强化学习如何可解释?浙大最新《可解释强化学习》综述,37页pdf1阐述XRL概念、算法、挑战
浙江大学最新《可解释强化学习》综述,37页pdf1阐述XRL概念、算法、挑战

强化学习(RL)是一种流行的机器学习范式,智能体与环境交互以实现长期目标。在深度学习复兴的推动下,深度RL (DRL)在广泛的复杂控制任务中取得了巨大成功。尽管取得了令人鼓舞的结果,但基于深度神经网络的骨干网被广泛认为是一个黑盒,它阻碍了从业者在高安全性和可靠性至关重要的现实场景中信任和使用经过训练的智能体。为了缓解这个问题,通过构建内在解释性或事后解释性,大量的文献致力于阐明智能智能体的内部工作方式。在本综述中,我们对可解释RL (XRL)的现有工作进行了全面的回顾,并引入了一种新的分类法,将先前的工作明确地分为模型解释方法、奖励解释方法、状态解释方法和任务解释方法。本文还回顾并强调了强化学习方法,这些方法反过来利用人类知识来提高智能体的学习效率和最终性能,而这种方法在XRL领域往往被忽略。讨论了XRL中一些开放的挑战和机遇。本综述旨在对XRL进行高层次的总结和更好的理解,并推动未来对更有效的XRL解决方案的研究。相应的开放源代码可以在https://github.com/Plankson/awesome-explainable-reinforcement-learning上收集和分类。
https://www.zhuanzhi.ai/paper/5de088e7aaabfa7fd1c5ff37c8f76101
概述
强化学习[193]受到人类试错范式的启发[143]。它基于这样一个事实:与环境互动是人类在没有他人指导的情况下学习的常见方式[98]。从互动中,人类获得了关于因果关系、行动结果以及如何在环境中实现目标的信息。这类信息被隐式地用来构建我们的心智模型[155,218,225],而更多这类信息将使这个心智模型更加精确[22,171]。RL类似于目标导向的学习,通过与环境的交互,敏锐地意识到环境如何响应我们的行为,并有目的地影响未来的事件。更准确地说,RL学会从环境状态映射到行动,从而最大化数值奖励信号[189]。近年来,深度学习的快速发展[15,194]促进了深度学习与强化学习的融合。因此,深度强化学习(DRL)[44, 60, 134, 135, 177]作为一种新的RL范式出现。凭借深度神经网络强大的表示能力[7,51,230],DRL在许多领域都取得了相当的性能[17,24,29,37,11,121,184],特别是在AlphaZero[184]和OpenAI Five[17]等游戏任务中,基于DRL的方法成功击败了人类职业选手。然而,对于现实场景中更复杂的任务,如自动驾驶[25,39,79,213,214]和电力系统调度[109,115,226,227,239],不仅要考虑高性能,还要考虑面向用户的可解释性,以考虑安全性和可靠性。这种可解释性的要求是在真实世界而不是模拟环境中使用DRL的主要瓶颈。
由于深度神经网络(DNN)的主干复杂,传统的DRL方法的可解释性较低[67,100,185,195]。追踪和解释一个神经系统中的每个参数,并将其扩展到整个网络,这是非常棘手的。因此,我们不知道DNN考虑了哪些隐式特征,以及DNN如何处理这些特征。这个缺点导致DRL模型正在成为一个黑盒[84,232],专家无法理解智能体如何知道环境或智能体为什么选择特定的行动。这种不透明性限制了DRL的应用,因为大多数人不会轻易信任智能体,特别是当智能体在没有解释决策过程的原因的情况下与他们的期望完全相反时。例如,在自动导航任务中[32,156],人们可能会对导航代理在没有告诉他们原因的情况下进行的异常引导感到困惑,这可能只是为了避免交通堵塞。此外,可解释性的缺乏也造成了在训练过程中插入人类知识和指导的障碍[62,166]。尽管人类知识是以特定形式预先给定的[56,57,181,233,236],但智能体无法提取有效信息并从中受益。
为了解决可解释性低的问题,在计算机视觉(CV)中的可解释性人脸识别[43,85,165,219]和自然语言处理(NLP)中的可解释性文本分类[8,119,186]等机器学习领域开展了许多可解释性研究。可解释机器学习的目标是生成不同形式的解释,使模型对专家甚至外行人都是可解释和透明的。它查看黑箱代理模型内部,自动提取或生成解释,解释为什么代理在每个时间步中选择这个动作或给出这个结论。解释的形式可以多种多样,如自然语言[38,53,66]、显著图[54,83]或视频[178]。通过可解释的模型,智能体可以发现潜在的缺陷,并向专家解释这些缺陷以进行进一步的改进。
对于可解释强化学习(XRL)领域,人们在构建可解释强化学习(XRL)模型方面做了许多初步的研究,并在解释生成方面取得了一定的成果。为了对它们有一个完整的认识并总结当前的XRL技术,对XRL进行了几次综述[33,49,74,158,208,217]。Heuillet等人[74]回顾了关注解释和用户类型的方法。他们只是根据生成解释的方式将方法分为两类。这是一个初步的分类,需要进一步改进。Puiutta和Veith[158]遵循了基于解释时间和范围的传统可解释AI分类法。他们只是描述了一些有代表性的方法,并不是为了呈现对XRL的全面忽视。Wells和Bednarz[217]也列举了各种XRL方法。但他们只关注可用于XRL领域的可视化技术。voros[208]将范围限定在最先进的XRL方法中,并为XRL提供了一个架构符号范式,而解释内容可分为代理偏好和目标的影响。Dazeley等人[33]提出了一个称为因果XRL框架的概念架构,该框架解释了XRL如何通过关注因果行为来生成对行为的解释。该理论体系结构清晰而严谨,不仅考虑了感知、行动和事件,还考虑了目标、期望和处置。然而,现有的XRL框架只关注事件结果的感知和行动原因,这意味着现有的XRL技术只能用一种更简单的因果XRL框架形式来表示。Glanois等人[49]明确界定了可解释性和可解释性之间的界限。他们将这些方法分为三种:可解释输入、过渡模型和偏好模型。它启发我们关注RL的过程和结构。这些研究都提出了基于XRL的新分类法,但大多数都没有基于RL范式。此外,从以上的综述中我们可以发现,XRL领域仍然缺乏标准的标准,特别是在XRL的定义和评价方法方面,虽然许多人提出了自己的XRL标准[116,131,138,208],但没有一个被整个DRL界所接受。目前的XRL框架大多没有考虑人类参与的影响,只有少数论文试图将基于人类知识的范式扩展到XRL领域,其研究结果有力地证明,这是一种既能获得高解释性又能获得高性能的有效方法[237]。
为了使整个XRL体系结构得到进一步发展,系统地回顾了当前的XRL框架和综述。明确了XRL模型可解释性的概念,总结了模型可解释性的评价指标。基于这些提出的XRL框架,我们提出了一种新的更适合于RL的XRL分类法。由于使整个RL范式可解释目前是困难的,所有的工作都转向对RL范式的组成部分可解释。我们根据可解释的目标部分对当前的XRL作品进行分类:模型、奖励、状态和任务。这四种部分解释方法的目的是生成对主体行为的解释。对于RL来说,这种分类法比一般的内在/事后/本地分类法要高级得多。考虑到基于人类知识的XRL工作的数量和它的重要性,我们将其分离出来,并试图总结这些工作,并将它们组织到我们的分类法中。据我们所知,很少有研究者对这一领域进行了既包括人类知识又包括XRL的总结。我们的工作总结如下:
基于可解释RL和可解释机器学习的现有文献,我们对XRL中的模型可解释性进行了详细的总结。当前的XRL评估指标也包含在这个总结中。
基于强化学习框架的不同部分(模型、奖励、状态和任务)的可解释性,为当前的XRL作品引入了一种新的分类。可以在图2中查看分类法。
注意到目前基于人类知识的XRL是一个不受欢迎的方向,只有少数作品和显著的结果,我们将其作为论文的主要部分之一,对这些将XRL框架与人类知识相结合以获得更高性能和更好解释的方法进行了系统的综述。
本次综述的其余部分组织如下。在第二节中,我们回顾了强化学习的必要基础知识。接下来,我们将讨论XRL模型可解释性的定义,并在第3节中给出解释和XRL方法的一些可能的评估方面。在第4节中,我们描述了我们的分类,并详细提供了每个类型和子类型的工作,我们分类法的抽象图可以在图2中看到。然后我们根据第5节的分类讨论与人类知识相结合的XRL工作。在此之后,我们在第6节中总结了XRL当前的挑战和未来的发展方向。最后,在第7部分对本文的工作进行了总结。本文的结构和我们的分类法工作如图1所示。
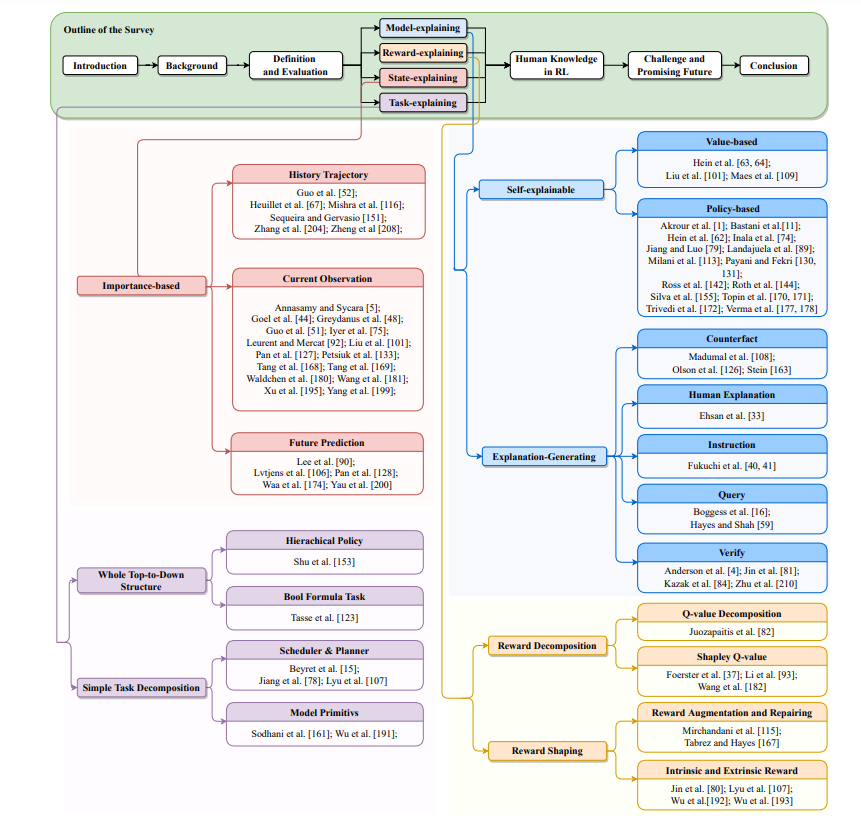
图1所示概述。本文概述了可解释强化学习(XRL)。在我们的工作中,我们根据强化学习(RL)过程中不同部分的可解释性将XRL分为四个部分:模型、奖励、状态和任务。这张图用不同的颜色表示。图中还展示了更具体的分类和作品,我们将在后面的部分中讨论它们。
专知便捷查看
便捷下载,请关注专知公众号(点击上方蓝色专知关注)
后台回复“XRL37” 就可以获取《强化学习如何可解释?浙大最新《可解释强化学习》综述,37页pdf1阐述XRL概念、算法、挑战》专知下载链接





