在我们的社会中,多模态数据的日益流行导致了对机器的需求增加,以全面地理解这些数据。然而,渴望研究此类数据的数据科学家和机器学习工程师面临着从现有教程中融合知识的挑战,这些教程通常单独处理每个模态。根据我们在新加坡政府对多模态城市问题反馈进行分类的经验,我们进行了一个手工教程,以希望将机器学习应用于多模态数据。 2021年,作为新加坡政府国家人工智能战略计划的一部分,新加坡政府技术机构(GovTech)的数据科学和人工智能部门(DSAID)构建了一个反馈分析引擎[1],根据市政问题反馈,该引擎可以预测:
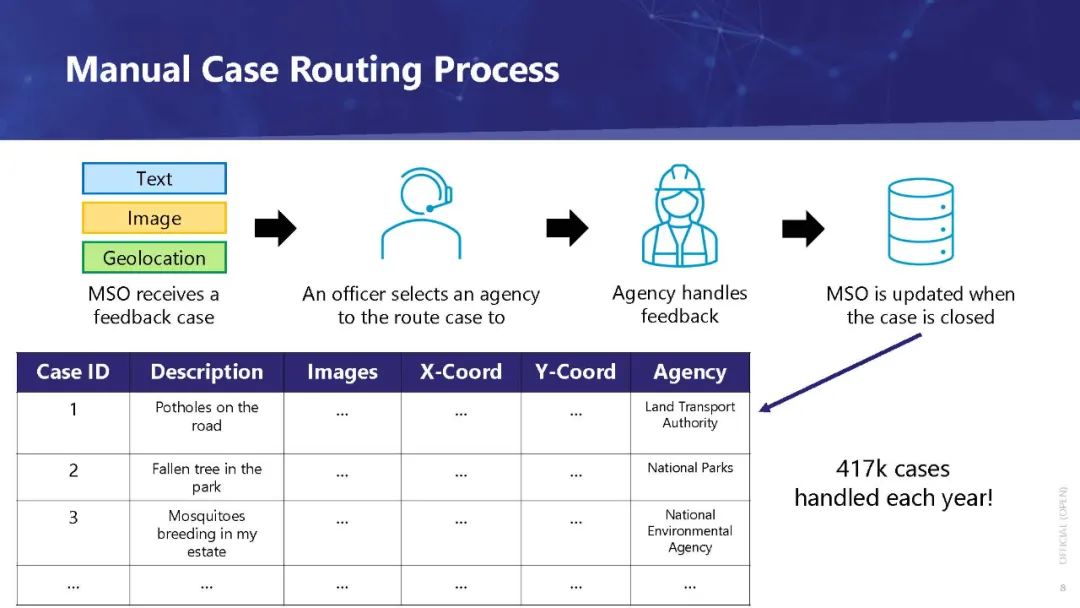
(1)用户反馈的案例类型,以便从反馈中提取相关信息,以及 (2)能最有效地处理这个问题的机构。
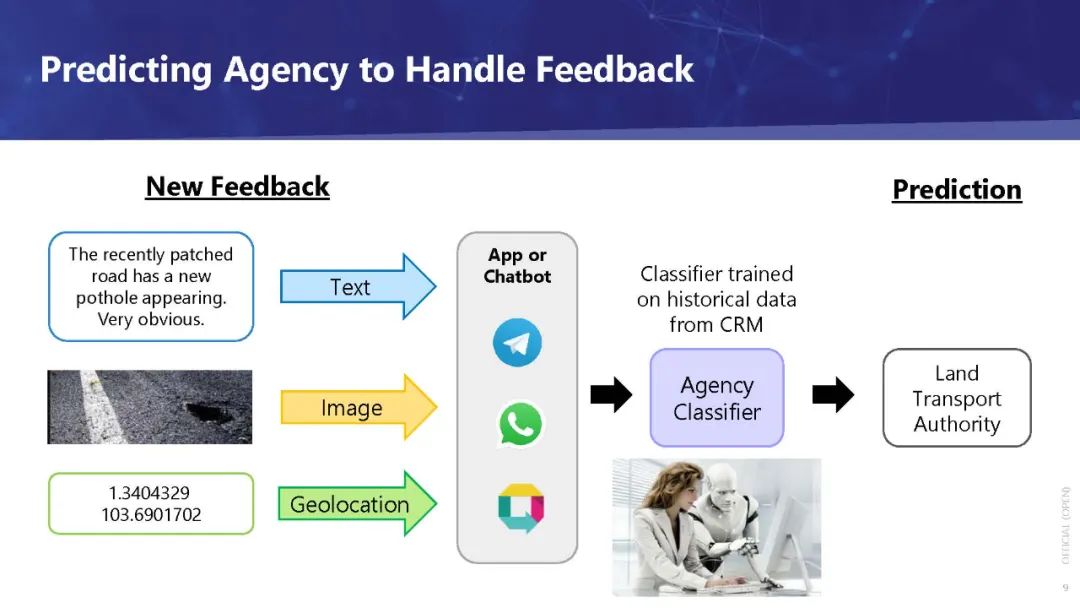
该引擎由基于历史数据的深度学习建立的分类模型组成,实现了良好的准确性,可以部署在OneService聊天机器人[2]中。创建这个引擎的最大挑战之一是处理多模态反馈数据,这些数据包括: (1)文本:对问题的描述, (2)地理位置:问题发生的位置,以及 (3) 图片:补充文字描述的图片。
由于通过移动设备捕捉和传输图像的便捷性,多模态数据,尤其是图文并茂的数据在我们的社会中越来越普遍。除了社交媒体,这类数据在私营和公共部门也都在增长。企业和政府开发了更多、更好的应用程序,这些应用允许人们提交内容(例如,投诉、赞美、建议、技术支持请求、求助电话、产品评论),而不仅仅是文本形式,还附带图片,这样接收者就可以更好地了解手头的问题。随着这类数据的增加,对机器整体理解文本和图像以帮助人类做出决定的需求也在增加。这反过来又导致了对数据科学家和机器学习工程师的需求增加,他们知道如何构建可以做到这一点的模型。然而,大多数与此问题相关的现有教程分别处理文本和图像,因为它们传统上来自不同的领域。对于试图解决此类问题的初级数据科学家(甚至一些中级数据科学家)和机器学习工程师来说,融合来自这些不同教程的知识是一个挑战。我们希望通过本教程帮助他们克服这些挑战。
在本教程中,我们教参与者如何使用Transformer[3]对包含文本和图像的多模态数据进行分****类。它的目标受众是对神经网络有一定的了解,并且能够轻松地编写代码。
(1) 文本分类:使用BERT[4]训练文本分类模型 (2) 文本和图像分类(v1):使用BERT和ResNet-50[5]训练文本和图像分类模型 (3) 文本与图像分类(v2):使用Align before Fuse (ALBEF)[6]训练文本与图像分类模型