
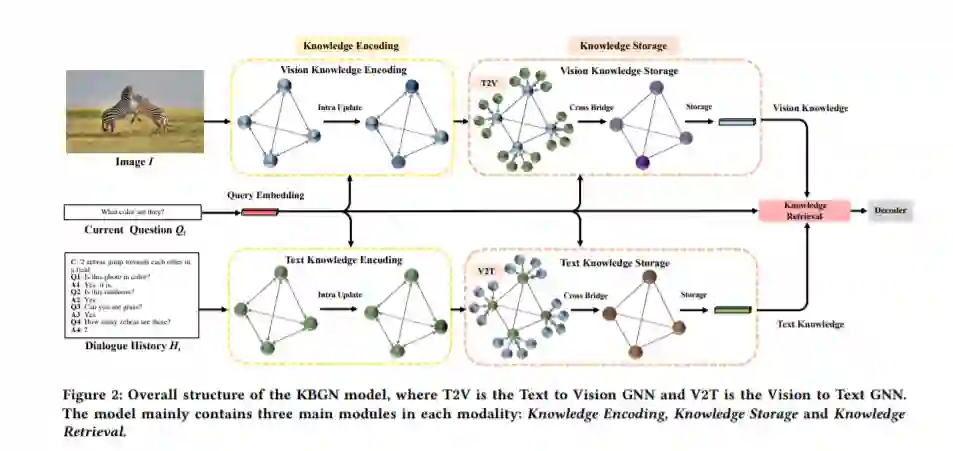
视觉对话是一项具有挑战性的任务,它需要从视觉(图像)和文本(对话历史)上下文中提取隐含信息。经典的方法更多地关注当前问题、视觉知识和文本知识的整合,忽略了跨模态信息之间的异构语义鸿沟。同时,连接操作已成为跨模式信息融合的事实标准,其信息检索能力有限。本文提出了一种新的知识桥接图网络模型,利用图在细粒度上桥接视觉知识和文本知识之间的跨模式语义关系,并通过自适应的信息选择模式检索所需的知识。此外,视觉对话的推理线索可以清晰地从模态内实体和模态间桥梁中提取出来。VisDial v1.0和VisDial- q数据集上的实验结果表明,我们的模型优于现有的模型,取得了最新的结果。
https://www.zhuanzhi.ai/paper/6a3e359d8827752a98f2e5daa7079d2a
成为VIP会员查看完整内容
相关内容

Arxiv
13+阅读 · 2020年8月11日
相关主题

相关VIP内容
相关资讯
相关论文
Arxiv
13+阅读 · 2020年8月11日