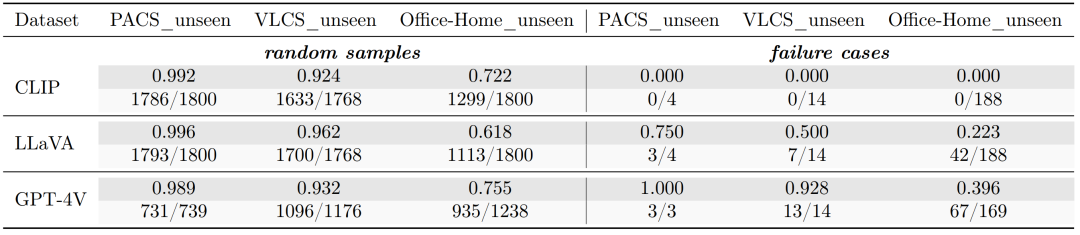
3.上下文学习的有效性:在上下文学习的实验中,GPT-4V能够通过比较不同的源图像来准确推断出目标图像的类别。如图2所示,这种适应性在四个不同的数据集中均得到了一致的体现,加强了上下文学习策略在应对分布偏移中的实用性。展望未来,开发有效的上下文学习方法,以进一步增强 GPT-4V 在多样数据分布中的鲁棒性,是一个充满希望的方向。特别是在图3中描述的案例研究中,GPT-4V 展示了其准确识别病理图像类别的能力,通过与两个源图像的差异进行比较。
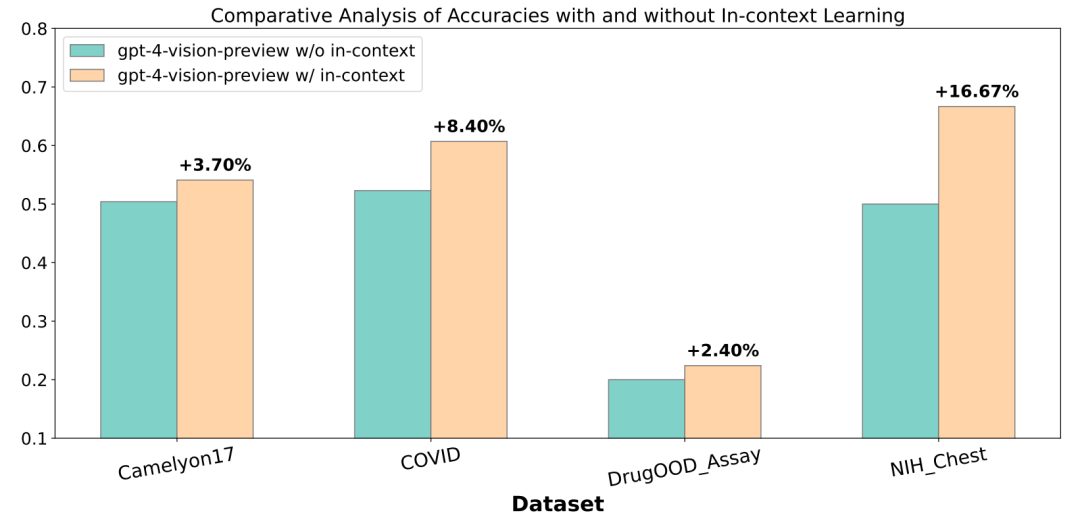
图2 在Camelyon17、COVID、DrugOOD_Assay和NIH_Chest数据集上,GPT-4V通过上下文学习在目标域上得到明显的性能提升。 4.分类理由的详细性:GPT-4V在分类时提供的理由显示出它对图像细节的深入理解。如图4所示,GPT-4V准确识别了如健壮的身体、短尾巴和绒毛耳朵等独特特征。此实例清楚地表明 GPT-4V 在识别和阐述图像中更细微的细节方面的先进能力,在分布偏移下的复杂图像分类任务中进一步强化了其优越性。 5.预测中的高置信度:GPT-4V 在其预测中始终显示出更高且更合理的置信度水平,表明了一种自信和精确的决策过程。GPT-4V注重细节的分类理由有助于其与LLaVA相比生成更高的自信度分数。例如,在图5中,GPT-4V在描述性分析中达到了高峰自信度分数:“该图像显示了一个带有喷嘴、把手和顶部温度计的金属水壶,这是加热水使用的水壶的常见设计。”相反,在医学成像场景中,如图6所示,GPT-4V的自信度分数更为适中,常伴随着进一步临床测试的建议,反映出在高风险环境中谨慎的方法。 6.领域特定微调的需求:GPT-4V在需要专业知识的领域(如医学、化学和生物学)的表现凸显了使用领域特定数据进行进一步微调的需求。虽然GPT-4V通常提供合理且符合上下文的推理,但它仍然可能产生错误的分类或诊断。一个例子是图7,GPT-4V准确地描述了一个标记为吉他的图像,称:“该图像展示了一把吉他的风格化描绘……从而对这个识别有很高的自信度”,但它错误地将图像分类为一个人。这个例子强调了领域特定微调的关键需求,尤其是在精确性和可靠性至关重要的领域。 7.在挑战性样本中的一致性:GPT-4V在处理挑战性样本方面展现出了非凡的一致性,尤其是在CLIP遇到错误的场景中。其表现显著优于LLaVA,表现出更强的适应性和精确性。这在表1和表2中得到了清晰的证明,其中,在失败案例中,GPT-4V几乎以显著优势胜过LLaVA和CLIP。这些发现突显了GPT-4V在处理复杂样本,尤其是那些涉及显著分布变化的样本方面的稳健性和有效性。 8.对某些任务适用性的限制:GPT-4V在标签缺乏语义信息时在分类任务中遇到困难。这一限制在诸如涉及化学分子结构的活动识别任务的场景中变得明显。在这些案例中,其中样本标签仅为“活跃”或“不活跃”,GPT-4V和LLaVA往往表现不比随机猜测更好。如图8中所强调的,“该图像展示了一个化学结构,它在物理运动或活动的上下文中没有活跃或不活跃的状态”,揭示了上下文理解方面的差距。同样,带有数值标签的任务也对GPT-4V的零样本分类能力构成挑战。这些发现强调了对涉及非语义标签的下游任务进行额外适应或微调的需要。
结论与展望
这项研究不仅深入探讨了GPT-4V在处理分布偏移时的能力,而且还为未来在AI和机器学习领域的研究提供了重要见解。我们的发现突出了GPT-4V在多个领域中的应用潜力,同时也指出了其在特定任务上的局限性和改进方向。这种局限性强调了持续评估和增强基础模型以应对不断变化的数据环境的重要性。为了实现基础模型的实时评估,我们开放了评测数据集和评测代码,链接如下: GitHub链接为https://github.com/jameszhou-gl/gpt-4v-distribution-shift, Huggingface链接为https://huggingface.co/datasets/jameszhou-gl/gpt-4v-distribution-shift 文章的arxiv链接为https://arxiv.org/abs/2312.07424
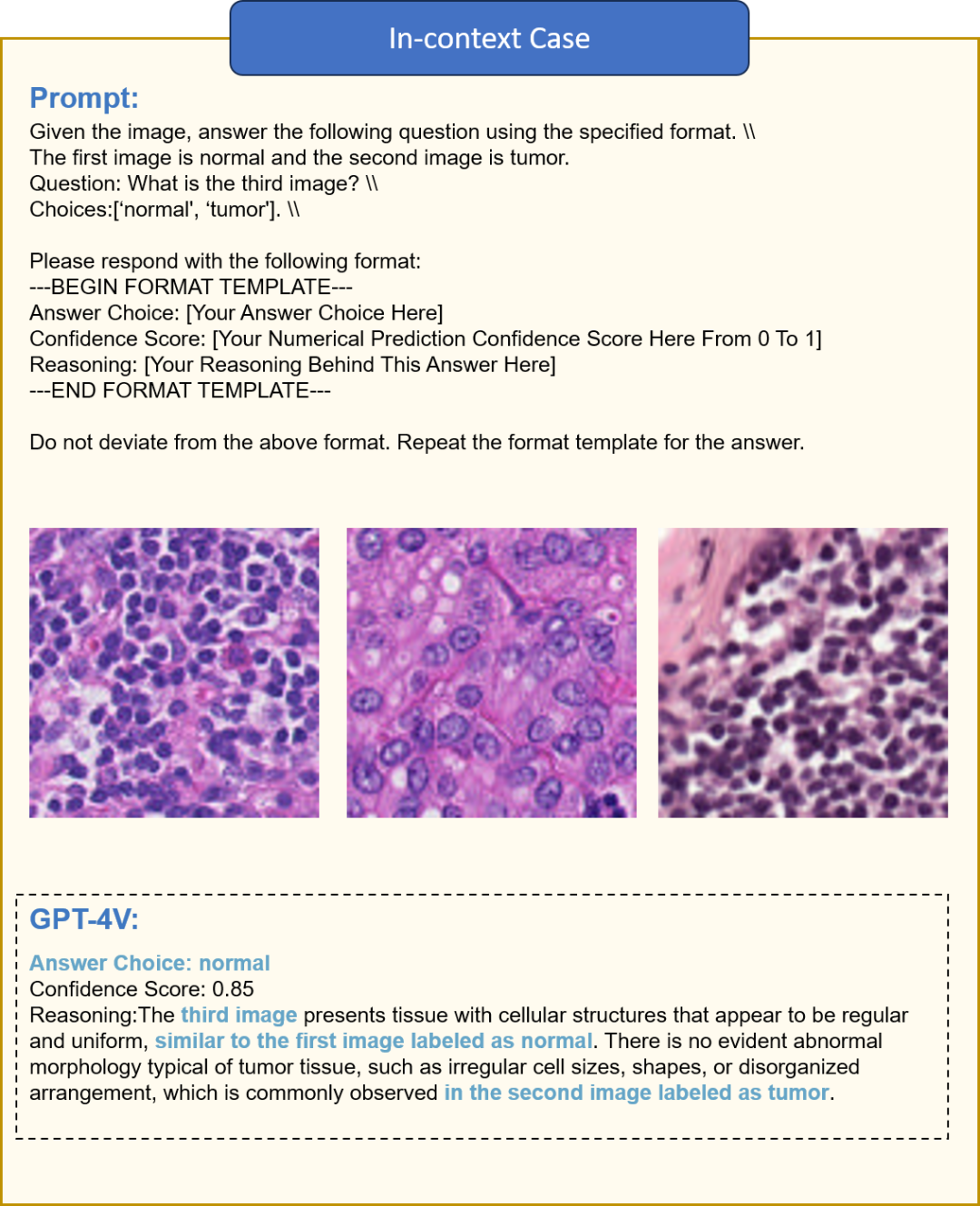
图3 GPT-4V在接触Camelyon17数据集中的上下文学习实例时的推理过程演示。实验包括使用来自源域(hospital_2)的两个代表性图像,一个标记为‘正常’,另一个标记为‘肿瘤’,接着是来自目标域(hospital_3)的测试图像。GPT-4V在这些上下文实例的条件下,区分‘正常’图像中规则和均匀的组织模式和‘肿瘤’图像中异常、不规则的细胞大小。然后它将这种上下文理解应用于准确推断来自hospital_3的测试图像的类别。这个过程展示了GPT-4V利用上下文线索进行有效域桥接的能力。

图4 野外图像分布变化下的分类实例。GPT-4V准确识别了如健壮的身体、短尾巴和绒毛耳朵等图像细节特征。

图5 自然图像分布变化下的分类实例。GPT-4V表现出了更为细腻的理解能力,特别是在详细描述特定特征方面,如水壶的金属质地和喷嘴的存在。此外,GPT-4V通过强调对齐“水壶”典型的设计特点,增强了其回答的信服力。
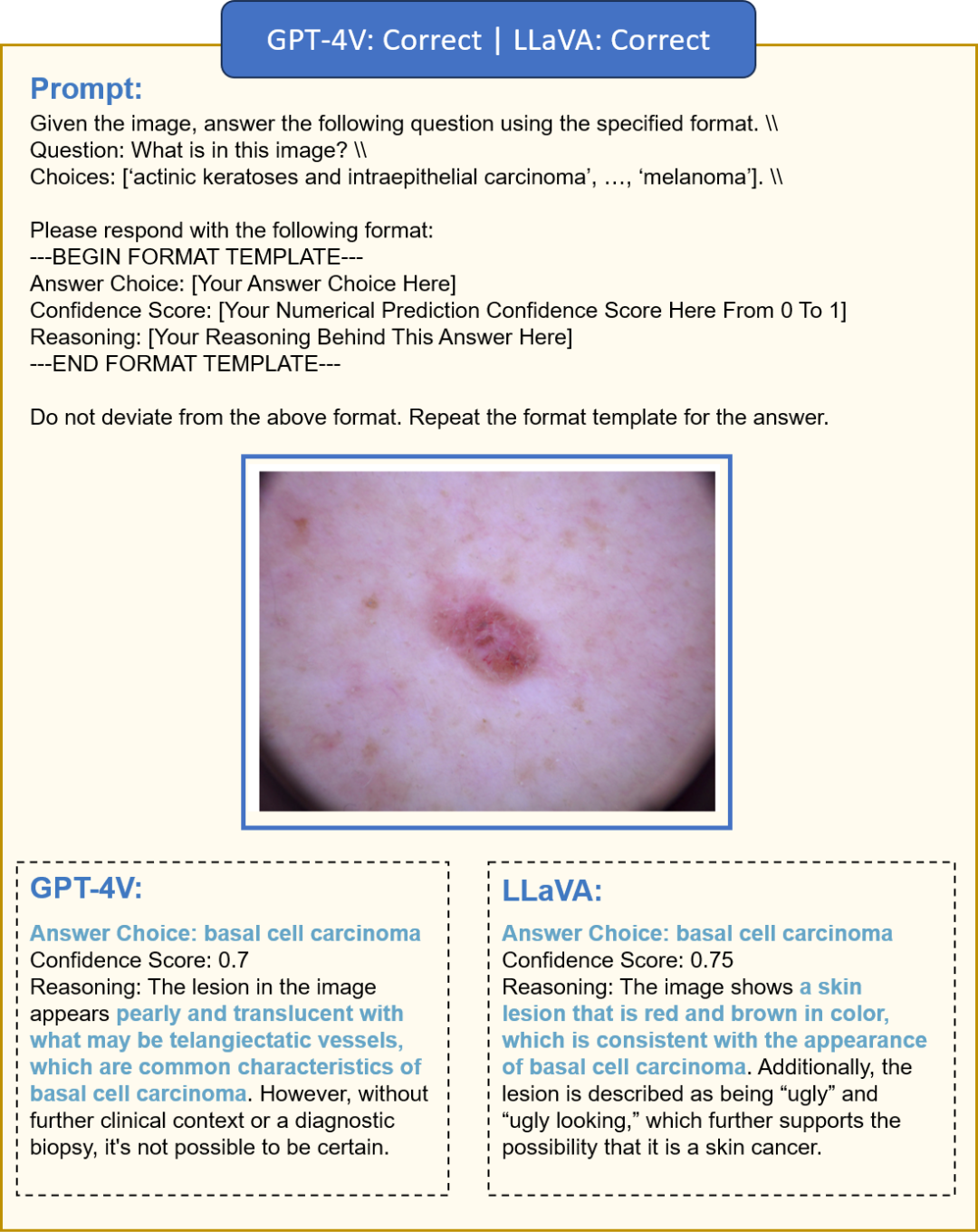
图6 医学图像分布变化下的分类实例。GPT-4V在细致分析方面表现突出,能够识别出如珍珠般、半透明和毛细血管扩张等关键特征,这些是基底细胞癌的表现;LLaVA主要从颜色外观方面给出分析。GPT-4V的自信度分数更为适中,常伴随着进一步临床测试的建议,反映出在高风险环境中谨慎的方法。

图7 自然图像分布变化下的分类实例。虽然GPT-4V通常提供合理且符合上下文的推理,但它仍然可能产生错误的分类或诊断:GPT-4V准确地描述了一个标记为吉他的图像,称:“该图像展示了一把吉他的风格化描绘……从而对这个识别有很高的自信度”,但它错误地将图像分类为一个人,这个例子强调了领域特定微调的关键需求。

图8 化学结构分布变化下的分类实例。GPT-4V在标签缺乏语义信息时在分类任务中遇到困难,揭示了上下文理解方面的差距:该图像展示了一个化学结构,它在物理运动或活动的上下文中没有活跃或不活跃的状态。
