ICCV | 深度三维残差神经网络:视频理解新突破
编者按:随着互联网的不断发展,可处理视频的深度神经网络远比普通神经网络更难训练,如何减轻训练负担成为了一项不可忽视的工作。来自微软亚洲研究院多媒体搜索与挖掘组的研究成果“Learning Spatio-Temporal Representation with Pseudo-3D Residual Networks”,在正在举办的International Conference on Computer Vision (ICCV) 2017会议上发布,它专注于如何利用大量视频数据来训练视频专用的深度三维卷积神经网络,提出一种基于伪三维卷积(Pseudo-3D Convolution)的深度神经网络的设计思路,并实现了迄今为止最深的199层三维卷积神经网络。通过该网络学习到的视频表达,在多个不同的视频理解任务上取得了稳定的性能提升。
1993年9月,一款名为NCSA Mosaic的浏览器正式支持在网页内嵌入图片,这标志着互联网从纯文本时代迈入了“无图无真相”的多媒体时代。如今,随着互联网带宽的提升和高速移动设备的普及,信息的获取途径和传播途径也在与日增加,视频逐渐成为互联网多媒体消费的重要组成部分。
从传统的视频分享网站到电视电影节目的网络化,再到现在新兴的视频直播网站和小视频分享网站,互联网视频已经进入了爆炸式发展的新阶段。据统计,仅仅以视频分享网站YouTube为例,平均每分钟就有约300小时的视频上传到YouTube上,每天的视频观看次数更是高达50亿次。数量如此巨大的视频内容与观看次数对视频处理、分类、推荐等常见视频相关技术提出了更高的要求,也提供了更广阔的应用场景。
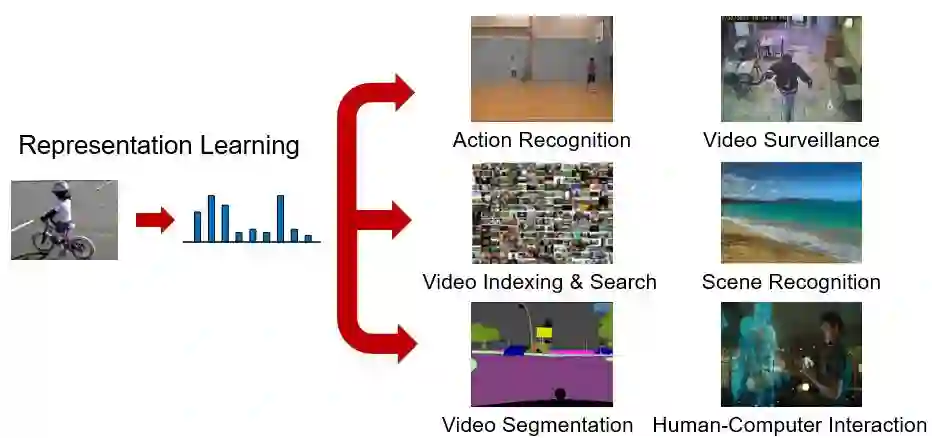
在视频处理相关技术中,视频特征描述学习(Representation Learning)是一个最基本的问题。学习视频的特征表达是几乎所有视频处理和分析的基础,其中包括视频标注、动作识别、视频监控、视频检索、视频场景识别、视频分割、视频自然语言描述和基于视频的人机交互等等。
然而目前视频识别的相关研究多数使用的是基于图像的卷积神经网络(如微软研究院在2015提出的残差神经网络ResNet)来学习视频特征,这种方法仅仅是对单帧图像的CNN特征进行融合,因此往往忽略了相邻的连续视频帧间的联系以及视频中的动作信息。目前,视频专用的深度神经网络还很缺乏。
在正在举行的International Conference on Computer Vision (ICCV)2017会议上,微软亚洲研究院发布了多媒体搜索与挖掘组最新的研究成果——Learning Spatio-Temporal Representation with Pseudo-3D Residual Networks[1]。这项工作主要集中在如何利用大量视频数据来训练视频专用的深度三维卷积神经网络,它提出了一种基于伪三维卷积(Pseudo-3D Convolution)的深度神经网络的设计思路,并实现了迄今为止最深的199层三维卷积神经网络。通过该网络学习到的视频表达,在多个不同的视频理解任务上取得了稳定的性能提升。

基于三维卷积神经网络的视频特征提取
为了使用深度神经网络来提取视频中时间和空间维度上的信息,一种直接的思路就是将用于图像特征学习的二维卷积拓展为三维卷积(3D Convolution),同时在时间和空间维度上进行卷积操作。如此一来,由三维卷积操作构成的三维卷积神经网络可以在获取每一帧视觉特征的同时,也能表达相邻帧随时间推移的关联与变化,如下图所示。
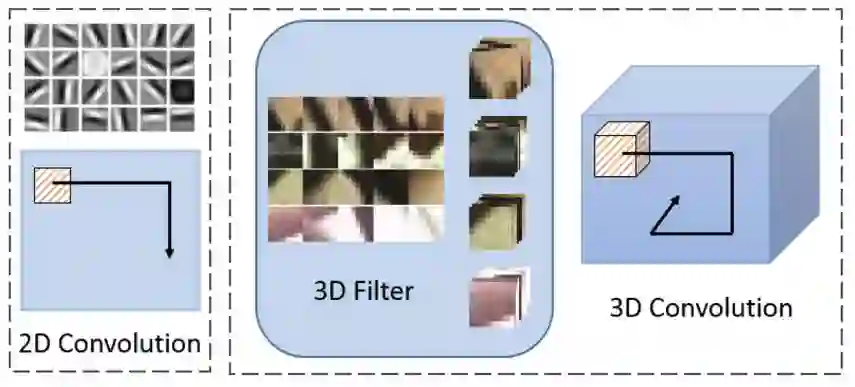
然而这样的设计在实践中却存在一定的困难。首先,时间维度的引入使得整个神经网络的参数数量、运行时间和训练所需的GPU内存都将大幅增长;其次,随机初始化的三维卷积核需要大量精细标注的视频数据来进行训练。受困于以上两点,近些年关于三维卷积神经网络的发展十分缓慢,其中最著名的C3D[2] 网络只有11层,模型大小却达到321MB,甚至大于152层ResNet[3] 的235MB模型。
深度伪三维卷积神经网络设计
为了解决以上的局限性,我们提出了一系列基于伪三维卷积和残差学习(Residual Learning)的神经网络模块,用以同时在时间和空间上进行卷积操作。其中,伪三维卷积是这个网络结构的核心操作,基本思想是利用一个1*3*3的二维空间卷积和3*1*1的一维时域卷积来模拟常用的3*3*3三维卷积。通过简化,伪三维卷积神经网络相比于同样深度的二维卷积神经网络仅仅增添了一定数量的一维卷积,在参数数量、运行速度等方面并不会产生过度的增长。与此同时,由于其中的二维卷积核可以使用图像数据进行预训练,对于已标注视频数据的需求也会大大减少。结合残差学习的思想,该论文提出三种不同的伪三维卷积残差单元(P3D-A,P3D-B,P3D-C)分别使用串行、并行和带捷径(shortcut)的串行三种方式来确定空间卷积和时域卷积之间的关系。
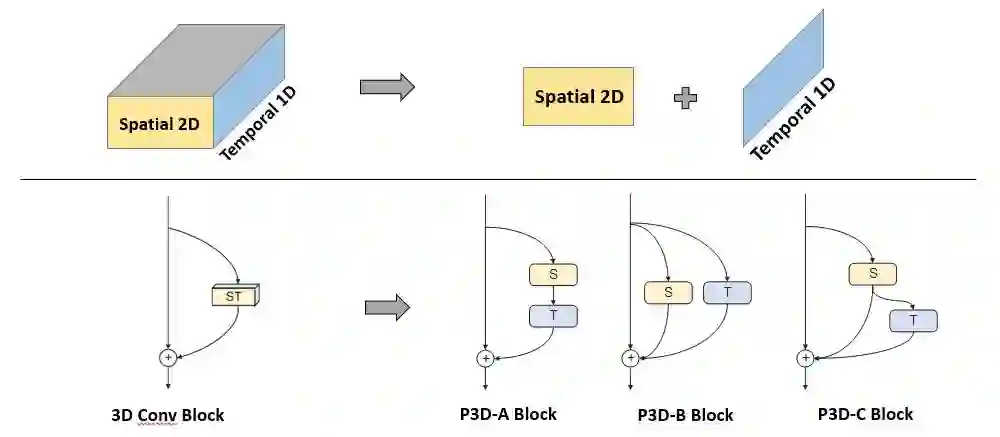
通过使用以上三种伪三维残差单元替代152层ResNet中的二维残差单元,该工作得到了目前最深的199层三维卷积网络结构。最终经过ImageNet数据集中的图片数据和Sports-1M(包含了487个类别的百万级视频片段)[4] 视频数据的训练,该网络在视频动作识别(Action Recognition)、视频相似度分析(Video Similarity)和视频场景识别(Scene Recognition)三个不同的视频理解任务上均获得了稳定的性能提升,并且在CVPR 2017的Activity Net Challenge的Dense-Captioning任务中获得第一名。
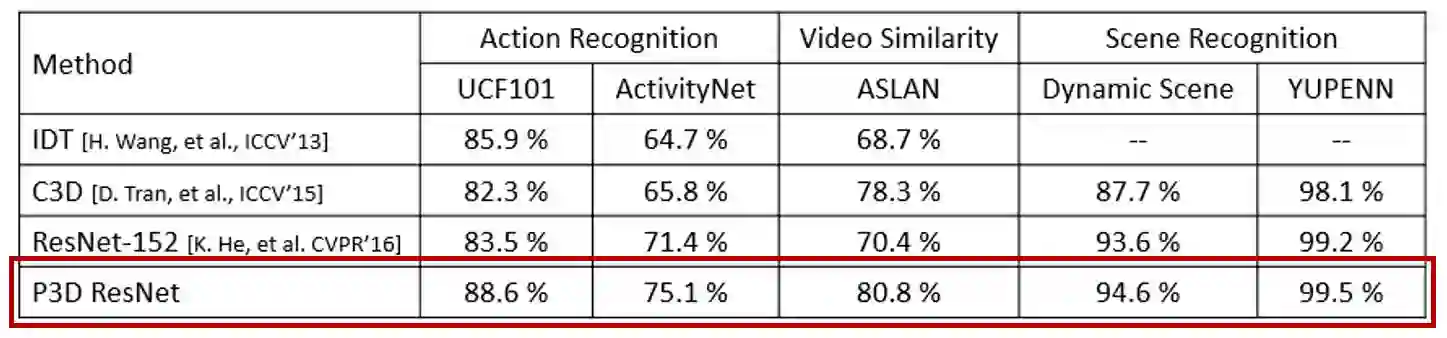
除了利用伪三维卷积网络提取特征外,该网络还可以作为其它方法的基本网络结构,从而提升其它基于神经网络方法的视频识别性能。以双流(Two-stream)方法为例,在UCF101的视频动作识别任务上,如果使用伪三维卷积网络作为基本网络结构,实现的Two-stream框架无论是单个帧分支(Frame)与光流分支(Flow),或者是最终两个分支合并的结果,都超过了其它网络结构。
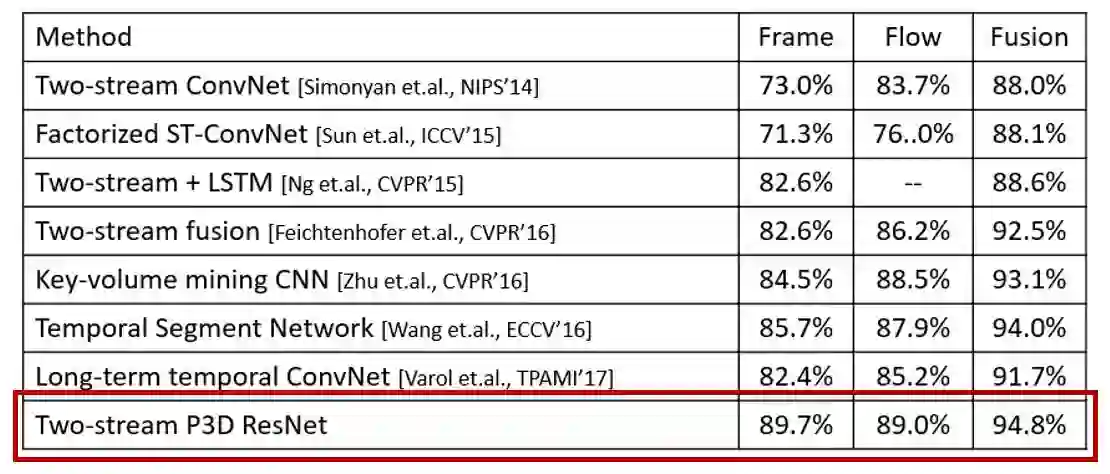
以上的实验结果验证了伪三维卷积残差网络可以有效学习来自大量图像和视频训练数据中的类别信息。在与二维卷积残差网络和传统三维卷积网络的对比中,该结构成功地提升了在不同视频识别任务上的性能。关于伪三维残差网络相关的代码和模型详见https://github.com/ZhaofanQiu/pseudo-3d-residual-networks。
神经专用神经网络的发展方向
该工作基于伪三维卷积和残差结构给出了训练超深度三维卷积网络的可能性,然而本文中提到的神经网络目前主要针对视频分类问题。面对纷繁复杂的视频内容与视频应用需求,单一的神经网络很难满足。针对不同的应用,视频专用神经网络有以下三个具有潜力的发展方向:
第一,视频检索(Video Search)专用神经网络。视频检索、视频推荐是大型视频分享网站所要面对的首要问题,给予用户良好的检索体验,并适当地推荐用户需要的视频内容,帮助用户快速地找到自己感兴趣的视频。
第二,视频分割(Semantic Video Segmentation)专用神经网络。视频分割的目标在于像素级别地分割出视频中的人、车等常见物体。而随着AR/VR技术的发展,像素级别的目标识别可以辅助许多不同的AR/VR相关应用,这也促进了视频分割的发展。
第三,视频生成(Video Generation)专用神经网络。随着用户越来越容易地在不同设备上进行视频拍摄,非专业用户对视频的自动/半自动编辑、美化也逐渐有了更多的需求。因此,视频生成神经网络便可以帮助用户编辑创作自己的视频作品。
随着卷积神经网络的发展,人工智能在很多图像相关任务上的性能都产生了飞跃,也有大量相关技术从学术圈慢慢地走进了我们的生活。但是由于视频包含信息太过复杂,大数据的获取、存储、处理均存在一定困难,导致视频相关技术在很多方面仍然进步缓慢,相信随着视频专用卷积神经网络的发展,这部分的不足也会逐渐被弥补。
无论是文本、图像还是视频,人工智能的发展在满足互联网用户需求的同时也始终推动着用户习惯的变迁。有了合理的算法对视频进行分析、推荐,可以帮助互联网用户获得更好的浏览体验;有了用户更好的反馈及更大的点击量,可以让视频产业规模进一步扩大;更大规模的视频数据会进一步对视频相关算法提出更高的要求。在这样的循环之下,视频产业本身必将伴随着视频相关算法快速地发展,迎接更美好的未来。
参考文献
[1] Z. Qiu, T. Yao, T. Mei.Learning Spatio-Temporal Representation with Pseudo-3D Residual Networks. InICCV, 2017.
[2] D. Tran, L. Bourdev, R. Fergus, L. Torresani, and M.Paluri. Learning spatiotemporal features with 3d convolutional networks. InICCV, 2015.
[3] K. He, X. Zhang, S. Ren, and J. Sun. Deep residual learning for image recognition. In CVPR, 2016.
[4] A. Karpathy, G. Toderici, S. Shetty, T. Leung, R.Sukthankar, and L. Fei-Fei. Large-scale video classification with convolutional neural networks. In CVPR, 2014.

邱钊凡,微软亚洲研究院和中国科学技术大学联合培养博士生,导师为梅涛研究员和田新梅副教授。主要研究方向包括视频特征学习、视频动作识别和多媒体内容分析。他曾于2015年在中国科学技术大学获得学士学位,并于2017年获得微软学者奖学金。

姚霆博士,微软亚洲研究院多媒体搜索与挖掘组研究员,主要研究兴趣为视频理解、大规模多媒体搜索和深度学习。他带领研究团队在COCO图像描述自动生成、2017年VISDA视觉领域自适应语义分割任务、2016&2017年ActivityNet视频行为识别等多个国际级比赛中取得了世界领先的成绩。他于2014年在香港城市大学获得计算机科学博士学位并于2015年荣获SIGMM Outstanding Ph.D. Thesis Award。

梅涛博士,微软亚洲研究院资深研究员,主要研究兴趣为多媒体分析、计算机视觉和机器学习。他的研究团队目前致力于视频和图像的深度理解、分析和应用。他同时担任IEEE 和 ACM 多媒体汇刊(IEEE TMM 和 ACM TOMM)以及模式识别(Pattern Recognition)等学术期刊的编委,并且是多个国际多媒体会议的大会主席和程序委员会主席。他是国际模式识别学会会士,美国计算机协会杰出科学家,中国科学技术大学和中山大学兼职教授。
你也许还想看:
● ACM TOMM 2017最佳论文:让AI接手繁杂专业的图文排版设计工作


感谢你关注“微软研究院AI头条”,我们期待你的留言和投稿,共建交流平台。来稿请寄:msraai@microsoft.com。





