AAAI 2019 | 百度、MIT等提出StNet:局部+全局的视频时空联合建模
选自 arXiv
作者:何栋梁等
机器之心编辑
第 33 届 AAAI 大会已于当地时间 1 月 27 在美国夏威夷正式开幕,昨日机器之心报道了 AAAI 2019 的获奖信息。在大会期间,我们将持续为读者们推送有关本次大会的优质论文解读、精彩演讲等。
AAAI 是人工智能领域的国际顶级会议,早期由计算机科学和人工智能创始人 Allen Newell, Marvin Minsky 和 John McCarthy 等人首创,被中国计算机学会(CCF)推荐为 A 类会议。
据机器之心了解,国内科技巨头百度共有 15 篇论文被 AAAI 2019 收录。本文介绍了百度联合 MIT 、南京大学等机构共同完成的一篇 spotlight 论文《StNet: Local and Global Spatial-Temporal Modeling for Action Recognition》。论文中提出的StNet架构将在2019年Q1随百度PaddlePaddle深度学习平台视频识别算法库一起对外开源。

论文地址:https://arxiv.org/pdf/1811.01549.pdf
摘要:深度学习在静态图像理解上取得了巨大成功,然而高效的视频时序及空域建模的网络模型尚无定论。不同于已有的基于 CNN+RNN 或者 3D 卷积网络的方法,本文提出了兼顾局部时空联系以及全局时空联系的视频时空联合建模网络框架 StNet. 具体而言,StNet 将视频中连续 N 帧图像级联成一个 3N 通道的「超图」,然后用 2D 卷积对超图进行局部时空联系的建模。为了建立全局时空关联,StNet 中引入了对多个局部时空特征图进行时域卷积的模块。特别地,我们提出了时序 Xception 模块对视频特征序列进一步建模时序依赖。在 Kinetics 动作识别数据集的大量实验结果表明,StNet 能够取得 State-of-the-art 的识别性能,同时 StNet 在计算量与准确率的权衡方面表现优异。此外实验结果验证了 StNet 学习到的视频表征能够在 UCF101 上有很好的迁移泛化能力。
以下是对 StNet 的技术概述:
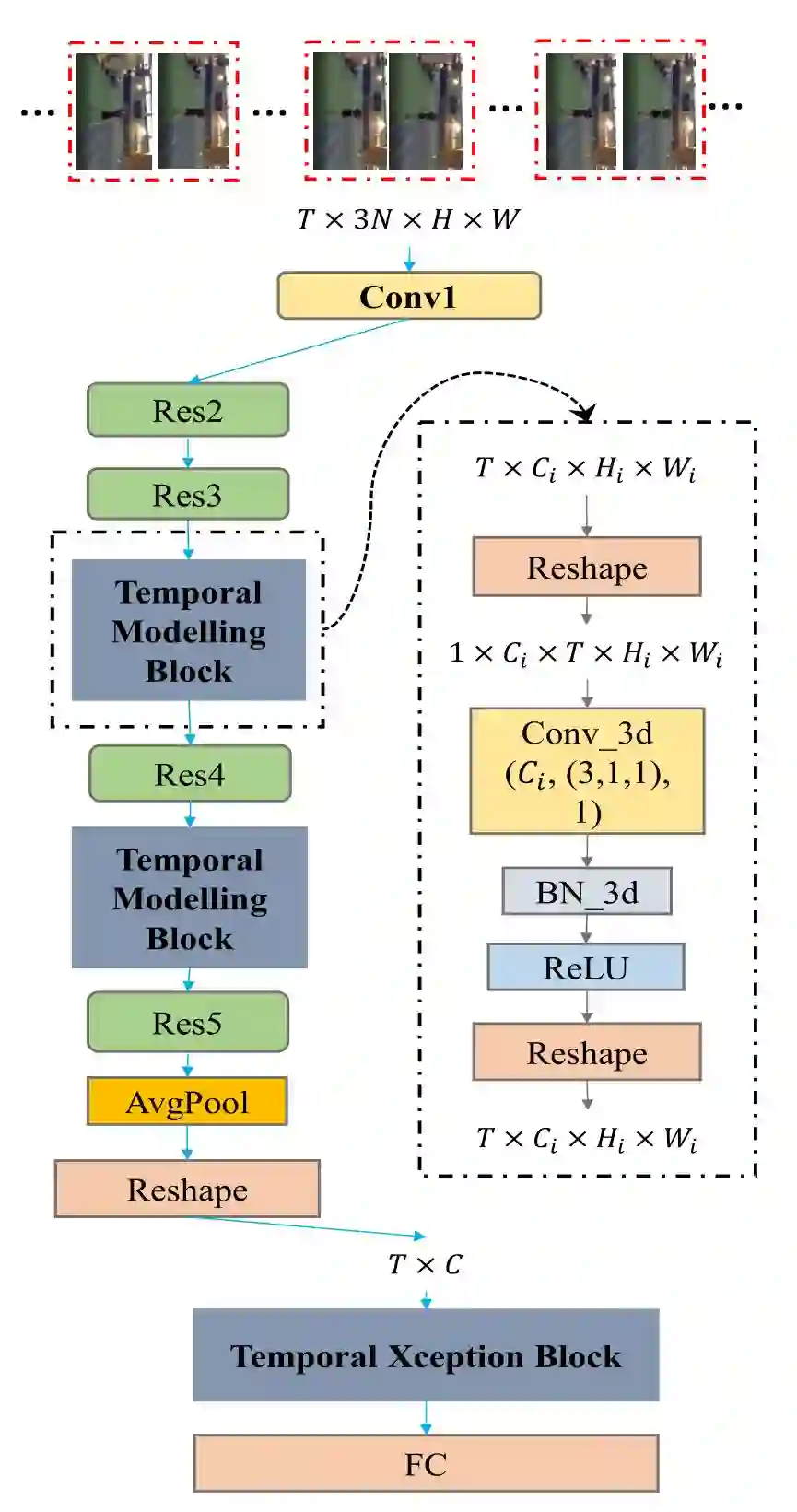
1. StNet 的输入为均匀采样的 T 个局部连续 N 帧的视频帧。局部的连续 N 帧组合成一个超图,使得超图保留原始视频各个局部的时空信息。均匀采样 T 个超图则保留了原始视频的全局时空信息。
2. 采用 2D 卷积对超图进行局部时空关系的建模,可以避免 3D 卷积网络参数量和计算量大的问题。
3. 通过堆叠 3D 卷积/2D 卷积模块,对 T 个局部时空特征图进行全局时空信息的建模。3D 卷积空间维度的 kernel size 设置成 1 以节省模型参数量与计算量。
4. 对 pooling 出来的 T 个特征向量,不同于简单的取平均操作,本文提出了时序 Xception 模块,进行进一步的时序关系捕获来获取最终的视频特征向量。时序 Xception 模块的设计主要基于时序 1 维卷积,类似 2D 卷积的 Xception 设计,这里采用了 channel-wise 和 temporal-wise 分离的策略以进一步减少计算量与模型参数量。
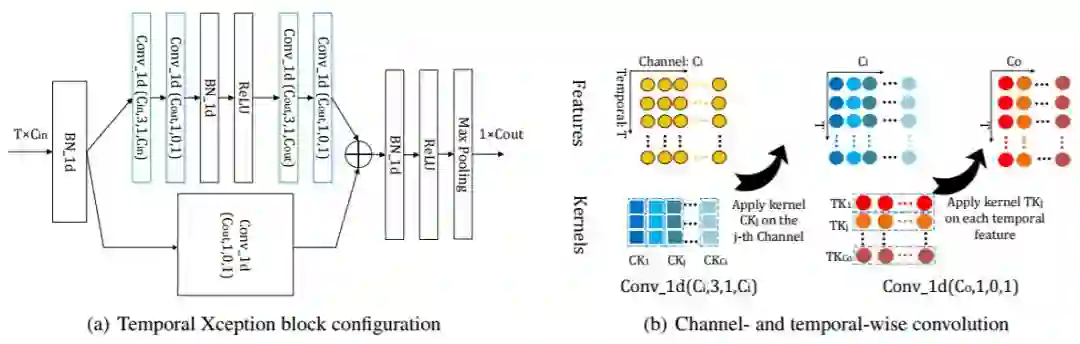
图 3:时间 Xception 块(TXB)。我们提出的时间 Xception 块的详细配置如(a)所示。括号中的参数表示 1D 卷积的(#kernel,kernel size,padding,#groupss)配置。绿色的块表示 channel-wise 的 1D 卷积,蓝色的块表示 temporal-wise 的 1D 卷积。(b)描绘了 channel-wise 和 temporal-wise 的 1D 卷积。TXB 的输入是视频的特征序列,表示为 T×C_in 张量。通道 1D 卷积的每个卷积核仅在一个通道内沿时间维度应用。Temporal-wise 的 1D 卷积核在每个时间步骤中跨所有通道进行卷积。
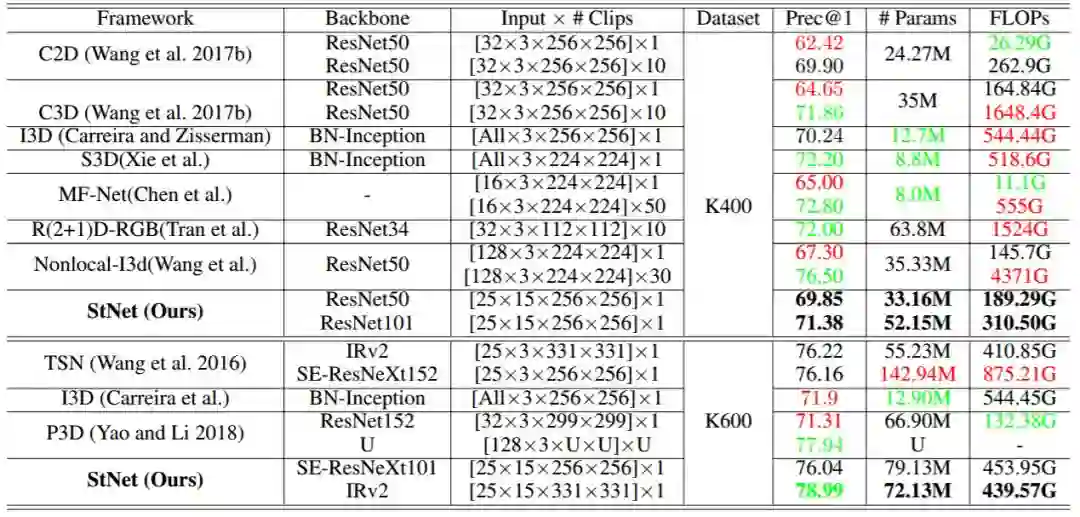
表 3:StNet 和几种最先进的基于 2D / 3D 卷积的解决方案的比较。该结果通过在 Kinetics400 和 Kinetics600 的验证集上得到,其仅具有 RGB 模态。
本文为机器之心发布,转载请联系本公众号获得授权。
✄------------------------------------------------
加入机器之心(全职记者 / 实习生):hr@jiqizhixin.com
投稿或寻求报道:content@jiqizhixin.com
广告 & 商务合作:bd@jiqizhixin.com

