
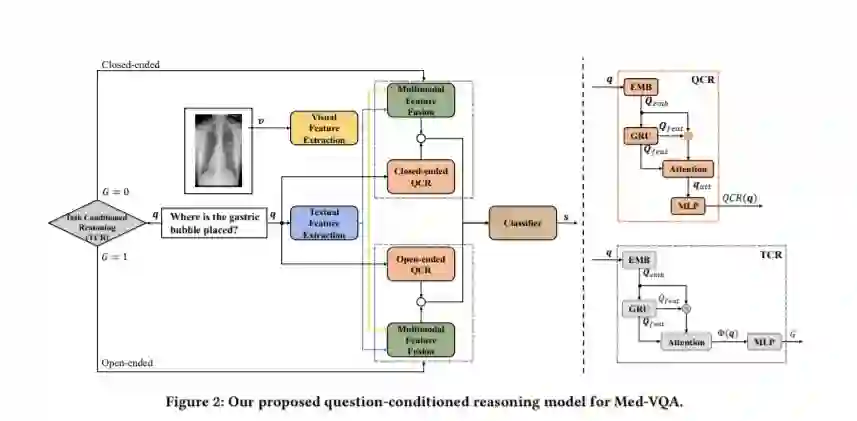
医学视觉问答(Medical visual question answer, Med-VQA)的目的是准确回答医学图像所呈现的临床问题。尽管该技术在医疗保健行业和服务领域有着巨大的潜力,但它仍处于起步阶段,远未得到实际应用。由于临床问题的多样性以及不同类型问题所需的视觉推理技能的差异,Med-VQA任务具有很高的挑战性。本文提出了一种新的Med-VQA的条件推理框架,旨在自动学习各种Med-VQA任务的有效推理技巧。特别地,我们开发了一个问题条件推理模块来指导多模态融合特征的重要性选择。针对封闭式和开放式的Med-VQA任务的不同性质,我们进一步提出了一种类型条件推理模块,分别针对两种类型的任务学习不同的推理技能。我们的条件推理框架可以很容易地应用到现有的Med-VQA系统中,从而提高性能。在实验中,我们在最近最先进的Med-VQA模型上建立我们的系统,并在VQA-RAD基准[23]上评估它。值得注意的是,我们的系统在预测封闭式和开放式问题的答案方面都取得了显著的提高,特别是对于开放式问题,其绝对准确率提高了10.8%。源代码可以从https://github.com/awenbocc/med-vqa下载。
http://www4.comp.polyu.edu.hk/~csxmwu/papers/MM-2020-Med-VQA.pdf
成为VIP会员查看完整内容
相关内容

相关VIP内容
相关资讯
相关论文