CVPR2017 VQA 任务冠军:基于双向注意力机制视觉问答pyTorch实现
【导读】在CVPR2017上举办的VQA(Visual Question Answering)比赛中,基于双向注意力机制视觉问答(Bottom-Up and Top-Down Attention for Visual Question Answering)取得了冠军。其主要贡献在于提出了Bottom-Up and Top-Down Attention的机制, 不仅用一个个的单词,来指代检测到的物体,这种方法在含空间信息的同时还可以对应多个单词,比如一个形容词和名词,提供丰富的语义表现力。最近香港科技大学的Hengyuan Hu等人基于PyTorch 实现了该夺冠模型的代码并开源。
Bottom-Up and Top-Down Attention for Visual Question Answering
这是一个高效的PyTorch实现,是2017 VQA Challenge获奖作品。
该实现借鉴了下面的VQA系统:
1. "Bottom-Up and Top-Down Attention for Image Captioning and Visual Question Answering" (https://arxiv.org/abs/1707.07998)
2. "Tips and Tricks for Visual Question Answering: Learnings from the 2017 Challenge" (https://arxiv.org/abs/1708.02711)
▌比赛结果
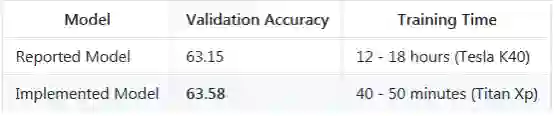
准确度使用VQA evaluation metric.(http://www.visualqa.org/evaluation.html )指标进行计算。
▌信息
这是CMU 11-777高级多模态机器学习课程的一部分,是Hengyuan Hu, Alex Xiao, and Henry Huang的联合工作结果。
作为我们项目的一部分,我们将自下而上的注意力作为一个强大的VQA baseline。我们计划将目标检测与VQA集成在一起,Peter Anderson和Damien Teney等人已经在这项任务中取得很好的成果。我们本文的简洁高效的实现可以作为未来探索VQA的一个有用的baseline。
▌细节实现
我们的实现遵循论文的整体结构,但是有以下的简化:
1. 我们不使用Visual Genome以外的数据;
2. 我们固定目标的数量(一个图像K=36);
3. 我们不进行预训练,仅适用简单的单流分类器(single stream classifier);
4. 我们用ReLU激活函数代替门控tanh(gated tanh)。
前两点大大缩短了训练时间。我们的实现在单个Titan Xp上每个时段(epoch)约需要200秒,而在论文中描述的每个时段需要1个小时。
第三点只是因为我们觉得原文中的两个流分类器和预训练过程太复杂,并且是没有必要的。
对于非线性激活单元,我们尝试了gated tanh但是不能工作。我们也尝试了gated线性单元(GLU),它比ReLU更好,但最终我们选择ReLU是因为它更简单,并且由于使用GLU的收益太小而不能证明GLU确实使参数数目加倍。
通过上面几点简化,我们会期望性能下降。作为参考,本文报告的验证集的最佳结果是63.15。不包含visual genome额外数据的结果是62.48,每个图像固定使用36个目标的结果是62.82,使用两个分类器但不预训练的结果是62.28,使用ReLU的结果是61.63。这些数字引用文章的表1:“VQA的要诀和技巧:从2017 Challenge中学习”。综合以上所有的简化步骤,我们的实现在验证集上达到了59-60。
为了缩小差距,我们添加了一些简单但有效的修改。包括:
1. 添加dropout缓解过拟合;
2. 成倍增加神经元数量;
3. 权重标准化(平衡网络BN似乎不行)
4. 切换到Adamax优化器
5. 梯度限幅
这些小修改使结果数据达到大约〜62.80。我们将原始论文中基于连接的注意模块变为基于投影的模块。这个新的注意力模块受到了“Modeling Relationships in Referential Expressions with Compositional Modular Networks)(https://arxiv.org/pdf/1611.09978.pdf)文章的启发,但是有一些修改。在这个新的注意力模块的帮助下,我们将性能提高到了63.58,超过了报告的最佳结果,我们没有额外的数据和并且需要的计算成本更少。
▌用法准备
确保你的机器上有NVIDIA GPU和Python 2,且拥有至少70 GB的磁盘空间。
1. 用CUDA和Python 2.7安装PyTorch
2. 安装h5py
▌数据设置
所有数据都应该下载到根目录的data/目录中。
下载数据的最简单方法是从库根目录运行脚本工具/ download.sh。如果脚本不起作用,应该比较容易检查脚本中的问题,并根据您的需要修改其中的选项。然后从库根目录运行tools / process.sh,将数据处理成正确的格式。
▌训练
只需运行python main.py即可开始训练。将在每个epoch步骤中打印训练和验证的分数,最好的模型被保存在“saved_models”目录下。
VQA Challenge介绍(参考其中文和英文网址)
▌VQA挑战:
VQA 全称是 visual question answering。具体任务是给定一幅图像和一个关于这幅图的文本问题,然后就这个问题给出文本回答。VQA是一个多模态问题,这也是VQA具有挑战性的地方。你需要同时处理文字和图片,并进行推理,来得到最后的答案。类似的多模态的问题有 image captioning,visual dialog 等等。VQA Challenge开始于2016年,VQA Challenge 2017是其第二次VQA Challenge。更多关于VQA Challenge的内容,可参看 http://www.visualqa.org/challenge.html
▌VQA常用的数据集
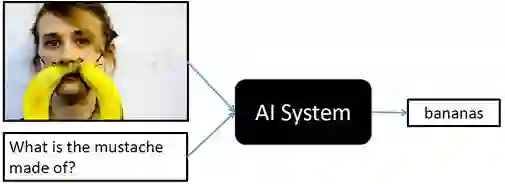
比较常用的数据集就是 VQA 这个数据集,来自 Gatech 和微软。目前VQA数据集已经更新到v2.0版本,其中包括204721个COCO图像,大于1.1 million个问题,大于11 million个答案。V2.0版本中每个问题有两个相似的图像,并且有不同的答案,如下图所示:

参考链接:
http://www.visualqa.org/challenge.html
https://github.com/hengyuan-hu/bottom-up-attention-vqa
-END-
专 · 知
人工智能领域主题知识资料查看获取:【专知荟萃】人工智能领域26个主题知识资料全集(入门/进阶/论文/综述/视频/专家等)
同时欢迎各位用户进行专知投稿,详情请点击:
【诚邀】专知诚挚邀请各位专业者加入AI创作者计划!了解使用专知!
请PC登录www.zhuanzhi.ai或者点击阅读原文,注册登录专知,获取更多AI知识资料!

请扫一扫如下二维码关注我们的公众号,获取人工智能的专业知识!

请加专知小助手微信(Rancho_Fang),加入专知主题人工智能群交流!

点击“阅读原文”,使用专知!





