
视觉问答:从早期发展到最新进展——综述

**摘要
随着多模态数据研究的快速发展,视觉问答(VQA)吸引了研究界的广泛关注。VQA 是一个不断发展的研究领域,旨在使机器能够回答关于视觉内容的问题。该任务需要推理能力,并结合图像和语言处理技术,包括特征提取、目标检测、文本嵌入、自然语言理解和语言生成。VQA 的应用范围广泛,从创建交互式教育工具、诊断医学图像、辅助客户服务,到增强娱乐体验和生成社交媒体内容的标题。VQA 还可以帮助和支持盲人和视障人士通过自然语言描述“看到”图像,为他们提供原本无法感知的视觉内容。在本综述论文中,我们基于 VQA 架构的关键组件和设计选择,提出了一个分类法,为比较和评估不同的 VQA 方法提供了一个结构化框架。然后,我们分析了各种 VQA 方法,包括基于深度学习的方法,并对该领域的当前状态进行了批判性回顾。我们还回顾了大型视觉语言模型(LVLM)这一新兴领域,这些模型在各种多模态任务(如 VQA)中展示了有希望的结果。此外,我们审查了现有的 VQA 数据集和用于评估 VQA 系统性能的评估指标,然后讨论了 VQA 在各个领域中的一些实际应用。最后,我们讨论了 VQA 研究的当前挑战和未来方向,包括开放的研究问题和潜在的应用。本综述论文为研究人员和实践者提供了宝贵的资源,帮助他们了解 VQA 的最新技术水平,并探索 VQA 的未来研究机会。
**关键词
视觉问答、多模态计算、计算机视觉、自然语言处理、人工智能应用、机器学习、深度学习
1 引言
人类能够通过各种感官模态(如听觉、嗅觉、视觉和触觉)处理来自周围环境的信息。尽管这些类型的数据是单独吸收的且不兼容,但人类具有显著的能力来对齐和融合它们,以更好地感知和理解周围的世界。例如,当观看电视节目时,人类可以同时处理节目的视觉和听觉组件,以增强对内容的理解和享受。这种不同感官模态的整合对于我们作为人类有效感知和解释世界的能力至关重要,并突显了人脑的惊人灵活性和适应性。 多模态计算是一个吸引了研究界广泛关注的领域,旨在通过在机器中开发能够整合来自多个来源(如图像、音频和文本)信息的算法来复制这种能力。通过使机器能够处理来自不同模态的信息,多模态计算可以增强它们以更类似人类的方式理解和与世界互动的能力。这种方法为创建能够实现计算机以前无法实现的新能力的先进算法铺平了道路。例如,计算机现在可以找出图像中哪个对象与文本查询最相关。这种不同感官模态的整合对于开发更智能和直观的机器至关重要,并有可能改变许多行业,从医疗保健到娱乐。 视觉问答(VQA)是多模态视觉语言(VL)任务的一个例子,它结合了计算机视觉和自然语言处理技术,使机器能够回答关于视觉内容的问题。例如,如图 1 所示,给定一张“辛普森一家”电视节目的图像和一个自然语言问题,如“霍默戴帽子了吗?”,VQA 系统应该能够识别图像中的“霍默”并生成正确答案“否”。在各种大规模数据集的支持下,VQA 任务在多种应用中取得了显著进展,包括创建交互式教育工具、诊断医学图像、辅助客户服务、增强娱乐体验和生成社交媒体内容的标题。VQA 被广泛认为是 VL 计算领域中最具挑战性的任务之一,特别是与其他 VL 任务(如视觉定位和视觉字幕生成)相比。其中一个原因是 VQA 的输入问题形式比其他 VL 任务更加多样化。虽然其他任务(如视觉定位)中的文本查询是固定的,并描述图像中的特定对象或特征,但 VQA 问题在格式和内容上可以有很大的差异。表 1 提供了按各自 AI 问题领域组织的 VQA 问题示例,我们观察到 VQA 可以解决广泛的 AI 问题,包括图像分类、目标检测、计数、场景分类、属性分类、活动识别和推理理解。
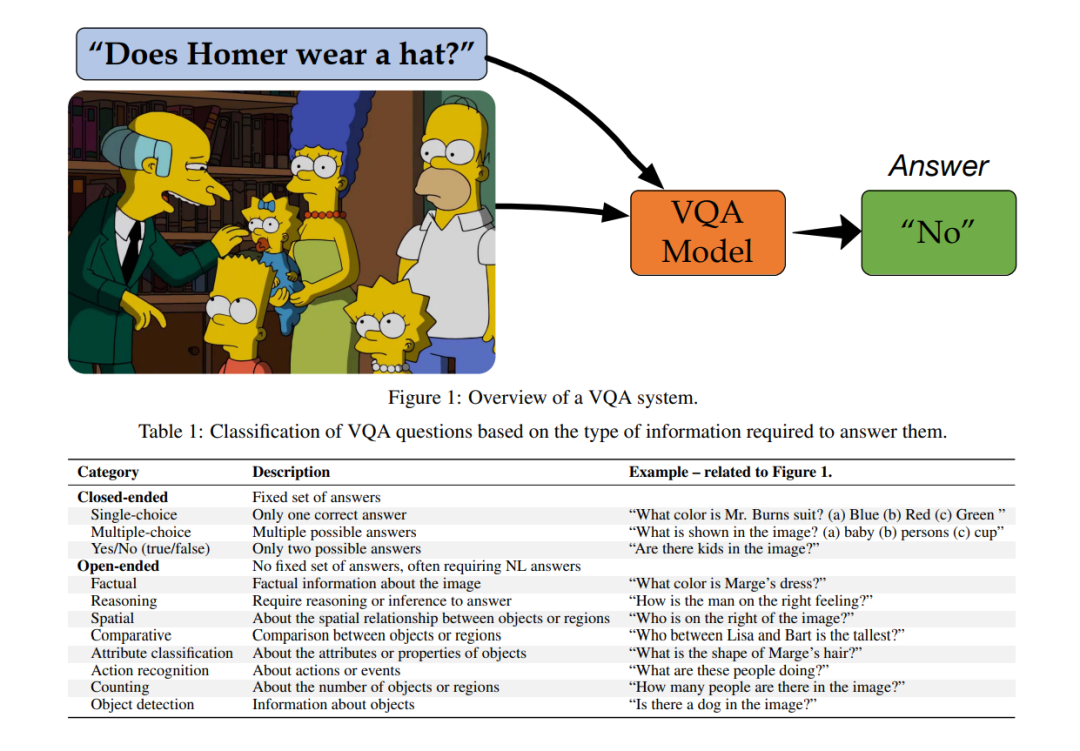
近年来,已经发表了几篇关于 VQA 的综述论文,以回顾和评估 VQA 的不同方面(例如,Zhang 等人(2019);Kallooriyakath 等人(2020);Manmadhan 和 Kovoor(2020);Zou 和 Xie(2020);Sharma 和 Jalal(2021))。特别是,Zhang 等人(2019)和 Kallooriyakath 等人(2020)专注于回顾现有的融合技术,而 Manmadhan 和 Kovoor(2020)提供了 VQA 的全面视图,涵盖了视觉编码器、语言编码器、融合策略、数据集和评估指标。Zou 和 Xie(2020)回顾了可用的 VQA 数据集及其局限性。Sharma 和 Jalal(2021)将他们的综述扩展到传统 VQA 模型之外,并包括文本 VQA 和基于知识的 VQA。 然而,随着该领域的快速发展,结合新技术、模型和数据集的引入,我们认为有必要对该主题进行最新和全面的综述。首先,上述综述仅关注 VQA 的特定方面,如融合技术或数据集,并未提供该领域的全面视图。其次,随着 LVLM(视觉语言预训练)模型(如 ViLBERT(Lu 等人,2019)、VisualBERT(Li 等人,2019a)和 VL-BERT(Su 等人,2019))的引入,VQA 模型取得了显著进展。这些模型在大量图像和语言数据上进行预训练,以学习视觉和语言的联合表示,然后在视觉语言任务(如 VQA)上进行微调。通过这样做,这些模型显著提高了 VQA 任务的准确性。据我们所知,这些模型尚未在任何现有综述中得到回顾。第三,VQA 已应用于医疗保健、教育和客户服务等不同领域,这些领域具有独特的挑战,需要特定的解决方案。最后,VQA 的实际应用已扩展到更复杂的任务,如多模态对话系统和开放域 VQA,这些任务需要与传统 VQA 不同的方法。因此,有必要对 VQA 进行新的综述,涵盖最新进展、实际应用和新兴趋势,为研究人员和实践者提供该领域的全面概述。 本文的其余部分组织如下:首先,第 2 节介绍了我们在本文中讨论的 VQA 任务,并基于视觉编码器、语言编码器以及融合图像和问题特征以生成答案的技术(包括 LVLM 模型)提出了 VQA 系统的分类法。接下来,第 4 节探讨了 VQA 研究中最广泛使用的一些数据集。然后,第 6 节讨论了 VQA 模型最常用的评估指标。第 7 节概述了 VQA 在医学成像、视障人士、文化遗产、广告和教育等领域的各种实际应用。第 8 节基于准确性分析和比较了现有的 VQA 模型,并提出了构建 VQA 模型和实际 VQA 应用的未来工作方向。最后,第 9 节总结了本文。
2 VQA 任务及常见架构的分类法
VQA 是一项要求系统融合来自视觉和语言模态的信息以生成单个答案的任务,使其成为多模态计算任务的典型例子。多年来,VQA 的各个子领域引起了研究人员的关注。这些子领域包括 OCR-VQA(或文本 VQA)、基于知识的 VQA(或 KB-VQA)和答案定位 VQA,这些任务需要额外的技术或知识来回答与图像相关的问题。OCR-VQA 涉及将光学字符识别(OCR)技术集成到 VQA 模型中,以识别和解释图像中的文本以回答问题(Singh 等人,2019;Wang 等人,2022;Mishra 等人,2019;Tanaka 等人,2021;Biten 等人,2019;Mathew 等人,2021)。另一方面,KB-VQA 利用来自维基百科等来源的外部知识来回答超出图像信息的复杂问题(Wang 等人,2015;Wu 等人,2016;Marino 等人,2019;Schwenk 等人,2022)。最后,答案定位 VQA 识别图像中的相关区域或对象以回答问题,而不是像其他 VQA 系统那样提供文本答案(Chen 等人,2022;Ustalov 等人,2023)。本文的主要重点是调查传统的 VQA 任务,该任务涉及在给定自然语言问题和相关图像的情况下提供准确的自然语言答案。
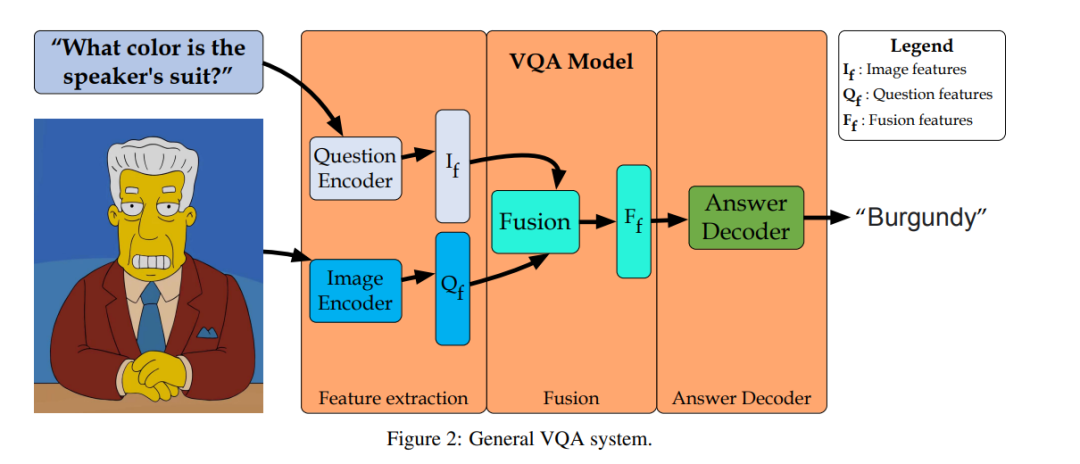
如图 2 所示,典型的 VQA 系统通常由三个阶段组成:特征提取、融合和答案解码器。前两个步骤分别涉及从输入图像和问题中提取视觉特征和文本表示。视觉编码器负责使用计算机视觉技术(如 CNN、视觉 Transformer 等)从图像中提取视觉特征。另一方面,语言编码器使用自然语言处理(NLP)技术(如 RNN、Transformer 等)从输入问题中提取文本表示。关于这两个编码器的更多详细信息可以在第 3.1 节和第 3.2 节中找到。然后,图像和语言编码器的输出向量通过融合组件进行组合,使用诸如逐元素乘积或连接等技术(Antol 等人,2015b)。生成的融合向量随后通过答案解码器生成给定问题的答案。有关此过程的更多信息可以在第 3.3 节中找到。通过使用此框架,VQA 系统可以处理各种问题和图像,使其适用于不同的场景。 在以下小节中,我们将介绍在操作 VQA 系统时涉及的每个步骤中使用的主要技术。这些技术也在图 3 所示的通用分类法中进行了总结。
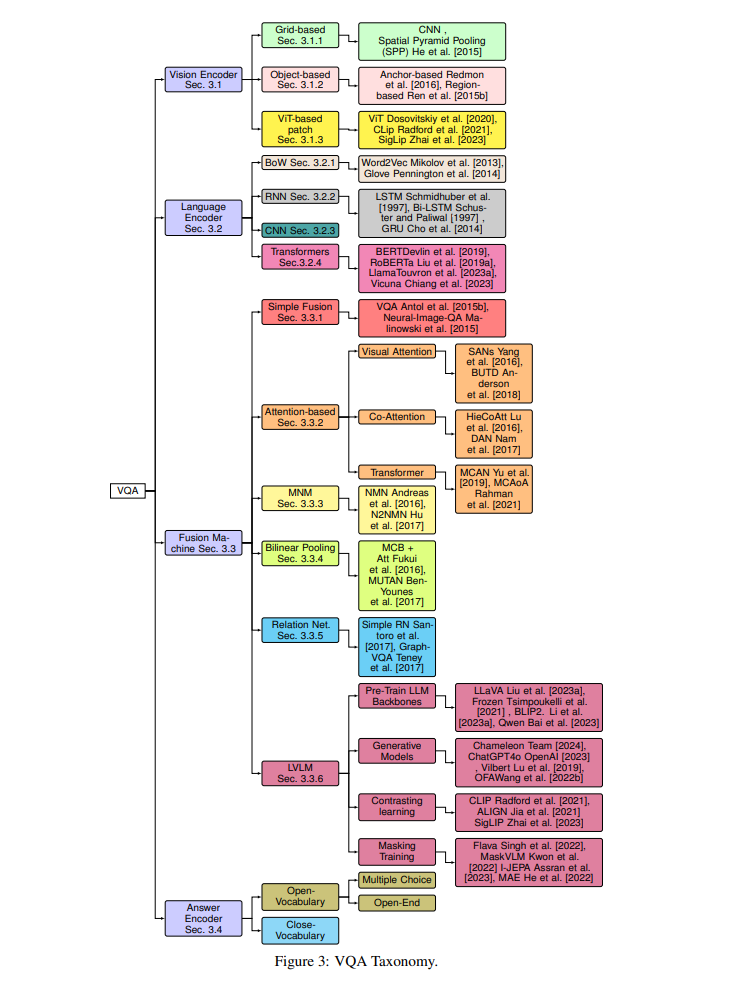
3 VQA 架构
VQA 是由 Antol 等人(2015b)首次引入的任务,是人工智能中的一项任务,涉及回答关于图像的自然语言问题。它要求系统具有广泛的知识,并能够对图像内容进行推理以提供准确的答案。VQA 系统通常由四个主要组件组成:视觉编码器、语言编码器、融合机和答案解码器(如图 2 所示)。在本节中,第 3.1 和 3.2 小节包括用于提取图像表示和问题表示的技术。第 3.3 小节包括用于组合图像和问题表示的模型的分类法。最后,答案解码器在第 3.4 小节中讨论。 本部分的组织遵循图 2 中描述的操作 VQA 系统的三个主要步骤:图像和问题特征提取分别在 3.1 和 3.2 节中,融合在 3.3 节中,答案解码器在 3.4 节中。
**3.1 视觉编码器
视觉编码器是 VQA 系统的关键组件,因为它从输入图像中提取重要的视觉特征,并以简洁且有意义的方式对其进行编码。视觉编码器的输出随后被输入到融合模块中,与问题嵌入结合以生成给定问题的答案预测。下面,我们将讨论基于图像编码方式的视觉编码器的三个类别。
3.1.1 基于网格的编码器
在 VQA 系统中,基于网格的编码器是指将输入图像划分为网格单元并独立处理每个单元的视觉编码器。这种方法的基本原理是图像的不同单元可能包含与回答给定问题相关的独特视觉信息。从每个单元中提取的视觉特征随后被组合以生成输入图像的潜在表示。 卷积神经网络(CNN)是基于网格的编码器的典型例子。近年来,已经开发了几种基于 CNN 的图像分类模型,通常使用大规模图像数据集(如 ImageNet)进行预训练(Deng 等人,2009)。在这些模型中,VGGNet(Simonyan 和 Zisserman,2015)、ResNet(He 等人,2016)和 GoogleNet(Szegedy 等人,2015)由于其流行性和有效性而被广泛用作视觉编码器。 另一方面,空间金字塔池化(SPP)(He 等人,2015)已被用于 VQA 中,以从图像的各个单元中提取特征。空间金字塔池化层用于在多个尺度上组合每个单元的特征。这使得模型能够从图像中捕获局部和全局视觉信息,这对于准确回答问题非常重要(Jiang 等人,2020;Banerjee 等人,2021;Yu 等人,2023a)。 此外,空间变换网络(STN)(Jaderberg 等人,2015)已被用于 VQA 中,以在编码之前动态变换输入图像以增强其显著特征。STN 允许网络学习空间变换,这些变换可以将图像区域与相应的问题语义对齐,从而提高 VQA 系统的整体性能(Butt 等人,2017)。
3.1.2 基于对象的编码器
基于对象的 VQA 模型的基本思想是捕获图像中对象之间的关系及其与给定问题的相关性,因为对象通常是 VQA 问题的主要焦点。通过定位对象并提取其特征,这些模型可以更好地理解问题的视觉上下文并生成更准确的答案。在 VQA 中,已经使用了各种技术来识别和定位图像中的对象(Gordon 等人,2018;Anderson 等人,2018;Guo 等人,2023)。基于区域的方法使用区域提议网络生成图像中一组候选对象边界框,然后使用分类器预测每个对象在提议框中的类别和位置。Faster-RCNN(Ren 等人,2015b)是一种常用的基于区域的方法,用于检测输入图像中的重要对象。单次方法在一次神经网络前向传递中完成对象检测和分类。它们通常使用一组默认的边界框形状(称为锚点)来预测每个锚点的类别和位置偏移。YOLO(Redmon 等人,2016)是单次方法的一个例子。基于锚点的方法也使用锚点框来预测对象位置和类别,但它们在多个尺度和纵横比上创建锚点框,以更好地处理不同大小和形状的对象。RetinaNet(Lin 等人,2017)是一种基于锚点的方法。使用骨干 CNN 模型(如 VGGNet(Simonyan 和 Zisserman,2015)或 ResNet(He 等人,2016))提取检测到的边界框的视觉特征,这些特征有助于识别对象属性、数量和类别以进行准确推断(Anderson 等人,2018)。值得注意的是,由于使用基于对象的视觉编码器的 VQA 模型是两阶段模型,因此它们无法进行端到端训练。
3.1.3 基于 ViT 的补丁编码器
受视觉 Transformer(ViT)(Dosovitskiy 等人,2020)的启发,基于 ViT 的补丁编码器将图像分割成小块并线性嵌入它们以创建补丁嵌入。为了生成总结整个输入序列的单个特征向量,在输入序列的开头添加了一个可学习的标记。 一些 VQA 模型,如 ViLT(Kim 等人,2021)和 VLMo(Bao 等人,2021),将补丁嵌入与问题标记结合并输入到多层 Transformer 块中。然而,其他模型如 X-VLM(Zeng 等人,2022a)和 X2-VLM(Zeng 等人,2022b)独立地将补丁嵌入发送到多层 Transformer 块中以生成最终的输出图像特征。这种方法在 VQA 任务中展示了有希望的结果,允许更灵活和高效的图像处理。 最近,使用来自预训练模型(如 CLIP(Radford 等人,2021)、ALIGN(Li 等人,2021)和 SigCLIP(Zhai 等人,2023))的编码器获得了关注,因为它们提供了强大且高质量的视觉特征,显著提高了性能。这些模型有效地将图像与文本对齐,使其与自然语言查询高度兼容。将这些编码器集成到 VQA 模型中提高了准确性和鲁棒性,减少了对广泛任务特定训练的需求,并在各种基准测试中实现了最先进的性能,推动了 VQA 能力的发展。 除了上述模型外,一些方法还适应了其他类型的计算机视觉模型,如分割(Kirillov 等人,2023)和深度估计(Birkl 等人,2023),或将不同的视觉编码器结合在一起,如最近的趋势(Lee 等人,2024;Tong 等人,2024)。
**3.2 语言编码器
在 VQA 系统中,语言编码器负责将问题的原始文本转换为数值潜在表示。通常,它利用自然语言处理(NLP)技术来检查问题的结构和意义。已经应用了不同的技术来获取问题特征,如下所述。3.2.1 词袋(BoW)
是最简单的问题编码方法。首先,从所有问题中的单词创建一个固定词汇表。对于每个问题,通过计算词汇表中每个单词的频率并将其表示为直方图来生成特征向量。这种方法无法编码相邻单词之间的依赖关系。
3.2.2 循环神经网络(RNN)
是 VQA 中最流行的语言编码器之一。这种方法可以捕获输入问题的文本结构和单词依赖关系。问题首先通过独热编码处理,然后传递到可以使用预训练模型(如 GloVE(Pennington 等人,2014))或从 word2vec(Mikolov 等人,2013)中提取的词嵌入层,也可以在训练过程中从头开始训练。之后,这些词嵌入被馈送到 RNN,如长短期记忆(LSTM)(Schmidhuber 等人,1997)、双向 LSTM(biLSTM)、门控循环单元(GRU)(Cho 等人,2014)和 Skip-thought 向量(Kiros 等人,2015),以提取问题的上下文表示。
3.2.3 卷积神经网络(CNN)
可以通过使用卷积滤波器从输入问题的局部区域提取特征来编码问题表示(Yang 等人,2016)。问题也首先通过独热编码处理,然后传递到词嵌入层。这些词嵌入随后被馈送到一个 2D 矩阵中,其中每一行代表一个单词。然后,2D 矩阵通过几个卷积层和最大池化层以提取问题表示。
3.2.4 Transformer
(Vaswani 等人,2017)在 NLP 任务中最为流行,毫不奇怪,Transformer 网络已成为在 VQA 中提取问题表示的流行方法。遵循 BERT(Devlin 等人,2018)和 RoBERTa(Liu 等人,2019b),输入问题被分解为更小的子词或标记,使用 WordPiece 标记化。标记化的输入随后被映射到高维向量嵌入,这些嵌入捕获了每个标记在周围文本上下文中的语义意义。在嵌入的开头插入一个特殊的可学习标记 [CLS],以在训练期间总结整个输入序列。一方面,这些词嵌入可以与视觉标记连接,然后直接馈送到使用 BERT 或 RoBERTa 初始化的多层 Transformer 块中,如 ViLT(Kim 等人,2021)和 VLMo(Bao 等人,2021)。另一方面,它们被发送到语言模型(如 BERT、RoBERTa、mT5(Xue 等人,2020)或 Llama 家族(Touvron 等人,2023b))中,首先捕获语言特征,然后与视觉特征交互。
**3.3 多模态融合
融合机是 VQA 系统的关键元素,旨在将来自视觉编码器的图像表示和来自问题解码器的问题表示作为输入,并提供融合的多模态特征作为输出。本节将提供融合技术的分类法,从简单的操作(如连接或逐元素乘法)到复杂的注意力机制。我们将融合技术分为五类:简单融合、注意力、双线性池化、神经模块网络和视觉语言预训练模型。3.3.1 简单融合 在早期的工作中,图像和问题特征使用简单的操作(如逐元素乘法、求和或连接)进行融合(Antol 等人,2015b;Jabri 等人,2016;Saito 等人,2017)。除此之外,还使用了一些稍微复杂的方法,如 CNN(Ma 等人,2016)、LSTM(Malinowski 等人,2015;Ren 等人,2015a;Gao 等人,2015)和贝叶斯模型(Kafle 和 Kanan,2016)。然而,这些简单的融合技术在某些情况下表现较差。首先,它们无法捕获视觉和文本输入之间复杂的关系,这对于准确的 VQA 是必要的。其次,简单的融合技术无法提供关于视觉和文本输入如何组合的见解,使得难以理解 VQA 系统如何得出其答案。3.3.2 基于注意力的方法 注意力机制最初由 Bahdanau 等人(2014)引入,主要用于在翻译机器中将源语言输入对齐并翻译为目标语言输出。换句话说,注意力机制旨在专注于输入数据的某些部分,而不是一次考虑整个输入。在 VQA 中,注意力机制旨在在生成答案时选择性地关注基于网格模型中的最相关区域特征或基于对象模型中的对象。更具体地说,VQA 需要学习图像的关键区域部分或对象以及关键词。例如,我们假设图像包括右侧的黄色狗和左侧的黑色狗,给定问题“左侧的狗是什么颜色”。对于图像,注意力机制的责任是允许 VQA 更多地关注左侧的狗而不是右侧的狗或图像的其他部分。对于问题,VQA 需要关注关键词,包括“颜色”、“左侧”和“狗”。与简单融合相比,基于注意力的模型达到了更高的性能。 在 VQA 中使用注意力机制有几种方法: 视觉注意力: 引导注意力是指使用注意力机制帮助模型在生成关于图像的问题答案时专注于图像的特定部分。注意力机制由问题引导,问题被用作查询以将模型的注意力引导到图像的相关区域。Yang 等人(2016)提出了堆叠注意力网络(SANs),它使用 softmax 函数堆叠注意力网络以进行多步推理,根据给定问题选择视觉信息中的狭窄区域。之后,将残差网络应用于 SANs 以提高性能(Kim 等人,2016a)。受端到端记忆网络(Sukhbaatar 等人,2015)的启发,Xu 和 Saenko(2016)提出了空间记忆网络(SMem-VQA),它在第一次跳跃中使用空间注意力计算图像表示与问题中单个单词的相关性。在第二次跳跃中,视觉和问题被组合,然后再次循环到注意力机制中以细化注意力分布。类似地,Xiong 等人(2016)提出了基于动态记忆网络(Kumar 等人,2016)的 DMN+,该网络来自文本 QA。与均匀网格特征不同,另一种实现注意力的方法是生成图像中的所有边界框,然后使用问题引导的视觉注意力来确定相关框(Shih 等人,2016;Ilievski 等人,2016;Anderson 等人,2018;Teney 等人,2018;Song 等人,2018)。 共同注意力: 共同注意力机制允许模型同时关注视觉和文本输入。换句话说,该机制使用视觉表示来引导问题注意力,并使用问题表示来引导视觉注意力。Lu 等人(2016)提出了第一个名为 HieCoAtt 的共同注意力机制,用于 VQA,以同时产生对图像特征和问题的注意力。之后,Kim 等人(2018)通过发布双线性注意力网络(BAN)改进了之前的模型;该网络通过将共同注意力应用于双线性注意力来创建,双线性注意力考虑了每个问题单词和图像区域的配对。Nguyen 等人(2018)还表示,HieCoAtt 仅考虑来自完整句子的视觉注意力和整个图像上的语言注意力,导致性能限制。因此,他们提出了密集共同注意力网络(DCN),该网络堆叠多个密集共同注意力层以重复融合语言和视觉表示。此外,密集共同注意力层是密集的,考虑了任何单词和任何区域之间的每次交互。 Transformer: 尽管上述共同注意力模型表现出稍好的性能,但它们的瓶颈是它们限制了每个模态内的自注意力能力,例如问题中的单词到单词关系和图像中的区域到区域关系。因此,受 Transformer(Vaswani 等人,2017;Yu 等人,2019)的启发,Yu 等人(2019)引入了 MCAN,它使用 Transformer 的自注意力单元来获取单词到单词关系和区域到区域关系。此外,作者还使用引导注意力单元来获取交叉注意力,例如单词到区域关系。MCAN 采用两种架构(堆叠和编码器-解码器),由多个 MCA 层级联而成,以逐步细化注意的图像和问题特征。结果表明,编码器-解码器 MCAN 架构优于其他架构和现有模型。之后,Rahman 等人(2021)提出了 MCAoAN,它通过使用注意力上的注意力(Huang 等人,2019)扩展了 MCAN。Zhou 等人(2021)随后引入了第一个示例依赖路由方案,用于动态调度 Transformer 中的全局和局部注意力,称为 TRAR。这些模型证明,Transformer 是融合语言和问题特征的更好方法,优于其他基于注意力的方法。Steitz 等人(2022)提出了一个名为 TxT 的端到端网络,基于称为 DETR 的基于 Transformer 的目标检测器。该模型在 VQA 准确性方面显示出明显的改进,与 Fast R-CNN 特征相比。3.3.3 神经模块网络(NMNs)
除了基于注意力的模型外,另一种提高 VQA 性能的方法是神经模块网络(NMNs)。特别是,VQA 中的输入问题可能需要多步推理才能正确回答。例如,问题“冰箱上的物体是什么?”需要一些步骤:首先是找到冰箱,然后识别桌子上的物体。NMNs 专门设计用于处理问题的组合结构。 NMNs 的架构由一组称为“模块”的浅层神经网络组成。每个神经网络设计用于执行单个明确定义的任务。这些模块以不同的方式组合和连接,形成针对每个输入问题的实例特定网络。Andreas 等人(2016)使用自然语言解析器找到问题的子任务,并推断出子任务的网络,当按顺序执行时,将生成给定问题的答案。该架构无法进行端到端训练,因为它涉及两个阶段:程序合成和程序执行。因此,IPE(Johnson 等人,2017a)和 N2NMNs(Hu 等人,2017)被提出,通过强化学习使端到端可训练的 NMNs 来解决先前工作的局限性。后来,Stack-NMN(Hu 等人,2018)进行了软布局选择,使得整个模型完全可微分。最后,神经符号 VQA 模型(Yi 等人,2018;Vedantam 等人,2019)通过将图像编码为场景图来执行符号推理。3.3.4 双线性池化方法
VQA 强烈依赖于连接图像和问题特征的方式。早期模型使用简单的操作(如连接和逐元素乘积)在问题和图像特征之间进行连接。然而,这些操作在捕获图像和问题特征之间的复杂关系方面不够有效。双线性池化是一种创建输入之间更复杂交互的简单方法。 首先,Fukui 等人(2016)提出了多模态紧凑双线性(MCB)池化来压缩双线性模型。然而,在原始问题和图像特征上使用外积将是非常高维的,导致参数数量不可行,因此他们使用计数草图函数(Charikar 等人,2002)和快速傅里叶变换(FFT)来生成一个低维空间,以避免直接计算外积。然而,这种方法仍然计算昂贵,因为 MCB 使用近似外积。因此,多模态低秩双线性池化(MLB)(Kim 等人,2016b)使用 Hadamard 乘积来生成低秩双线性池化。然而,Yu 等人(2017)指出,尽管 MLB 提供了低维特征,参数较少,并且达到了比 MCB 更高的性能,但 MLB 收敛速度慢,并且对学习的超参数敏感。因此,创建了多模态因子分解双线性池化(MFB)以克服 MCB 和 MLB 的局限性。首先,视觉和语言特征被扩展到更高维空间,然后使用求和池化层压缩为密集输出特征。其他更高级的双线性池化方法包括 MUTAN(Ben-Younes 等人,2017)、Film(Perez 等人,2018)和 BLOCK(Ben-Younes 等人,2019)。3.3.5 关系网络
关系推理是指机器学习模型理解和推理对象或实体之间关系的能力。这涉及识别对象之间的模式和连接,并使用这些模式进行预测或决策。对象之间的关系可能是简单的二元关系(例如,这两个对象颜色相同吗?)或更复杂的多类关系(例如,“这两个对象之间的关系是什么?”)。关系网络旨在学习和推理对象之间的关系。 Santoro 等人(2017)考虑了图像区域之间的关系,在问题上下文的条件下构建了一个通用的成对关系网络。因为他们使用 CNN 提取图像特征,对象可能是背景或物理对象。尽管这种架构提高了 VQA 性能,但它仅提取了表面关系。Teney 等人(2017)使用斯坦福依赖解析器获取问题的图表示。然后,他们提出了一种基于图的方法,利用图神经网络结合抽象图像和问题的图表示。他们的模型实现了高性能,但使用了抽象图像的场景图表示。因此,将其应用于现实世界的图像是困难的。3.3.6 大型视觉语言模型
大型语言模型(LLMs)通过利用大量数据集学习复杂表示,显著提高了各种任务的性能,从而彻底改变了 AI。基于 LLMs 在 NLP 中的成功,研究人员自 2019 年以来开发了视觉语言预训练(LVLM)模型。这些模型在大规模视觉和语言数据集上进行训练,以捕获跨模态关系,从而提高了图像字幕生成和 VQA 等任务的性能。LVLM 模型分为四种训练方法:对比训练、掩码训练、预训练骨干和生成模型。 对比学习(LeCun 等人,2006)是一种机器学习范式,其中未标记的数据点被比较以教导模型哪些点是相似的,哪些是不同的。换句话说,属于同一分布的样本在嵌入空间中被拉近,而来自不同分布的样本被推开。这种方法可以利用大量未标记的数据,消除了监督学习中通常需要的大量标记数据集的需求。 对比学习(LeCun 等人,2006)对比语言-图像预训练(CLIP)(Radford 等人,2021)是一个著名的对比学习模型,它将图像及其相应的字幕映射到相似的向量,而不相关的则映射到遥远的向量。这种能力使模型能够理解和检索基于文本查询的图像,反之亦然。然而,虽然对比学习将图像和文本对齐在共享嵌入空间中,但它缺乏复杂推理任务(如 VQA)所需的细粒度理解和显式答案预测机制。因此,CLIP 通常用于提取丰富的图像特征,这些特征可以馈送到专门为 VQA 等任务设计的其他模型中,利用其强大的视觉表示同时解决其局限性。其他类似的方法包括 ALIGN(Jia 等人,2021)、SLIP(Mu 等人,2022)、SigLIP(Zhai 等人,2023)和 Llip(Lavoie 等人,2024)。 掩码训练: 受 BERT 在掩码语言建模(MLM)(Devlin 等人,2018)中的成功启发,类似的技术被用于视觉语言模型(LVLMs)。掩码训练涉及在训练期间掩码图像和句子的部分,类似于 MLM 在文本中掩码单词。图像块被随机丢弃,迫使模型从周围上下文中预测缺失的视觉信息,而文本中的掩码单词则基于周围单词进行预测。这种方法增强了模型从不完整输入生成连贯表示的能力,提高了其上下文理解和鲁棒性(Singh 等人,2022;Kwon 等人,2022;Assran 等人,2023;He 等人,2022)。 生成模型: 生成 LVLMs 通过利用其生成字幕和图像的能力,在 VQA 中展示了显著进展。最初,模型专注于使用完整的编码器-解码器架构生成描述性字幕的文本任务(Lu 等人,2019;Tan 和 Bansal,2019;Yu 等人,2022)。然而,最近的发展扩展了它们的能力,包括图像生成,如 Stable Diffusion(Sauer 等人,2024;Stability.ai,2024)等模型所示。这种多模态熟练度使 ChatGPT(OpenAI,2023)和 Chameleon(Team,2024)等模型在 VQA 任务中表现出色,在这些任务中,理解和生成视觉和文本信息至关重要。这些进展使得对视觉查询的回答更加准确和上下文相关,从而提高了 VQA 系统的整体有效性。 预训练骨干: 从头开始训练涉及显著的成本,包括需要大量的视觉语言数据和数百到数千个 GPU 的计算能力。然而,许多 LLMs 是开源的,更容易访问,导致通过使用将视觉标记映射到语言标记的适配器对现有 LLMs 进行微调,使其成为 LVLMs。这些适配器作为桥梁,使模型能够有效地处理和理解图像和语言模态。开源 LLMs 如 Llama、Owen 和 Falcon 可以用作此目的的骨干(Meta,2023;Bai 等人,2023;TII,2024)。适配器可以采取各种形式,包括简单的多层感知器(MLPs)(Tsimpoukelli 等人,2021;Liu 等人,2024a;Zhu 等人,2023)、感知器重采样器(Alayrac 等人,2022)和 Q-Formers(Li 等人,2023a)。这种使用适配器进行微调的趋势具有几个优势。微调预训练模型所需的计算能力和数据显著少于从头开始训练,使其更具可访问性和成本效益。
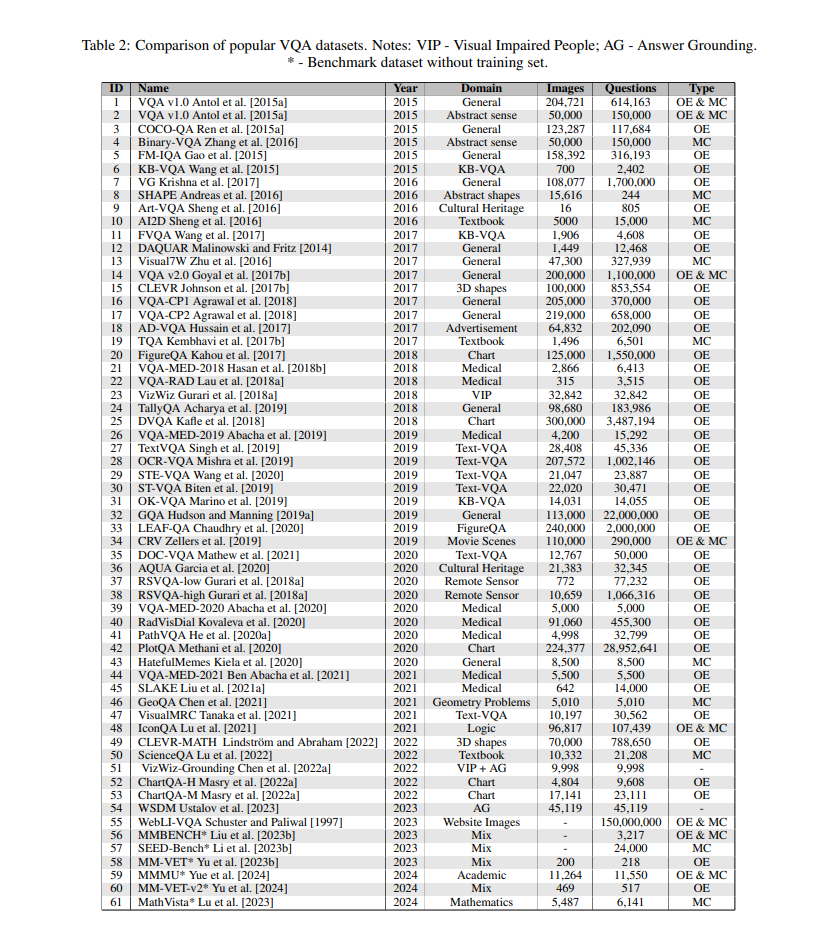
4 数据集
VQA 是一项具有挑战性的跨学科任务,位于计算机视觉和自然语言处理的交叉点。VQA 数据集通过提供多样化和注释的数据用于训练和评估 VQA 模型,在推进该领域的最新技术水平方面发挥着至关重要的作用。在本节中,我们将回顾一些现有的和著名的 VQA 数据集。
**4.1 VQA 数据集
VQA 数据集是用于 VQA 任务的大规模数据集。它由图像、相关问题和答案组成,用于训练和评估 VQA 模型。该数据集是创建和验证 VQA 模型的最受欢迎的数据集之一。多年来,已经开发了各种版本的 VQA 数据集。 VQA v1.0(Antol 等人,2015b): 这是原始的 VQA 数据集,包含来自 MS COCO 数据集(Lin 等人,2014)的 204,721 张真实世界图像和 614,163 个问题。此外,该数据集还包含 50,000 个抽象场景和 150,000 个问题。每个问题有来自 10 个人的 10 个答案,具有不同的置信度。VQA v1.0 包含真实世界和抽象图像的开放式和多项选择题。然而,部分问题是在不看图像的情况下回答的,导致语言偏差。 VQA v2.0(Goyal 等人,2017b): 由于 VQA v1.0 数据集具有强烈的语言偏差,VQA v2.0 被提出以解决此问题。该数据集包含两倍于旧版本的问题-答案对,有 200K 图像和 1.1M 问题-答案对。每张图像有三个问题,每个问题也有十个答案。VQA v2.0 包含开放式和多项选择题。此版本现在比旧版本更常用。
**4.2 Visual Genome
Visual Genome(Krishna 等人,2017)是一个大规模的视觉知识库,提供有关图像中对象、属性和关系的信息。它被设计为各种计算机视觉和自然语言处理任务(如图像字幕生成、VQA 和图像检索)的资源。 Visual Genome 包含 108,077 张图像,每张图像平均有 35 个对象、26 个属性和 21 个这些对象之间的成对关系。问题必须以六个字母之一开头:what、where、how、why、who 和 when。问题必须清晰、直接、精确,并且仅与图像中呈现的内容相关。有两种类型的问题回答:自由形式和基于区域的问题回答。对于自由形式的问题回答,数据标注者必须自由地写出关于图像中所有内容的八个问题-答案对。另一方面,对于基于区域的问题回答,数据标注者必须根据给定对象写出一个问题-答案对。一般来说,自由形式的问题回答具有更多样化的问题-答案对,但基于区域的问题回答中的问题-答案对更准确。
**4.3 Visual7W
Visual7W(Zhu 等人,2016)是 Visual Genome 数据集的一个子集,通过从 Visual Genome 中采样 47,300 张图像。除了像 Visual Genome 一样的六个 W 问题类别外,Visual7W 还添加了另一个 W 问题类别 which。两个数据集之间的根本区别在于 Visual7W 是为多项选择任务设计的,而 Visual Genome 是为开放式任务提出的。有 327,939 个问题-答案对和来自 36,579 个类别的 561,459 个对象基础。每个问题有四个类别可供选择。
**4.4 CLEVR
CLEVR(组合语言和基本视觉推理)数据集(Johnson 等人,2017b)是由斯坦福大学的研究人员创建的。数据集中的图像是渲染的 3D 场景,描绘了简单对象和场景,如各种颜色、大小和形状的球体和块。问题和答案旨在测试 VQA 模型推理视觉概念(如对象属性、关系和逻辑操作)的能力。该数据集旨在对当前的机器学习模型具有挑战性,并专注于测试组合推理、计数和算术。整个数据集包含 100,000 张图像和 853,554 个独特问题。它按 70%:15%:15% 的比例分为训练、评估和测试。
**4.5 GQA
GQA(Hudson 和 Manning,2019a)是另一个由斯坦福大学的研究人员创建的 VQA 数据集。这是一个用于视觉推理和组合回答的真实世界数据集。GQA 包含 113K 真实世界图像和 22M 问题。每张图像都带有一个密集的场景图,表示其包含的对象、属性和关系。GQA 是第一个提供“程序”的数据集,这些程序是问题的逻辑表示,提供了一种将问题分解为更简单子问题的方式,使其更适合评估模型的组合推理能力。此外,每个答案都附有文本和视觉理由,指向图像中的相关区域。总体而言,GQA 是一个广泛使用的基准数据集,用于评估 VQA 模型的性能,因为其问题和图像的多样性和复杂性以及其庞大的规模。
5 VQA 中的问题相关性
在收集视觉问题的回答时,常见的信念是问题可以使用提供的图像来回答(Antol 等人,2015b;Andreas 等人,2016;Gao 等人,2015;Goyal 等人,2017b;Johnson 等人,2017b;Krishna 等人,2017;Malinowski 和 Fritz,2014;Ren 等人,2015a;Wang 等人,2015,2017)。然而,在实践中,并非每个人都提出与视觉内容直接相关的问题(Davis,2020),尤其是早期学习者。在 VQA v1.0(Antol 等人,2015b)中,Ray 等人(2016)进行了一项研究,他们从 1,500 张独特图像的池中随机选择了 10,793 个问题-图像对。他们的研究结果显示,79% 的问题与相应的图像无关。因此,VQA 系统应避免回答与图像无关的问题,因为这样做可能会导致相当大的混淆和缺乏信任。问题相关性的探索已在文献中得到广泛研究,导致开发了许多旨在避免回答无关问题的方法和算法。显著的贡献包括 Ray 等人(2016)、Stengel-Eskin 等人(2022)、Bhattacharya 等人(2019)、Rajpurkar 等人(2018)、Van Landeghem 等人(2023)、Gurari 等人(2018b)、Toor 等人(2017)、Chandrasekaran 等人(2018)、Mashrur 等人(2023)、Mahendru 等人(2017)等作品。SimpsonsVQA 数据集与现有数据集相关,因为它包括“相关”问题和“无关”问题。
6 评估指标
模型的评估非常多样化,取决于这些模型解决的问题类型。通常使用几种指标来评估 VQA 模型的性能:
**6.1 准确性
准确性是用于评估 VQA 模型的基本指标,有两个主要变体:6.1.1 简单准确性 简单准确性是评估多项选择 VQA 任务的最常见指标。它通过计算正确答案与总问题的比率来计算: 准确性=正确回答的问题数量总问题数准确性=总问题数正确回答的问题数量(1) 虽然简单准确性可以用于开放式多项任务,但它可能导致错误的评估。例如,如果问题是“图像中显示了哪些动物?”,标签是“狗”,预测是“狗”,则可能被认为是正确的,但系统可能将其视为错误。6.1.2 前三准确性 为了解决简单准确性在开放式 VQA 任务中的局限性,Antol 等人(2014)引入了前三准确性。该指标考虑了 VQA 数据集中每个问题通常有来自十个人的十个答案。如果至少有三个人提供与预测相同的答案,则答案被视为 100% 准确。前三准确性计算如下: 准确性=min(n3,1)准确性=min(3n,1)(2) 其中 n 是提供与预测相同答案的人数。然而,前三准确性有一个显著的实践限制:它需要一个每个问题有多个人类回答的数据集,这可能是资源密集型和耗时的。
**6.2 WUP 集得分
Wu-Palmer 相似性(WUP)是 WordNet 词汇数据库中两个单词或概念之间语义相似性的度量(Miller,1995),WordNet 是一个大型英语词汇数据库,将单词分组为同义词集(synsets)并描述它们之间的语义关系。WUP 计算两个概念之间的相似性,作为 WordNet 层次结构中最小公共子节点的深度除以两个概念的深度之和。WUP 得分在 [0, 1] 范围内,值越大表示两个单词的相似性越高。例如,(dog, puppy)的 WUP 得分为 0.9677。同时,(tall, short)的 WUPS 得分为 0.3102。在此指标下,与标签语义更相似的答案将受到较少的惩罚。基于 WUP,WUP 集得分(WUPS)(Malinowski 和 Fritz,2014)定义如下:
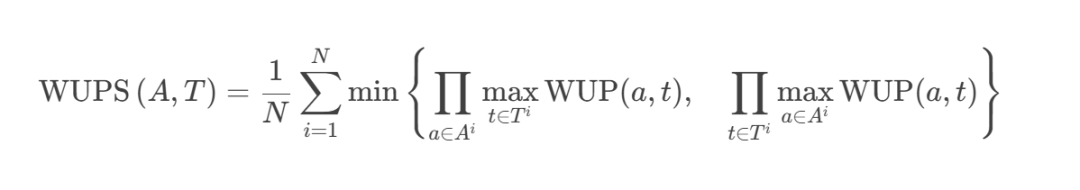
其中 A,TA,T 是答案和真实值,AiAi 和 TiTi 分别是第 i 个答案和第 i 个真实值。 然而,WUPS 得分难以用于评估 VQA 模型,因为存在一些局限性。首先,尽管某些答案和正确答案对完全不同,但它们的相似性指数相对较高。例如,(dog, cat)的 WUP 得分为 0.8667。其次,它仅用于评估需要用一个单词回答的问题。
**6.3 类人评估
随着一些生成性 LVLM 模型越来越多地生成更自然、自由形式的答案,传统的评估指标(如准确性和多项选择题)往往无法捕捉这些回答的真实质量。例如,当被问到“根据他们的表情,图像中的人可能感觉如何?”时,传统系统可能期望一个特定的单词,如“快乐”或“悲伤”。然而,一个高级模型可能会生成一个更细微的答案,如“这个人看起来很满足,可能在享受这一刻”。在这种情况下,简单的指标检查可能会错误地将回答标记为错误,如果它不完全匹配预期的单词,尽管它是一个更类人和上下文相关的答案。为了解决这个问题,最近的方法使用 LLMs(如 GPT-4)来模拟类人评估。这些 LLMs 基于语义相似性、相关性和整体连贯性评估回答,提供更灵活和准确的评估,与人类判断答案质量的方式一致。例如,MM-VET(Liu 等人,2023b)使用 GPT-4 对模型输出进行评分,评分范围为 0 到 1,反映回答在知识、空间意识和语言生成等多个维度上与类人推理的一致性。同样,MMBench(Liu 等人,2023b)使用分层评估框架,其中 LLMs 用于通过将回答与结构化多项选择选项进行比较来确定回答的正确性,确保稳健和类人的评估过程。 然而,这种方法有其局限性,主要是设置和维护对强大 LLMs 的 API 访问的成本。这可能是一个重大障碍,特别是对于预算有限的研究团队或小型组织,使其成为一个与传统、成本较低的评估指标相比不太可访问的选项。
7 应用
尽管 VQA 是一个有前途且活跃的研究领域,但由于其相对较新且复杂,实际应用仍然相对较少。然而,VQA 技术的一些实际应用示例包括以下内容:
**7.1 VQA 在医学中的应用
VQA 有潜力成为医学成像中的强大工具,帮助医疗专业人员进行临床决策和疾病诊断。与许多针对特定任务的医学 AI 应用不同,VQA 旨在解释广泛的问题并提供准确的答案,使其具有高度通用性。然而,在医学领域应用 VQA 面临重大挑战,特别是在需要大型、专业化数据集方面。创建这些数据集成本高昂,需要专家仔细注释医学图像(如 X 射线和 CT 扫描),制定相关问题并提供准确答案。这些图像通常需要分割技术以增强分析,问题中使用的语言必须专门针对医学背景。因此,现有的医学 VQA 数据集往往比通用领域数据集更小、更专业化。著名的数据集包括 VQA-MED(Hasan 等人,2018b)、Abacha 等人(2019,2020)、VQA-RAD(Lau 等人,2018b)和 PathVQA(He 等人,2020a)。 随着 2018 年 VQA-Med 挑战的推出,医学 VQA 的研究加速,许多方法受到通用领域模型的启发。常用的注意力模型包括堆叠注意力网络(SAN)(Zhan 等人,2020;Do 等人,2021)和双线性注意力网络(BAN)(Nguyen 等人,2019;Liu 等人,2021b),以及通过高级操作(如多模态因子分解双线性池化(MFB))(Peng 等人,2018)提高模型性能的多模态池化技术。
**7.2 VQA 用于视障人士
视障人士面临重大挑战,如获取视觉信息有限,这影响了他们导航和与环境互动的能力。传统的深度学习工具(如目标检测和图像字幕生成)提供了一些帮助,但通常缺乏全面理解所需的深度。VQA 通过允许用户询问有关图像的问题并以自然语言接收详细答案,提供了更全面的解决方案。 VizWiz 数据集由 Gurari 等人(2018b)引入,是推进视障人士 VQA 的关键。它包括 31,000 张由视障用户拍摄的图像及其相应的问题,由于现实世界图像的低质量和复杂性,使其更具挑战性。VizWiz-Priv 是该数据集的一个变体,包括已匿名化的隐私敏感信息。此外,答案定位数据集(如 VizWiz-VQA-Grounding(Chen 等人,2022a))通过将答案链接到特定视觉区域来增强答案的相关性。与医学 VQA 不同,医学 VQA 通常需要专门的模型,通用领域模型(如 LXMERT(Tan 和 Bansal,2019)和 OSCAR(Li 等人,2020a))通常被调整以帮助视障人士。
**7.3 VQA 用于遥感数据(RSVQA)
RSVQA 由 Lobry 等人(2019)首次探索,用于从卫星图像中提取信息,回答有关环境特征(如房屋数量或区域形状)的问题。他们使用了一个简单的 VQA 模型,结合 LSTM 和 ResNet 与逐点乘法,达到了 80% 的准确性。然而,他们的数据集存在局限性,如问题多样性低和不平衡。为了改进这一点,他们后来引入了一个更大的数据集,包含非常高分辨率的图像(Lobry 等人,2020)。随后,来自通用 VQA 的其他模型被调整为 RSVQA,包括多池化方法(Chappuis 等人,2021)、LVLMs(Felix 等人,2021;Bazi 等人,2022)、基于注意力的模型(Zheng 等人,2021)和关系网络(Zhang 等人,2023a)。
**7.4 VQA 用于文化遗产
Sheng 等人(2016)引入了第一个用于文化遗产的 VQA 数据集,专注于古埃及阿玛尔纳时期。这个小型数据集包括 16 件艺术品和相关问题,使用 Faster R-CNN 的自下而上模型。Garcia 等人(2020)扩展了这项工作,引入了 AQUA 数据集,其中包括绘画和详细评论。他们开发了 VIKING 模型,该模型整合了视觉和外部知识,尽管生成的问题通常简单且缺乏多样性。为了克服需要专家生成描述的需求,Bongini Brown 等人(2020)使用 GPT-3 自动生成艺术品的详细描述。
**7.5 VQA 用于广告
广告在商业中至关重要,因为它们吸引客户注意力并推动销售。通过使用引人入胜的图像或视频,广告帮助公司成长并实现其目标。虽然一些广告传达简单的信息,但其他广告呈现复杂的思想,需要高级推理,使 VQA 成为分析此类内容的重要工具。Hussain 等人(2017)引入了第一个用于广告的 VQA 数据集,包括约 64,000 张图像广告和 3,500 个视频广告。他们的基本 VQA 模型使用 LSTM 与 VGGNet 用于图像,LSTM 与 ResNet 用于视频,由于简单性,准确性较低。在此基础上,Zhou 等人(2020)开发了一个更高级的 VQA 模型,具有跨模态编码器和前馈网络。他们结合了从广告中 OCR 生成的文本和来自维基百科的外部知识,显著提高了早期模型的性能。
**7.6 VQA 用于教育
近年来,出现了几个专门的教育 VQA 数据集,每个数据集都针对特定学科,旨在挑战推理和理解能力的各个方面。在数学领域,MathVista(Lu 等人,2023)等数据集迎合了高中和高级数学推理。MathVista 涵盖了广泛的主题,包括代数、几何和微积分,要求模型解决方程、解释图形并进行几何推理。科学领域的数据集(如 ScienceQA(Lu 等人,2022)和教科书问答(TQA)数据集(Kembhavi 等人,2017b))涵盖了广泛的科学学科。ScienceQA 涵盖了物理、化学和生物学的主题,基于教科书图表和实验设置提出问题,以评估模型对科学原理的理解。TQA 源自中学科学教科书,结合了科学图表中的视觉数据和文本信息,提出了复杂的多模态挑战。AI2D 数据集(Kembhavi 等人,2016)进一步推动了这一领域的发展,专注于科学中的图表理解,模型必须理解并推理典型的教科书图表。 Kembhavi 等人(2017b)引入了 VQA 用于教育的初步实现。他们创建了一个名为教科书问答的数据集,来自中学科学课程。他们的基线模型使用 CNN+VGG 架构,没有注意力机制,面临几个局限性。数据集很小,仅包含约 3000 张图像,图像对于现有的机器理解能力来说过于复杂。因此,它没有被研究人员和潜在资助者广泛采用。他们的模型也难以从图像和问题中捕获基本信息,仅达到 30% 的准确性。随后,注意力模型(Gomez-Perez 和 Ortega,2020)、关系网络(Haurilet 等人,2018;Li 等人,2018a;Wang 等人,2023;Ma 等人,2022)、双线性池化(Li 等人,2018b)被应用于提高性能。一些作品(Chen 等人,2021;Zhang 等人,2023b;Cao 和 Xiao,2022)探索了几何 VQA 模型,使用包括 GeoQA、GeoQA+ 在内的小型数据集,其中包括中学的几何问题。然而,它们遇到了类似的局限性。 He 等人(2017)进行了一项值得注意的研究,该研究使用 VQA 开发了一个旨在帮助学前学生的机器人。该机器人旨在回应学前儿童关于周围环境(如猫或狗)的询问,利用语音识别、图像捕捉和回答系统。然而,该研究缺乏评估系统来评估机器人在增强儿童认知发展方面的有效性。此外,系统的准确性未呈现,考虑到早期学习对儿童后续发展的重大影响,这一点至关重要。
8 讨论、挑战和未来研究方向
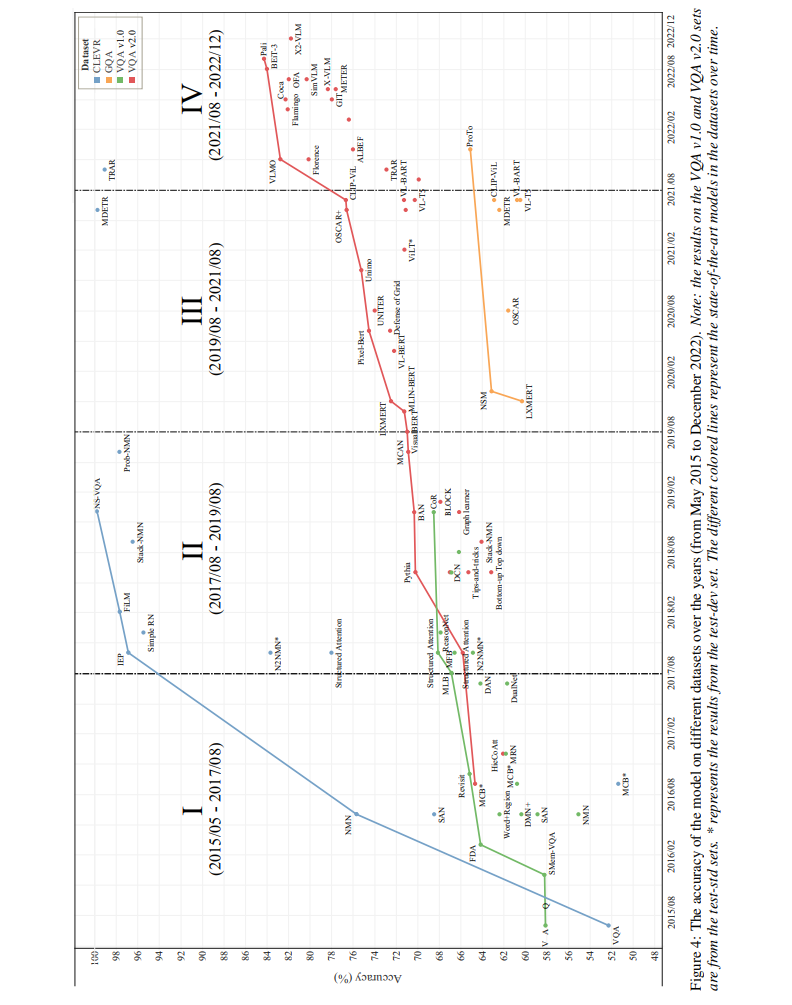
根据表 3,视觉编码器、语言编码器以及融合技术多年来有许多发展。在同一节中讨论这些问题将非常困难。这些模块多年来的发展也不同。因此,我们将通过以下 4 个时间段分别讨论这些模块:
**8.1 视觉编码器
构建模型的架构取决于输入图像的处理方式。使用基于对象的视觉编码器的模型比基于网格的编码器产生更好的结果,后者无法提供细粒度的推理(Anderson 等人,2018;Teney 等人,2018)。基于网格的视觉编码器在第一和第二时期被广泛使用。基于对象的编码器由 Anderson 等人(2018)首次引入,逐渐在第三时期成为主流。原因是基于对象的编码器可以捕获比基于网格的编码器更多的语义信息,因此取得了更好的结果(Anderson 等人,2018;Teney 等人,2018)。然而,Li 等人(2021)指出,基于对象的模型在计算和注释方面都很昂贵,因为它们需要在预训练期间进行边界框注释,并在推理期间使用较大尺寸的图像。Dou 等人(2022)也同意,基于对象的视觉编码器有一些局限性,因为它们通常在训练期间保持冻结,并且提取局部视觉特征需要时间。Kim 等人(2021)研究了基于 ViT 的补丁视觉编码器减少了模型的大小,导致运行时间比基于网格和基于对象的编码器分别减少了四倍和六十倍。除此之外,基于 ViT 的 LVLM 模型比其他模型达到了更好的性能(Kim 等人,2021;Dou 等人,2022;Li 等人,2021)。因此,这种方法已成为最流行的编码器。未来,基于 ViT 的补丁编码器将成为 LVLM 的热门趋势,因为它为整合视觉和文本信息提供了强大而灵活的框架,并在各种 LVLM 任务中展示了令人印象深刻的性能。
**8.2 语言编码器
在第一和第二时期,主要使用 RNN 模型(如 LSTM 和 GRU)。在 BERT(Devlin 等人,2018)诞生后,Transformer 语言编码器主要用于在第三和第四时期提取问题特征。除了这两种流行的方法外,一些研究人员在早期阶段使用了一些简单的方法,如 BOW(Shih 等人,2016;Gao 等人,2019)和 CNN(Yang 等人,2016;Lu 等人,2016)。
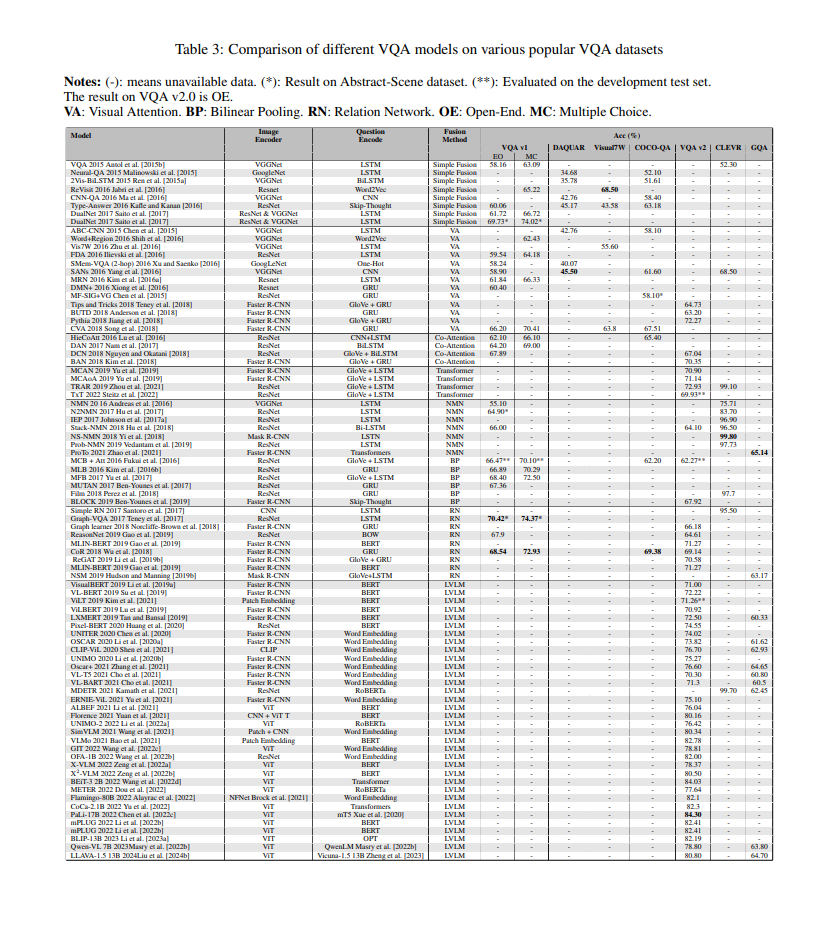
在使用的语言编码器中,预训练 Transformer 语言模型展示了令人印象深刻的性能(表 3)。例如,Dou 等人(2022)研究了各种语言模型,包括 BERT、RoBERTa、ELECTRA(Clark 等人,2020)、ALBERT(Lan 等人,2019)和 DeBERTa(He 等人,2020b)用于文本编码,并显示 RoBERTa 是其中最好的模型。Chen 等人(2022)和 Alayrac 等人(2022)分别使用具有 130 亿和 700 亿参数的巨大预训练语言模型进行文本编码,并在 VQA 中达到了最先进的水平。最近,使用 LLM(Liu 等人,2024a;Alayrac 等人,2022;Liu 等人,2024b;Li 等人,2023a)作为骨干,然后使用视觉编码器进行训练以节省时间和数据等资源的趋势展示了显著的结果,并有望在未来继续。
**8.3 融合方法
大多数研究人员专注于改进这一部分,而不是其他部分。因此,融合方法的发展非常多样化。图 4 展示了从 2015 年至今的 VQA 模型以及其他模型的最新技术水平。 第一时期: 最初,RNN-CNN 后跟简单的融合操作用于构建 VQA 模型。这种端到端方法简单,达到了较低的性能(Antol 等人,2015b)。从 2015 年到 2017 年,提出了基于视觉的模型,使用注意力机制权衡图像不同区域和输入问题的贡献。因此,基于视觉注意力的模型优于之前的工作(Yang 等人,2016;Ren 等人,2015a)。同时,引入了一些双线性池化融合技术,并取得了更好的结果,因为它们可以捕获图像和问题特征之间的交互(Fukui 等人,2016;Kim 等人,2016b;Yu 等人,2017;Ben-Younes 等人,2017)。此外,Fukui 等人(2016)将这些池化技术集成到基于注意力的模型中,以提高 VQA 性能。除了这些方法外,关系网络(Santoro 等人,2017;Teney 等人,2017)和 NMN 模型(Andreas 等人,2016;Hu 等人,2017;Johnson 等人,2017a)也取得了一定的成就。这一时期在 VQA v1.0 数据集上的准确性范围为 58% 到 64%。 第二时期: 提出了共同注意力机制以同时捕获视觉和问题注意力(Nguyen 和 Okatani,2018;Yu 等人,2018;Nam 等人,2017)。然而,Yu 等人(2019)建议这些共同注意力模型仅限于捕获问题的单词到单词关系和图像的区域到区域关系。因此,他们使用 Transformer 构建了 MCAN(Yu 等人,2019)。在 VQA v1.0 和 v2.0 上的性能从 66% 到 71%。 第三时期: 提出了一些基于 Transformer 的 VQA 模型(Yu 等人,2019;Zhou 等人,2021;Zhao 等人,2021)。然而,LVLM 出现并成为解决 VQA 以及其他 VL 任务(如视觉字幕生成)的主要主题。最初,LVLM 模型使用基于对象的视觉编码器进行视觉编码(Li 等人,2019a;Su 等人,2019;Chen 等人,2020;Li 等人,2020a;Zhang 等人,2021;Cho 等人,2021;Lu 等人,2019;Tan 和 Bansal,2019;Yu 等人,2021)。后来,研究人员将其替换为基于网格和基于 ViT 的补丁编码器,以构建端到端的 LVLM 模型(Kim 等人,2021;Huang 等人,2020;Shen 等人,2021;Kamath 等人,2021;Li 等人,2021)。在这一时期,这些模型的规模通常是中等规模的,例如 ALIGN 有 8.2 亿参数,Florence 有 8.93 亿参数。在 VQA v2.0 上的准确性范围为 71% 到 78%。 第四时期: LVLMs 继续主导解决视觉语言任务(包括 VQA)的领域。最近的进展看到了来自领先公司(如 Google、Microsoft 和 DeepMind)的高度扩展的 LVLMs 的引入。这些模型的规模从几十亿到几百亿参数不等,如 PaLI(Wang 等人,2022d)有 169 亿参数,Flamingo 有 802 亿参数。这些模型在 VQA v2.0 基准测试中的准确性范围为 78% 到 84%。 未来,这些 LVLMs 有望显著增强零样本和少样本学习能力,减少对广泛微调的需求。通过利用这些大规模模型中编码的丰富知识,未来的迭代可能会在跨任务和领域泛化方面表现出色,只需最少的额外训练即可执行新任务并回答复杂查询,从而简化这些模型在各种实际应用中的部署。事实上,原始 VQA 模型的构建已被 LVLM 取代,因为 LVLM 可以同时解决许多任务,并在 VL 任务中取得高结果。LVLM 将继续是一个热门领域,吸引未来研究人员的关注。
**8.4 应用
VQA 的未来发展预计将显著影响教育和医疗保健,特别是在复杂的数学问题解决和医学成像方面。在教育中,VQA 系统预计将通过解决更复杂的数学推理问题而取得进展,超越简单的计算,解释复杂的方程、几何形状和图形。这些系统可以通过回答诸如“这个函数的导数是什么?”或“解释解决这个方程的步骤”等查询,提供交互式、实时的学习支持。 在医疗保健中,VQA 在医学成像中的作用可能会扩大,提供更准确和详细的分析,如 MRI、CT 扫描和 X 射线。未来的系统不仅可以回答诸如“是否存在肿瘤?”等问题,还可以提供详细的见解,提供潜在诊断或治疗计划的建议。这些进展可以减少诊断错误并增强个性化患者护理。为了实现这一目标,研究需要专注于提高 VQA 系统的推理能力,并开发更大、领域特定的数据集,以有效地在这些关键领域训练模型。
9 结论
VQA 代表了人工智能领域的重大进展,使机器能够解释和回应关于视觉内容的问题。多年来,VQA 已经从简单的基于图像的问题回答系统发展到能够进行复杂推理的复杂模型,这些模型基于视觉和语言理解。 本综述的关键要点是 VQA 在各个领域的多功能性。从医学诊断和教育工具到视障人士的可访问性,VQA 的应用广泛且具有影响力。然而,挑战仍然存在,如需要领域特定的数据集、增强的推理能力和实时系统性能。 展望未来,LVLMs 的整合有潜力将 VQA 推向新的领域,提高准确性并扩展到更多样化和复杂的任务。随着 VQA 的不断发展,解决数据集可用性、计算效率和实际部署方面的差距将是实现其全部潜力的关键。



