【深度度量学习系列】Triplet-loss原理与应用
深度度量学习(Deep Metric Learning, DML)的一个经典的应用就是人脸识别,Google 的FaceNet模型使用Triplet-Loss刷新了当时人脸识别的记录。
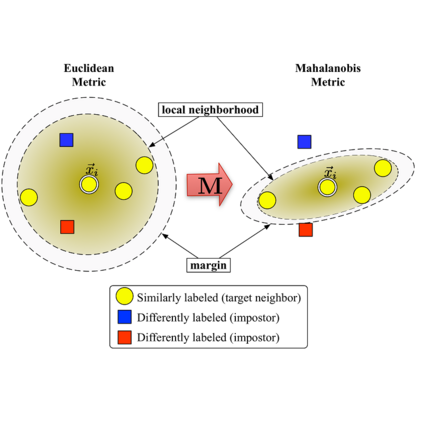
Ranking loss被用在很多不同的领域,它有非常广泛应用,但缺乏命名标准化,导致了这个损失函数拥有很多其他别名,比如对比损失Contrastive loss,边缘损失Margin loss,铰链损失hinge loss和我们常见的三元组损失Triplet loss等。Ranking loss的目的是去预测输入样本之间的相对距离,这个任务经常也被称之为度量学习(metric learning)。
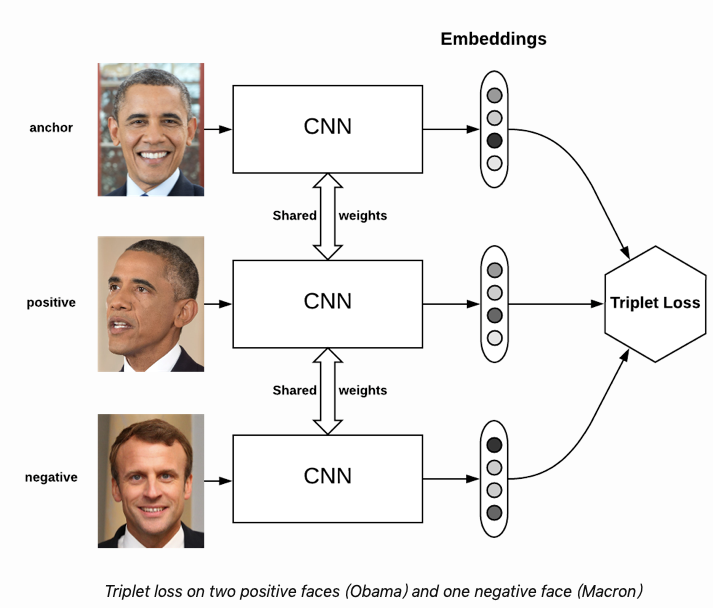
深度度量学习(Deep Metric Learning, DML)的一个经典的应用就是人脸识别,Google的FaceNet模型使用Triplet-Loss刷新了当时人脸识别的记录。Triplet-loss作为Ranking loss的一种,用于训练差异性较小的样本。Triplet-loss用的是三元组进行训练,训练数据包括一个锚点(anchor) 、一个正样本(positive)和一个负样本(negative),它的目的是使得锚点和正样本的距离尽可能小,与负样本的距离尽可能大。
一、为什么不用softmax?
通常在监督学习中,我们有固定数量的类别,并使用softmax交叉熵损失来训练网络。但是在某些情况下,我们的类别是个变量, 例如,在人脸识别中,我们需要能够比较两个未知的面孔,并说出它们是否来自同一个人。在这种情况下,Triplet-loss学习的是一个好的embedding。在embedding空间中,相似的图像是相近的,因此可以判断是否是同一个人脸。
二、Triplet-loss原理
需要注意的是,我们在使用Triplet-loss时并不是为了将embedding空间分成很多簇,而是给定锚点、一个正样本和一个负样本,负样本离锚点的距离比正样本锚点的距离远即可。该思想与SVM中的margin非常相似,在这里我们希望每个类别的簇由margin来分割。
Triplet-loss的输入是一个三元组<a,p,n>
-
a:anchor -
p:positive, 与 a 是同一类别的样本 -
n:negative, 与 a 是不同类别的样本
其损失函数公式如下:
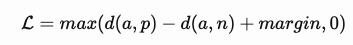
若想要最小化L,则需要让d(a,p)→0, d(a,n)→margin,即拉近(a,p)的距离,拉远(a,n)的距离。
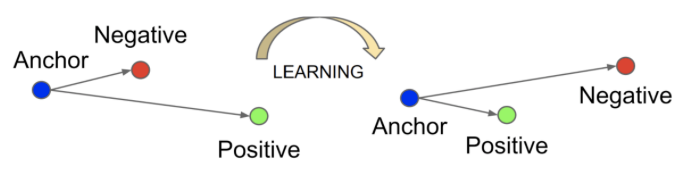
根据上述定义,有三种三元组类别:
-
easy triplets: L=0, 即d(a,p) + margin < d(a,n),这种情况不需要优化,天然(a,p)距离近,(a,n)距离远 -
hard triplets: d(a,n) < d(a,p),即(a,n)距离近,(a,p)距离远。 -
semi-hard triplets:d(a,p) < d(a,n) < d(a,p) + margin,即(a,n)的距离也很近,但相对与(a,p)会有一个margin,比easy triplets会稍微hard一些。
不同种类三元组类别的使用将会对指标有很大的影响。在原始的Facenet论文中,是随机选取semi-hard triplets进行训练的,取得了不错的效果。
三、三元组选择方法
Easy negative example比较容易识别,因此没必要构建太多这个简单类型的三元组,否则会严重降低训练效率。若都采用hard类型,又可能会影响训练效果。这时,就需要一定的方法进行三元组的挑选,也就是“mine the triplets”。
3.1 Offline mining -- 离线挖掘
训练集所有数据经过计算得到对应的embedding,根据embedding计算得到(a,p)和(a,n)之间的距离,根据这个距离判断三元组属于semi-hard triplets,hard triplets还是easy triplets中的哪一类。Offline triplet mining 仅仅用于选择hard或者semi-hard的三元组类型,因为easy triplet太容易了,没有必要训练。
总得来说,这个方法效率不高,因为需要过一遍所有的数据得到三元组,而且每过一轮或几轮,可能还要重新对负样本进行分类。
3.2 Online mining -- 在线挖掘
Online triplets mining的思想是为每一batch动态挖掘有用的三元组,即只计算batch中的triplets。将一个batch(B张图片)输入到神经网络中,得到B张图片的embedding,可组合出 个三元组,但其中包含很多不可用的三元组(比如<a,p,p>或者<a,n,n>)。假设一个triplet<i,j,k>,如果i和j是同样的标签,i和k是不同的标签,这样的三元组才是可用三元组(valid triplets)。
假设一个batch的数据有P个人,每人K张图片,则共包含P*K张人脸。针对valid triplet的挑选,有如下两种策略:
-
Batch all: 计算所有的valid triplet,对hard 和 semi-hard triplets上的loss进行平均(easy triplets不参与计算,平均会导致loss很小),可以得到PK(K-1)(PK-K)个三元组。
-
Batch hard: 对于每一个锚点,选择距离最大的正样本(a,p)和距离最小的负样本(a,n),可以得到PK个三元组。
四、Triplet-loss在NLP领域中的应用
Triplet loss通常是在个体级别的细粒度识别上应用,比如精确到哪一个人的人脸识别,所以triplet loss的最主要应用也就是人脸识别face identification、跨境追踪技术person re-identification、车辆追踪vehicle re-identification等各种identification问题上。除了图片领域,NLP领域也有丰富的triplet-loss使用场景,比如推荐系统和文本匹配任务。在推荐系统中,候选集里的商品可能都是用户喜欢的,triplet-loss用于比较哪个商品对用户来说更适合。而在文本匹配任务中,对于锚点文本和一个待匹配的文本,如果用二分类问题是不合适的,可以用triplet-loss学出一个排序模型,输出的分数用于比较哪个更匹配。
2015年的IBM watson团队的的文章Applying Deep Learning To Answer Selection: A Study And An Open Task,损失函数也用到了triplet-loss。这篇论文的任务是问答,输入一个问题,从候选集中找到对应的回答。因此也可以看成释义识别任务,或者是短文本匹配。原文传送门https://arxiv.org/pdf/1508.01585.pdf。
这篇论文的特色是“齐全”,作者设计了6种CNN结构和8种相似度实验,这里不再一一介绍,感兴趣移步原文。在损失函数的部分,对于输入的Q,训练集中有一个正确的正样本A+和通过采样得到的负样本A-,计算cos(Q,A+)和cos(Q,A-)。最终目标是使这两个相似度之间的差值大于margin。
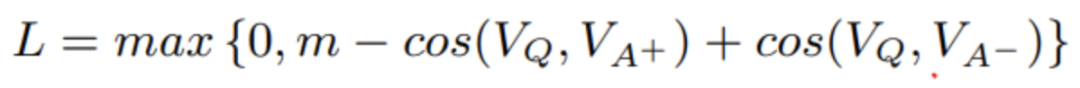
五、Triplet-loss实践
贝壳找房智能客服的场景也涉及文本匹配,我们选择了最简单的深度语义匹配算法LSTM-DSSM进行Triplet-loss的实践,LSTM-DSSM模型原理传送门。(深度语义匹配模型:表示型)
5.1 数据准备
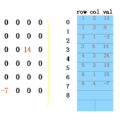
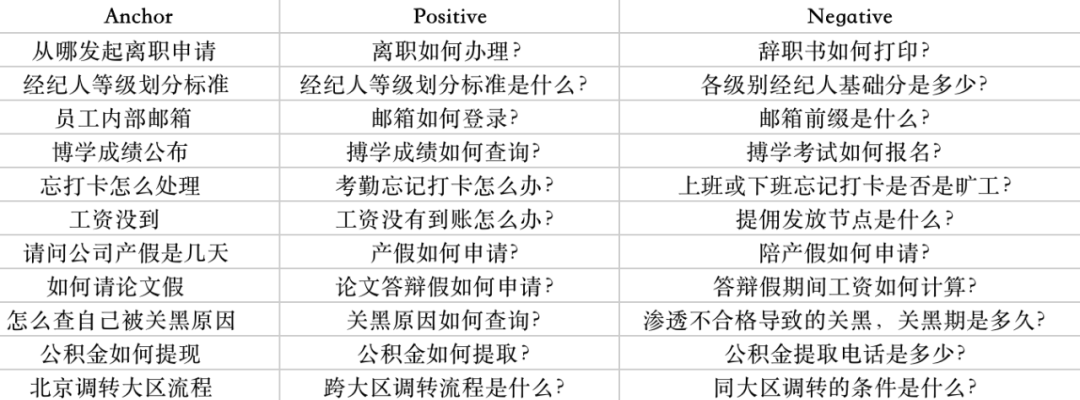
在已有的query-标准问-知识匹配库中,query与标准问是一对一的关系,标准问与知识是多对一的关系,即一条query只能总结成一条标准问,一条知识可以被不同的标准问挂接。因此 <query, 标准问,同一条知识下的任意一条其他标准问> 就形成了一组triplet。通过这种方式共产生了30w+的triplets,其中28w作为训练集,2w+作为测试集。
下图展示部分训练数据,label为(0,1),此处的(0,1)为index,0表示anchor与第一句话同类别,1表示anchor与第二句话同类别。
5.2 建模
def forward(self):
# Embedding Layer
a_embedding = self.dropout(tf.nn.embedding_lookup(self.embed, self.a))
p_embedding = self.dropout(tf.nn.embedding_lookup(self.embed, self.p))
n_embedding = self.dropout(tf.nn.embedding_lookup(self.embed, self.n))
# Representation Layer
with tf.variable_scope('a_lstm'):
self.a_output, self.a_state = self.LSTM(a_embedding)
with tf.variable_scope('p_lstm'):
self.p_output, self.p_state = self.LSTM(p_embedding)
with tf.variable_scope('n_lstm'):
self.n_output, self.n_state = self.LSTM(n_embedding)
# Cosine Layer
with tf.name_scope('cosine_similarity'):
self.cos_a_p = self.cal_cosine(self.a_state[1],self.p_state[1])
self.cos_a_n = self.cal_cosine(self.a_state[1],self.n_state[1])
# Loss(按照triplet loss的公式)
zero = tf.fill(tf.shape(self.cos_a_p),0.0)
margin = tf.fill(tf.shape(self.cos_a_n),args.margin)
losses = tf.maximum(zero,tf.subtract(margin,tf.subtract(self.cos_a_p,self.cos_a_n)))
self.loss = tf.reduce_sum(losses)
self.train_op = tf.train.AdamOptimizer(args.lr).minimize(self.loss)
# 真实标签全为0,即【p,n】中,q和p为同一类,self.pred为输出的类别
self.y = tf.fill(tf.shape(self.cos_a_p),0)
expand_cos_ap = tf.expand_dims(self.cos_a_p,1)
expand_cos_an = tf.expand_dims(self.cos_a_n,1)
X = tf.concat([expand_cos_ap,expand_cos_an],1)
self.pred = tf.argmax(X,1)
correct_prediction = tf.equal(tf.cast(self.pred,tf.int32),self.y)
self.acc = tf.reduce_mean(tf.cast(correct_prediction,tf.float32),name="acc")
5.3 效果测评
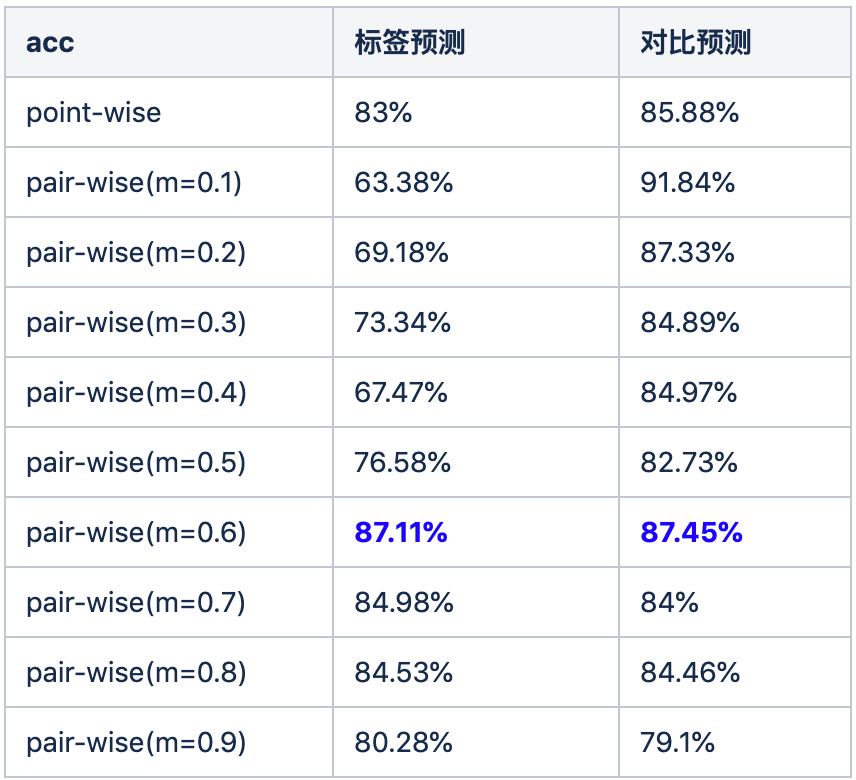
测评使用了标签预测(point-wise)和对比预测(pair-wise)的对比实验,参数m即为margin。其他实验参数:
-
embedding_dim:300
-
最大长度:20
-
lstm_hidden_size:100
-
batch_size:256
-
学习率:0.001
-
drop_out:0.9
-
epochs:15
-
标签预测: 两个query是否匹配,设置匹配阈值为0.5,相似度大于0.5为匹配,label为1,否则为不匹配,label为0。
-
对比预测: 判断三元组(anchor,positive,negtive)中,positive与anchor的相似度是否大于negtive与anchor的相似度。
5.4 思考分析
-
cosine的相似度的取值范围是[-1,1],在计算时应将其归一化到(0,1)的范围内,这样在计算loss时才能进行有效的反向传播。
-
实验数据未严格按照上文第三部分三元组的选择方法筛选三元组。由于同一知识下的部分标准问非常相近,有些仅一字之差,因此存在一部分训练数据 (0,1) 两个标签都可以,比如<anchor, positive, negetive>对应的<扫码支付佣金要收手续费吗,扫码支付中介费收手续费吗?,扫码支付中介费要手续费吗? >这个例子中,positive与negative的语义表示差别非常细微,人工也无法判断哪个是正确的标签,因此模型学起这样的case也会比较困难。另外从结果也可以看出,在pairwise的模型中,当m的值设的较小时,即cos(A,P)和cos(A,N)的差值较小时,对比预测的效果比较好,也验证了部分训练数据正负样本之间相差不大。 实验结果表明,用pairwise的方法训练,当m设为0.6时,在标签预测和对比预测上都取得了最好的效果。
-
设置一个合理的margin值很关键,这是衡量相似度的重要指标。margin值设的越小,loss很容易趋近于0,很难区分两个相似的query。margin值设的越大,loss值较难趋近于0,甚至导致网络不收敛,但可以比较有把握区分较为相似的query。
六、参考文献
-
https://blog.csdn.net/u013066730/article/details/88797338 -
https://omoindrot.github.io/triplet-loss -
https://www.jianshu.com/p/46c6f68264a1 -
https://zhuanlan.zhihu.com/p/136948465 -
https://www.jianshu.com/p/b1188c9f5fd2 -
https://www.zhihu.com/question/62486208/answer/199117070
作者介绍
卢新洁,2018年毕业于澳大利亚新南威尔士大学,毕业后加入贝壳找房语言智能部,主要从事NLP及智能客服相关工作。
戳下面👇
由于微信平台算法改版,公号内容将不再以时间排序展示,如果大家想第一时间看到我们的推送,强烈建议星标我们和给我们多点点【在看】。星标具体步骤为:
(1)点击页面最上方"AINLP",进入公众号主页。
(2)点击右上角的小点点,在弹出页面点击“设为星标”,就可以啦。
感谢支持,比心

推荐阅读
征稿启示| 200元稿费+5000DBC(价值20个小时GPU算力)
完结撒花!李宏毅老师深度学习与人类语言处理课程视频及课件(附下载)
模型压缩实践系列之——bert-of-theseus,一个非常亲民的bert压缩方法
文本自动摘要任务的“不完全”心得总结番外篇——submodular函数优化
斯坦福大学NLP组Python深度学习自然语言处理工具Stanza试用
关于AINLP
AINLP 是一个有趣有AI的自然语言处理社区,专注于 AI、NLP、机器学习、深度学习、推荐算法等相关技术的分享,主题包括文本摘要、智能问答、聊天机器人、机器翻译、自动生成、知识图谱、预训练模型、推荐系统、计算广告、招聘信息、求职经验分享等,欢迎关注!加技术交流群请添加AINLPer(id:ainlper),备注工作/研究方向+加群目的。

阅读至此了,分享、点赞、在看三选一吧🙏