FAIR何恺明团队提出全景分割,开辟图像分割新方向(附论文)
在计算机视觉发展的早期,人们主要关注图像中的人、动物或工具等明显对象(things)。之后,Adelson提出要训练系统识别其他物体的能力,如天空、造地、道路等没有固定形状的事物(stuff)。直到现在,仍然没有一种方法能完美地区分不规则事物与独立个体对象,这对图像识别任务和算法生成特定对象来说都是一项挑战。
要识别特定的事物,就要用分割的方法将图像分解。目前常用的有两种分割方法:语义分割(semantic segmentation)和实例分割(instance segmentation)。语义分割常用来识别研究不规则事物,例如天空、草地。由于这类对象没有特定的形状,同时又不可数,所以语义分割只能简单地给每一个像素打上标签。
相反,研究可数的、独立事物,通常用目标检测或实例分割的方法,从而检测到每个对象,并用边框或分割掩码(segmentation mask)勾画出来。
然而,对不规则物体的分类器,即语义分割,通常建立在膨胀后的充分卷积网络上。而物体检测器,即实例分割,常用object proposals方法,并且基于区域。虽然有关两种方法的算法在过去十年中都得到了发展,但是否能有一种方法能同时识别不规则的背景与图中独立的个体呢?基于此,Facebook人工智能实验室(FAIR)的研究科学家何恺明博士与他的团队近日公布了一种新系统,名为全景分割(Panoptic Segmentation,简称PS)。顾名思义,全景分割就是要生成统一的、全局式的分割图像。

后台回复“PS”即可获取论文资源
简单地说,其工作原理就是将图像中的每个像素都分配一个语义标签和一个实例ID。有同样标签和ID的像素归为同一对象;在检测不规则事物(stuff)时,可忽视实例ID。下图就是语义分割、实例分割以及全景分割的对比图。
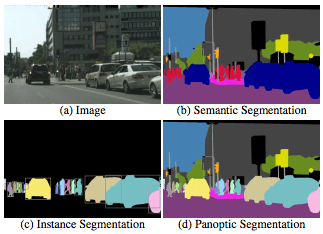
(a)原图;(b)语义分割;(c)实例分割;(d)全景分割
全景分割(PS)的介绍
假设给定一组语义类别L,L:={1,…,L}。全景分割算法将给图像中的每个像素打上标签(li,zi)∈L × N,这里li表示像素i的语义类别,zi表示它的实例ID。实例(而非像素)是算法生成的单位,并且将用于之后的评估过程。对一张照片的ground truth标注方法也是一样的。
语义标签含有两个子集:LSt和LTh,分别代表stuff和things。如果一个像素标签li∈LSt,而它的实例ID与其无关。那么这一stuff类别中的所有像素都属于同一事物,例如同一片天空。相反,如果所有像素都属于同一个(li,zi)类别,同时li∈LTh,那么它们有可能是同一物体,例如同一辆车。
评估标准——PQ
全景分割的评估标准要符合三个特征:全面、可解释、简单。研究人员们根据这些标准制定了全景质量(Panoptic Quality,简称PQ)标准。PQ方法主要衡量全景分割是否与真实图片的相近程度。主要有两个步骤:
实例对应(instance matching)
PQ计算
实例对应(Instance Matching)
研究人员规定,只有当模型预测的分割窗口与原图标记窗口的重叠率,即检测评价函数(IoU)严格大于0.5时,二者才能匹配。这样的要求就保证了最多只有一个分割图像能与真实图片相匹配。
全景质量(PQ)计算
我们对每一类别进行独立的全景质量计算,然后再取平均值。对每一类别,唯一的匹配将预测分割图像与真实图像分成三类:真正(TP)、假正(FP)和假负(FN),分别表示匹配的分割、不匹配的预测分割图像和不匹配的真实图像。下图为一示例:
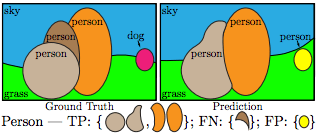
PQ的定义用公式表示为:
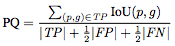
全景分割数据集
目前为止,只有三个数据集既有大量语义分割标注,又有实例分割标注。
Cityscapes:拥有5000张街景图片,97%的图片有像素标注,共有19个类别,其中8个类别符合语义分割的特征;
ADE20k:图像总量超过25000张,并经过公开标注。其中包括100种物体和59种事物。
Mapillary Vistas:同样拥有25000张街景照片,分辨率也大不相同。其中98%的图片都经过了像素标注,涵盖28种事物与37种物体。
除此之外,未来我们还会把这一任务扩展到COCO上。
人类表现的如何?
全景分割和全景质量评估的优点之一是它也能测量人的表现。同时,对人类表现的研究也有助于研究人员了解这项任务的细节,并提升系统的性能。

上图就展示了人类在上述三个数据集中的表现,除了全景质量(PQ)之外,还测试了分割质量(SQ)和检测质量(DQ)。不过,人类识别物体的能力也并不完美,比如下面两图就说明人们在区分重叠物体以及分类的时候也会“眼花缭乱”。

第一排中,两位标注员都识别出了汽车,但第一位却把一辆汽车看成了两辆;第二排中,图中那人的脚确定是他自己的么……

继续细分下来,全景分割是将事物(stuff)和物体(things)结合起来的,如果测试人类在这两项中的表现,会有什么结果呢?
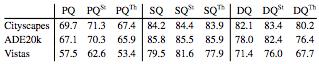
如图所示,研究人员将每一类都分出了事物和物体的小类,比如PQSt指对事物的全景分割能力,PQTh指对物体的全景分割能力。
在Cityscapes和ADE20k中,人类在事物和物体上的表现相差不大。但是在Vistas数据集上就差的有点多。
下图展示了在每个数据集所包含的所有类别中,人类的全景分割能力。
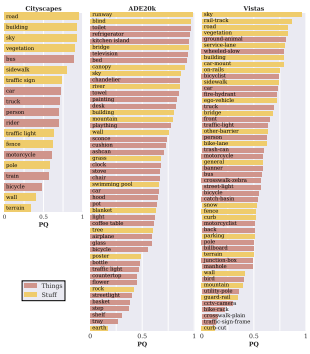
另外,图像中对象的大小也会影响人们识别它的能力。下图就统计了在大(L)、中(M)、小(S)三个尺寸下人类进行全景质量、分割质量和检测质量的水平。
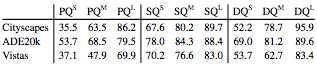
结果不言而喻,图像尺寸越大,表现越好。
机器表现得又怎样呢?
看完了人类表现,现在我们要探讨两个问题:
最先进的实例分割和语义分割系统如何在全景分割上工作?
机器生成的结果与人类的相比怎么样?
对于选取的三个数据集,研究人员分别收集了合适的数据。对Cityscapes,他们采用了PSPNet和Mask R-CNN收集输出数据,分别用于语义分割和实例分割。对于ADE20k,研究人员利用的是在2017 Places挑战赛中的胜出者得出的结果作为数据集。对于Vistas,研究者采用了LSUN’17 图像分割挑战赛中胜出者产生的1000张图片作为数据集。准备好数据和算法后,就开始让机器进行全景分割测试啦!
首先是机器的实例分割表现(Vistas不在其中是因为在2017实力分割挑战赛中只有一个记录)。
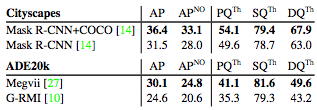
APNO是预测中非重叠的AP。正如预测的那样,去除重叠部分会损害AP,因为检测器可以预测多个重叠的假设。有较高AP得分的同样有较高的APNO,PQ也是如此
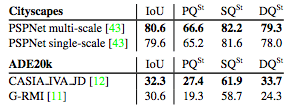
接下来是语义分割的表现,由于语义分割没有重叠的片段,所以我们可以直接计算PQ。在下表中,我们比较了平均IoU值和PQ值。
最后,将上述两个结果对比,如下表:
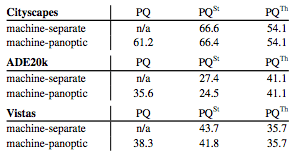
全景分割的输出可见下图:

以及人与机器的表现对比:
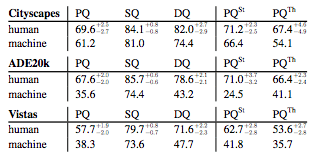
对分割质量(SQ)来说,机器只落后于人类一点点,不过在检测质量(DQ)方面,机器的水平则与人类差得多,尤其在ADE20k和Vistas数据集上,这种差距更明显。这就说明机器识别,即目标检测是目前最大的挑战。
结语
希望今后的项目能够以全景分割为出发点,引入更有趣的算法,驱动图像识别领域的创新。研究人员希望未来能看到深度集成的端到端模型,同时具备PS的“双重性质”(stuff和things);另外,由于PS不能有重叠的片段,因此某种高层次的“推理”可能是有益的。例如,基于向PS扩展科学系的NMS。最后,研究人员希望2018年能够继续挑战全景分割,创造更多新成果。
原文地址:arxiv.org/pdf/1801.00868.pdf






