近期必读的7篇 ACM MM 2019【图神经网络(GNN)+多媒体(MM)】相关论文
【导读】多媒体国际顶级会议 ACM Multimedia 2019已于2019年10月21日至25日在法国尼斯举行。专知小编发现图神经网络在多媒体领域应用也非常多,特意整理了七篇ACM MM 2019最新GNN相关论文,并附上论文链接供参考——个性化推荐、短视频推荐、多视频摘要、基于文本的行人搜索、视频关系检测、社区问答(CQA)系统等。
CIKM2019GNN、ICLR2020GNN、EMNLP2019GNN、ICCV2019GNN_Part2、ICCV2019GNN_Part1、NIPS2019GNN、IJCAI2019GNN_Part1、IJCAI2019GNN_Part2、 KDD2019GNN、ACL2019GNN、CVPR2019GNN、ICML2019GNN
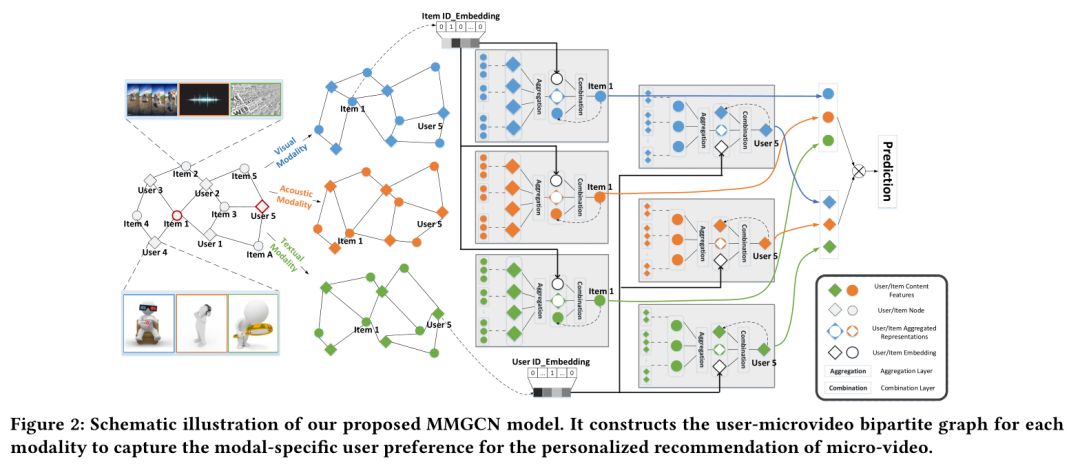
1. MMGCN: Multi-modal Graph Convolution Network for Personalized Recommendation of Micro-video
作者:Yinwei Wei,Xiang Wang,Liqiang Nie,Xiangnan He,Richang Hong,Tat-Seng Chua;
摘要:个性化推荐在许多在线内容共享平台中起着核心作用。为了提供优质的微视频推荐服务,重要的是考虑用户与项目(即短视频)之间的交互以及来自各种模态(例如视觉,听觉和文本)的项目内容。现有的多媒体推荐作品在很大程度上利用多模态内容来丰富项目表示,而为利用用户和项目之间的信息交换来增强用户表示并进一步捕获用户对不同模式的细粒度偏好所做的工作却较少。在本文中,我们建议利用用户-项目交互来指导每种模式中的表示学习,并进一步个性化微视频推荐。我们基于图神经网络的消息传递思想设计了一个多模态图卷积网络(MMGCN)框架,该框架可以生成用户和微视频的特定模态表示,以更好地捕获用户的偏好。具体来说,我们在每个模态中构造一个user-item二部图,并用其邻居的拓扑结构和特征丰富每个节点的表示。通过在三个公开可用的数据集Tiktok,Kwai和MovieLens上进行的大量实验,我们证明了我们提出的模型能够明显优于目前最新的多模态推荐方法。
网址:
https://dl.acm.org/citation.cfm?id=3351034
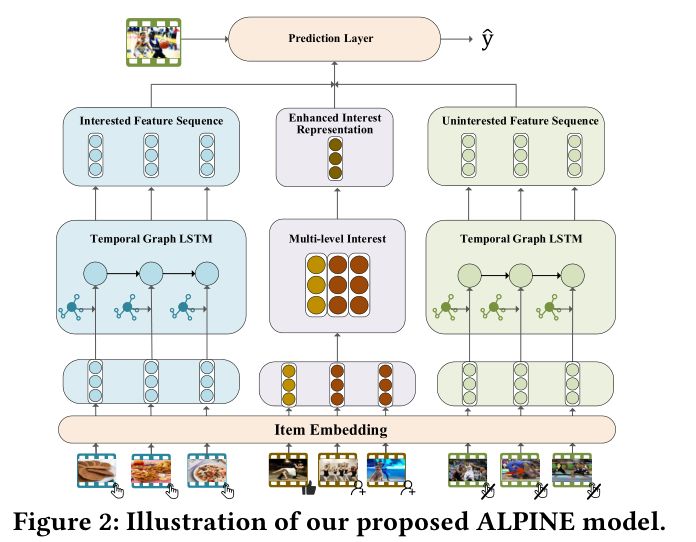
2. Routing Micro-videos via A Temporal Graph-guided Recommendation System
作者:Yongqi Li,Meng Liu,Jianhua Yin,Chaoran Cui,Xin-Shun Xu,Liqiang Nie;
摘要:在过去的几年中,短视频已成为社交媒体时代的主流趋势。同时,随着短视频数量的增加,用户经常被他们不感兴趣的视频所淹没。尽管现有的针对各种社区的推荐系统已经取得了成功,但由于短视频平台中的用户具有其独特的特征:多样化的动态兴趣,多层次的兴趣以及负样本,因此它们无法应用于短视频的一种好的方式。为了解决这些问题,我们提出了一个时间图指导的推荐系统。特别是,我们首先设计了一个新颖的基于图的顺序网络,以同时对用户的动态兴趣和多样化兴趣进行建模。同样,可以从用户的真实负样本中捕获不感兴趣的信息。除此之外,我们通过用户矩阵将用户的多层次兴趣引入推荐模型,该矩阵能够学习用户兴趣的增强表示。最后,系统可以通过考虑上述特征做出准确的推荐。在两个公共数据集上的实验结果证明了我们提出的模型的有效性。
网址:
https://dl.acm.org/citation.cfm?id=3350950
3. MvsGCN: A Novel Graph Convolutional Network for Multi-video Summarization
作者:Jiaxin Wu,Sheng-hua Zhong,Yan Liu;
摘要:试图为视频集合生成单个摘要的多视频摘要,是处理不断增长的视频数据的重要任务。在本文中,我们第一个提出用于多视频摘要的图卷积网络。这个新颖的网络衡量了每个视频在其自己的视频以及整个视频集中的重要性和相关性。提出了一种重要的节点采样方法,以强调有效的特征,这些特征更有可能被选择作为最终的视频摘要。为了解决视频摘要任务中固有的类不平衡问题,提出了两种策略集成到网络中。针对多样性的损失正则化用于鼓励生成多样化的摘要。通过大量的实验,与传统的和最新的图模型以及最新的视频摘要方法进行了比较,我们提出的模型可有效地生成具有良好多样性的多个视频的代表性摘要。它还在两个标准视频摘要数据集上达到了最先进的性能。

网址:
https://dl.acm.org/citation.cfm?doid=3343031.3350938
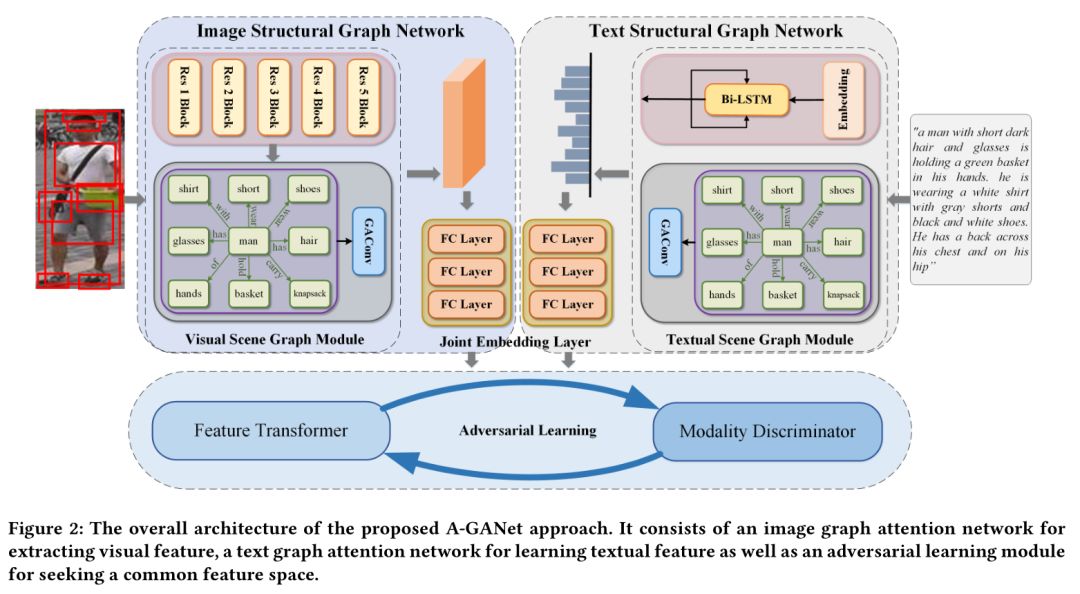
4. Deep Adversarial Graph Attention Convolution Network for Text-Based Person Search
作者:Jiawei Liu,Zheng-Jun Zha,Richang Hong,Meng Wang,Yongdong Zhang;
摘要:新出现的基于文本的行人搜索任务旨在通过对自然语言的查询以及对行人的详细描述来检索目标行人。与基于图像/视频的人搜索(即人重新识别)相比,它实际上更适用,而不需要对行人进行图像/视频查询。在这项工作中,我们提出了一种新颖的深度对抗图注意力卷积网络(A-GANet),用于基于文本的行人搜索。A-GANet利用文本和视觉场景图,包括对象属性和关系,从文本查询和行人画廊图像到学习信息丰富的文本和视觉表示。它以对抗性学习的方式学习有效的文本-视觉联合潜在特征空间,弥合模态差距并促进行人匹配。具体来说,A-GANet由图像图注意力网络,文本图注意力网络和对抗学习模块组成。图像和文本图形注意网络设计了一个新的图注意卷积层,可以在学习文本和视觉特征时有效利用图形结构,从而实现精确而有区别的表示。开发了具有特征转换器和模态鉴别器的对抗学习模块,以学习用于跨模态匹配的联合文本-视觉特征空间。在两个具有挑战性的基准(即CUHK-PEDES和Flickr30k数据集)上的大量实验结果证明了该方法的有效性。
网址:
https://dl.acm.org/citation.cfm?id=3350991
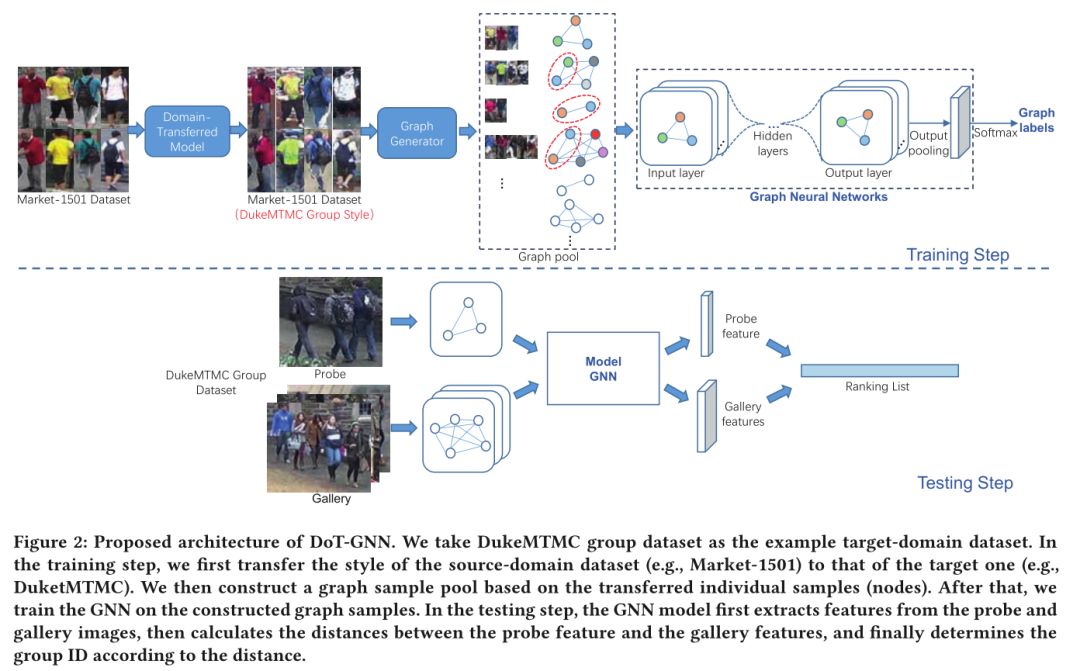
5. DoT-GNN: Domain-Transferred Graph Neural Network for Group Re-identification
作者:Ziling Huang,Zheng Wang,Wei Hu,Chia-Wen Lin,Shin’ichi Satoh;
摘要:大多数行人再识别(ReID)方法的重点是从收集的个人图像数据库中检索感兴趣的人。除了单独的ReID任务外,在不同的摄像机视图中匹配一组人在监视应用程序中也起着重要作用。这种组重新标识(G-ReID)任务非常具有挑战性,因为我们不仅要面对个人外观变化所面临的障碍,而且还要面对组布局和成员身份变化所面临的障碍。为了获得群体图像的鲁棒表示,我们设计了一种域转移图神经网络(DoT-GNN)方法。优点包括三个方面:1)风格转移。由于缺少训练样本,我们将标记的ReID数据集转移到G-ReID数据集样式,并将转移的样本提供给深度学习模型。利用深度学习模型的优势,我们实现了可区分的个体特征模型。2)图生成。我们将组视为图,其中每个节点表示单个特征,每个边沿表示几个个体之间的关系。我们提出了一种图生成策略来创建足够的图形样本。3)图神经网络。利用生成的图样本,我们训练GNN,以获取对大型图变化具有鲁棒性的图特征。DoT-GNN成功的关键在于转移的图形解决了外观变化的挑战,而GNN中的图表示克服了布局和成员资格变化的挑战。大量的实验结果证明了我们方法的有效性,分别在Road Group数据集上的1.8%的CMC-1和DukeMCMT数据集上的6.0%的CMC-1上优于最先进的方法。
网址:
https://dl.acm.org/citation.cfm?id=3351027
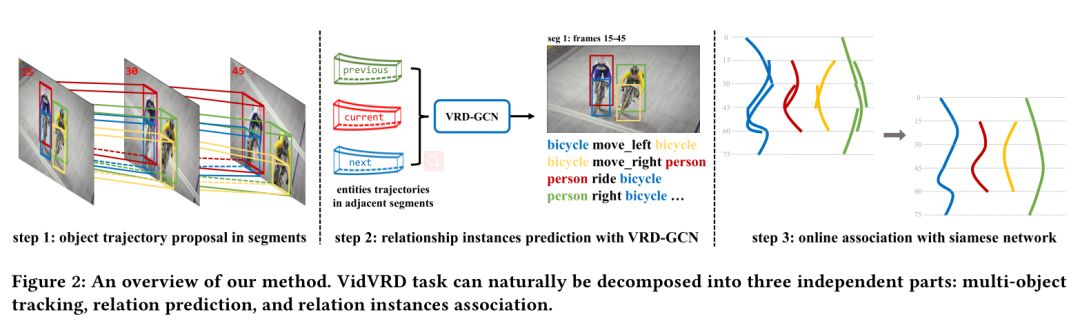
6. Video Relation Detection with Spatio-Temporal Graph
作者:Xufeng Qian,Yueting Zhuang,Yimeng Li ,Shaoning Xiao,Shiliang Pu,Jun Xiao;
摘要:我们从视觉内容中看到的不仅是对象的集合,还包括它们之间的相互作用。用三元组<subject,predicate,object>表示的视觉关系可以传达大量信息,以供视觉理解。与静态图像不同,由于附加的时间通道,视频中的动态关系通常在空间和时间维度上都相关,这使得视频中的关系检测变得更加复杂和具有挑战性。在本文中,我们将视频抽象为完全连接的时空图。我们使用图卷积网络使用新颖的VidVRD模型在这些3D图中传递消息并进行推理。我们的模型可以利用时空上下文提示来更好地预测对象及其动态关系。此外,提出了一种使用暹罗网络的在线关联方法来进行精确的关系实例关联。通过将我们的模型(VRD-GCN)与所提出的关联方法相结合,我们的视频关系检测框架在最新基准测试中获得了最佳性能。我们在基准ImageNet-VidVRD数据集上验证了我们的方法。实验结果表明,我们的框架在很大程度上领先于最新技术,一系列的消去研究证明了我们方法的有效性。
网址:
https://dl.acm.org/citation.cfm?doid=3343031.3351058
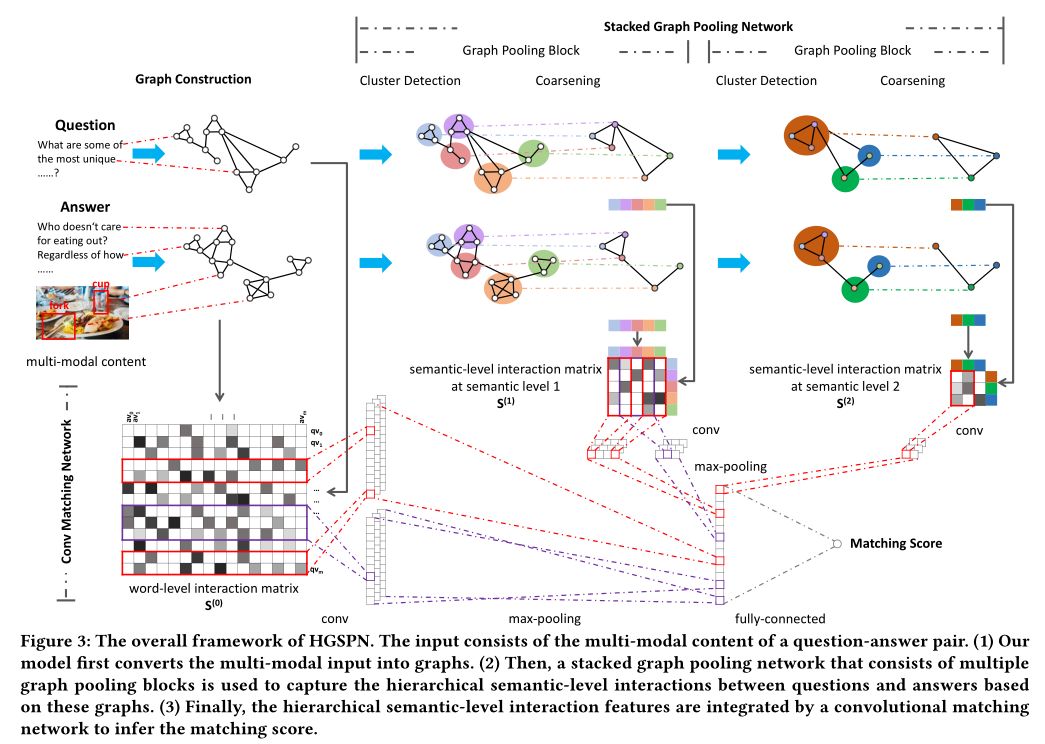
7. Hierarchical Graph Semantic Pooling Network for Multi-modal Community Question Answer Matching
作者:Jun Hu,Shengsheng Qian, Quan Fang,Changsheng Xu;
摘要:如今,社区问答(CQA)系统吸引了数百万用户分享其宝贵的知识。为特定问题匹配相关答案是CQA系统的核心功能。以前的基于交互的匹配方法在CQA系统中显示出令人鼓舞的性能。但是,它们通常受到两个限制:(1)他们通常将内容建模为单词序列,而忽略了非连续短语,长途单词依赖性和视觉信息所提供的语义。(2)单词级交互作用集中在位置上相似单词的分布上,而与问题和答案之间的语义级交互作用无关。为了解决这些限制,我们提出了一种多层图语义池化网络(HGSPN),以在用于多模态CQA匹配的统一框架中对层次结构语义级别的交互进行建模。我们将将文本内容转换为图形,而不是将文本内容转换为单词序列,从而可以对非连续短语和长距离单词相关性进行建模,以更好地获取语义的组成。此外,视觉内容也被建模到图中来提供补充的语义。提出了一种设计良好的堆叠图池网络,以基于这些图捕获问答之间的分层语义级别的交互。设计了一种新颖的卷积匹配网络,通过集成分层语义级别的交互功能来推断匹配分数。在两个真实数据集上的实验结果表明,我们的模型优于最新的CQA匹配模型。
网址:
https://dl.acm.org/citation.cfm?doid=3343031.3350966
请关注专知公众号(点击上方蓝色专知关注)
后台回复“ACMMM2019GNN” 就可以获取《7篇论文》的下载链接~
更多“图神经网络”论文请上专知网站(www.zhuanzhi.ai )进行查看!成为VIP,查看更多干货!
https://www.zhuanzhi.ai/topic/2001785662228213/paper