【下载】PyTorch 实现的YOLO v2目标检测算法
【导读】目标检测是计算机视觉的重要组成部分,其目的是实现图像中目标的检测。YOLO是基于深度学习方法的端到端实时目标检测系统(YOLO:实时快速目标检测)。YOLO的升级版有两种:YOLOv2和YOLO9000。YOLOv2是针对YOLO算法不足的改进版本,作者使用了一系列的方法对原来的YOLO多目标检测框架进行了改进,在保持原有速度的优势之下,精度上得以提升。近日,Ruimin Shen在Github上发布了YOLO v2的PyTorch实现版本,让我们来看下。

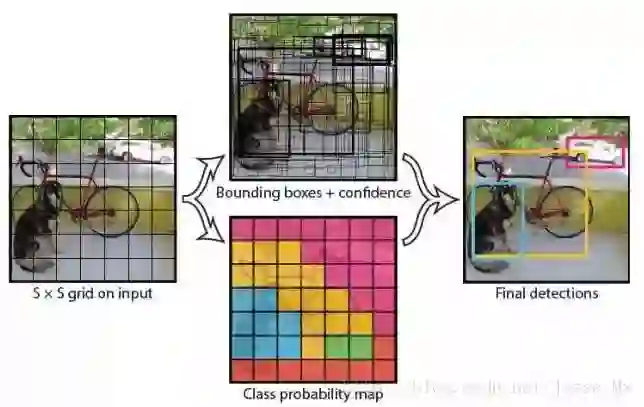
YOLO v2是目前最受欢迎的单一网络目标检测算法之一,由于整个检测流水线是单一网络,因此可以直接对检测性能进行端到端的优化。 本项目是对该算法的代码实现,为了提高效率,项目采用PyTorch开发框架。同时为了更方便的部署在实际应用中,可以利用ONNX将模型转换为Caffe 2支持的格式 。
▌设计
灵活的配置设计。 代码的运行是可配置的,比如可以使用命令行参数进行修改(可以通过配置文件重叠(-c / - 配置选项)或命令编辑(-m / - 修改选项)的方式)。
通过TensorBoard监控损失函数值和调试检测结果图像(例如IoU热图,标准数据集以及预测边界框)。
并行的模型训练设计。 不同的模型被保存到不同的目录中,从而可以同时训练。
使用NoSQL数据库存储具有高维信息的评估结果。这个设计在分析大量的实验结果时非常有用。
基于时间的输出设计。运行信息(例如模型,摘要summaries(由TensorBoard生成)以及评估结果)被定期保存到文件中。
对于检查点Checkpoint的管理。代码会将最近生成的几个检查点文件(.pth)保存在模型目录中,旧的将被删除。
NaN调试。当检测到NaN损失时,将导出当前的运行环境(data batch)和模型,用来分析NaN出现的原因。
统一的数据缓存设计。各种数据集通过相应的缓存插件转换为统一的数据缓存。 一些例如PASCAL VOC和MS COCO的插件已经实现。
任意可替换的模型插件设计。主要的深度神经网络(DNN)可以利用配置修改来轻松替换。其中已经包含了Darknet,ResNet,Inception v3、v4,MobileNet和DenseNet等模块。
可扩展的数据预处理插件设计。 原始图像(具有不同大小)和标签通过一系列操作进行处理从而形成一个训练批次(图像大小相同,边界框列表被填充)。 多个预处理插件已经实现, 例如同时处理图像和标签(如随机旋转和随机翻转),将图像和标签的大小批量调整为固定大小(如随机裁剪),增加没有标签的图像等(例如随机模糊,随机饱和度和随机亮度)。
▌项目特点
重现原始文件的训练结果。
多规模训练。
维度集群。
Darknet模型文件(.weights)解析器。
从图像和相机检测。
处理视频文件。
多GPU支持。
分布式训练。
焦点损失。
通道模型参数分析仪和修剪器。
▌快速开始
该项目需要使用Python 3去安装依赖库,在终端键入以下命令:
sudo pip3 install -r requirements.txt
quick_start.sh包含执行检测和评估的示例。 运行这个脚本。 将下载多个数据集和模型(原始的Darknet格式,将被转换成PyTorch的格式)。 这些数据集将缓存到不同的数据配置文件中,模型会对缓存的数据进行评估。并用于检测示例图像中的对象,并显示检测结果。
链接:https://github.com/ruiminshen/yolo2-pytorch
-END-
专 · 知
人工智能领域主题知识资料查看获取:【专知荟萃】人工智能领域26个主题知识资料全集(入门/进阶/论文/综述/视频/专家等)
同时欢迎各位用户进行专知投稿,详情请点击:
【诚邀】专知诚挚邀请各位专业者加入AI创作者计划!了解使用专知!
请PC登录www.zhuanzhi.ai或者点击阅读原文,注册登录专知,获取更多AI知识资料!

请扫一扫如下二维码关注我们的公众号,获取人工智能的专业知识!

请加专知小助手微信(Rancho_Fang),加入专知主题人工智能群交流!

点击“阅读原文”,使用专知!