当机器学习遇上计算机视觉
计算机视觉,是开发计算机算法用以自动理解图像内容的领域,在1960年代左右从人工智能(Artificial Inteligence)和认知神经科学(cognitive neuroscience)衍化出来。为了“解决”视觉问题,麻省理工大学(MIT)在1966年开设了一个暑期项目,该项目在当时广受关注但是人们发现对于该领域的理解认识还非常有限,离这个项目的成熟还有很长一段路要走。在50年后的今天,对图像进行一般地认识这一问题仍没有得到完美地解决,但是该领域仍然在蓬勃发展。随着交互式分割(interactive segmentation,在Microsoft Office里可用于“移除背景”)、图像检索(image search)、人脸识别(face detection)、对焦、Kinect对人的动作捕捉等项目的商业化运作取得成功,计算机视觉领域有了巨大的发展,视觉算法也开始得到广泛的关注。引起这一计算机视觉发展浪潮的主要源头是近15到20年机器学习领域(ML,machine learning)的快速崛起。
该系列的第一篇将会探索计算机视觉面临的一些挑战且会涉及到用于像素分类的强大的决策森林的人工智能技术。
图像分类
请试着回答下列的图像分类问题:“这张图片中有车吗”。对计算机而言,一张图像仅仅是一个包含红绿蓝像素的网格,每个像素用一个0到255的数字表示。这些数字不仅取决于物体是否出现,还取决于一些干扰因素如相机的视角、光照条件、背景及目标的姿态。此外,我们还需应对由于类型不同而引起的车在外观上的变化的情况。例如,一辆车可能是旅行车、小卡车、小轿车,而每一种都会对应非常不同的像素网格
幸运的是,相对于手动写代码解决这些包含无数种可能性的问题,有监督的机器学习提供了另一种解决方法。通过收集图像生成一个训练集以及对训练集中的每张图像适当地进行标记,我们可以使用合适的机器学习算法来找出哪些像素模式是跟我们的识别工作相关的,哪些是干扰因素。在学习干扰因素的不变性时,我们希望通过学习使得图像泛化为新的我们所关心的物体的测试例子。目前我们在视觉学习算法、数据集收集和标记方面都已经取得了一定的发展。
用于像素分类的决策森林
图像在很多层次上都包含细节。如之前已经提到的,我们能针对整个图像问一个类似是否包含某个特定类别的物体(如汽车)的问题。但是我们也可以试着解决一个看似更难的问题,“语义图像分割”问题:描绘出场景中的所有物体。下面是一个街景的分割例子:
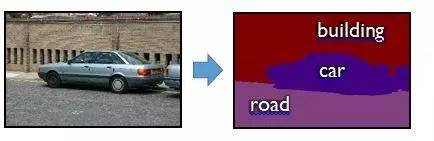
可以想象到语义图像分割技术将会帮助我们选择性编辑照片,甚至合成新图片。我们接下来将会见识到一些更多的应用。
解决语义分割问题有很多种方法,但是像素分类是一个关键的基础:在每一个像素点训练一个分类器来预测物体类别的分布(如汽车、道路、树、墙等)。该项工作给机器学习抛出了一些计算难题。尤其是,当图像包括大量的像素时(如诺基亚1020智能手机能捕捉4千万像素的图像)。这意味着我们潜在地拥有了比用整张图像分类多百万倍的训练和测试用例。
这个问题的规模引领我们研究一个特定的有效的分类模型,决策森林(也称作随机森林、随机决策森林)。一个决策森林是一个包含多个训练决策树的集合:

每棵树有一个根节点,多个内部“分裂”节点和多个终端“叶子”节点。测试分类从根节点开始,计算数据的一些二分“分裂函数”,这些“分裂函数”是一些诸如“这个像素点的R值比它邻居点的R值更高吗”一样简单的问题。取决于二分决策的结果,树将向左或者向右分枝,继续查询下一个分裂函数,如此重复循环。当最终到达一个叶子节点时,将输出一个储存的预测,该预测通常是一个关于类别标签的直方图。(可以参见Chris Burges最近发表的关于搜索排序决策树的升式变异的优秀论文)
决策树的优点体现在它们在测试时间上的高效率:虽然从根节点到叶节点有指数级别多的可能路径,但任何单个测试像素点将只能沿着一条路径走下来。此外,分裂函数的计算是基于之前的结果的:例如,分类器会根据之前问题的结果问一个更合适的问题。这跟”二十个问题“这个游戏中使用的策略相同:当你只被允许问少量的问题时,你能通过根据之前的答案不断调整问的问题来很快得到一个正确的结果。
通过使用这一技术,我们已经在处理诸如照片的语义分割、街景的分割、3D医学扫描的人类解剖分割、照相机的重新定位、kinect深度图像里对人体部位的分割等各样问题上取得了可观的成就。对Kinect而言,决策树的测试时间高效性是很关键的:我们的计算预算是相当紧张的,但是有条件的计算配合着Xbox GPU上对像素点并行处理的技术意味着我们是可以能在预算内解决问题的。
译者: 望西 原作者:ML Blog Team
http://article.yeeyan.org/view/406438/443422/





