![]()
本文介绍的是 CVPR 2020 上录用为 Oral 的论文《Say As You Wish: Fine-grained Control of Image Caption Generation with Abstract Scene Graph》(已开源),文章作者是中国人民大学博士生陈师哲同学,这项工作是陈师哲同学在澳大利亚阿德莱德大学吴琦老师组访问时所完成。
文 | 陈师哲
编 | 贾 伟
![]()
论文链接:https://arxiv.org/abs/2003.00387
代码链接:https://github.com/cshizhe/asg2cap
图像描述生成(Image Captioning)是一个复杂的问题,需要机器掌握多种计算机视觉语义识别技术,例如物体识别、场景识别、属性和关系检测等等,同时还需要将所有检测的结果总结为一个自然语言表述的句子。随着深度学习技术的迅速发展,近期图像描述生成模型取得了相当大的进展,甚至在某些准确度相关指标上超过了人类撰写的文本描述。
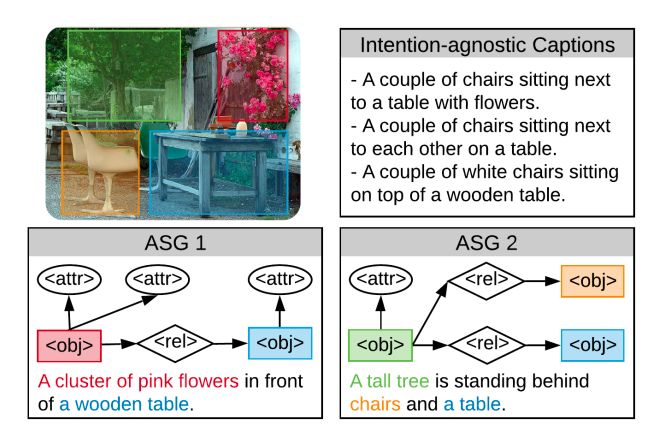
尽管现有模型可以生成较为流利和视觉相关的图像描述,但却存在着与用户交互性差、多样性低等问题。一方面,大多数图像描述模型仅被动地生成句子,并不考虑用户感兴趣的内容或者期望描述的详细程度。例如,在图1中,如果用户希望了解关于花朵的详细信息,我们可以很快地为其说出花的颜色、数量等,但是现有系统却无法满足用户这一简单需求。另一方面,这种被动生成模式容易造成句子缺乏多样性,倾向于使用常见的高频表达生成较为“安全”的句子,较为简单空洞,且缺乏关键性的、用户所需的细节信息。
![]()
图1:意图无关与细粒度可控的图像描述对比。意图无关的图像描述不能生成用户想要描述的内容且缺乏多样性,而所提出的细粒度可控图像描述模型可根据用户意图生成可控的、多样化的图像内容描述。
为了解决上述问题,少数工作提出了主动控制图像描述生成,主要可以分为风格控制和内容控制两类。风格控制是指生成不同风格的图像文本描述,例如幽默、浪漫等等,而内容控制则旨在控制描述的图像内容,例如指定图片的不同区域、不同物体,从而使得模型能够描述用户感兴趣的图片内容。但是,现有工作都仅提供非常粗粒度的控制信号,例如一个类别标签或者图像区域。这些控制信号无法在更细粒度的级别上控制图像描述的生成,例如,是否需要生成物体的属性,要生成多少属性标签;是否需要描述与目标物体相关的物体,以及物体之间的关系是什么;句子的描述顺序应该如何等等。
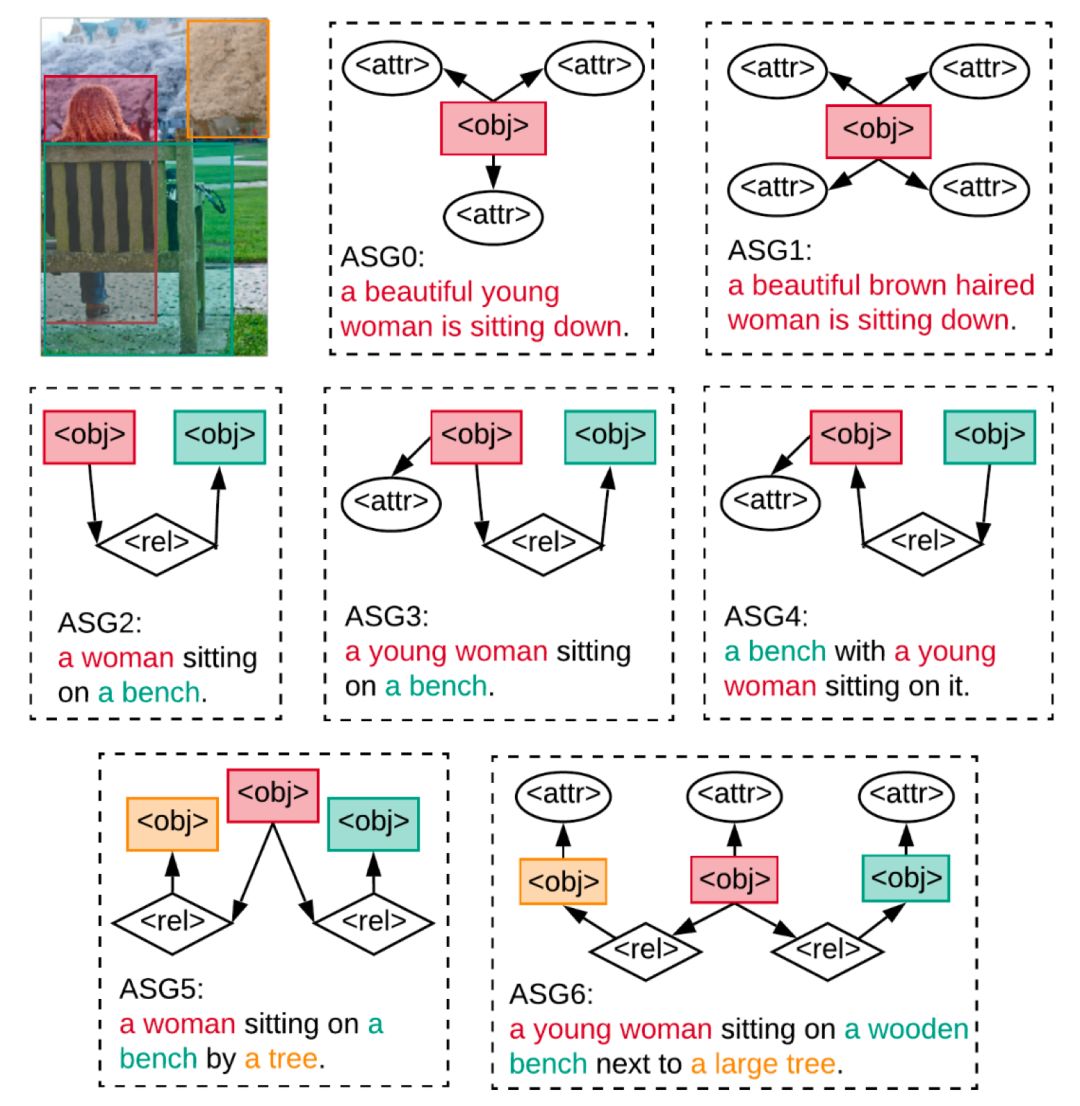
我们认为,一个真正有用以及好用的图像描述生成模型,应该是可控的,因此,我们提出了一种更加细粒度的控制信号,称为抽象场景图(Abstract Scene Graph, ASG),可以通过图结构同时控制所希望表达的物体、属性和关系,不仅能反映用户细粒度的描述意图,也能生成更具有多样性的图像描述。如图1所示,ASG是一个包含三类抽象节点的有向图,这三类抽象节点分别代表用户希望描述的物体(object)、属性(attribute)和关系(relationship),每个抽象节点在图中有具体区域的定位,但却不需要任何具体语义标签。因为ASG不需要任何语义识别,它可以方便地由用户限定或自动生成。
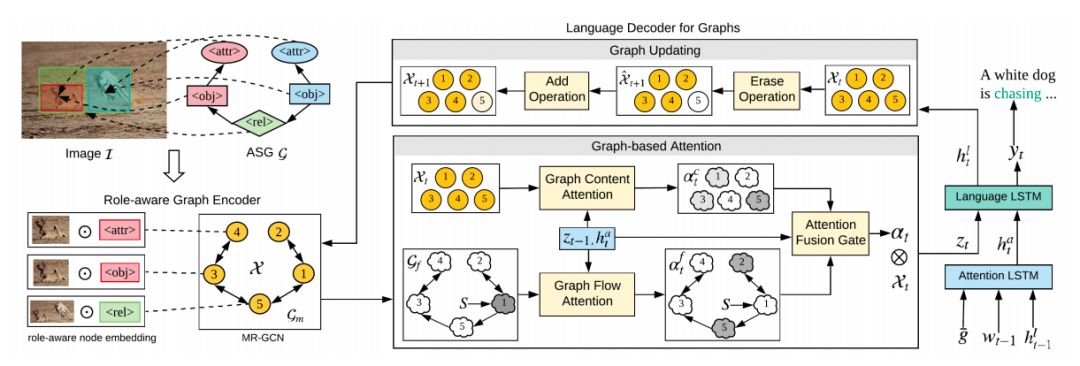
为了基于指定ASG生成图像描述,我们提出了ASG2Caption模型,和普通用于图像描述生成的编码器-解码器框架相比,能够解决ASG控制图像描述生成中的三个主要挑战。
第一,因ASG仅包含抽象的场景框架,无任何语义标签,所以进行编码时既要考虑图中所表达的用户意图,又要识别图中节点的语义。因此,我们提出角色感知的图编码器,以区分不同节点的细粒度意图,并利用图中上下文信息增加每个节点的语义识别能力。
第二,ASG不仅可以通过节点控制需要描述的图片内容,同时也通过节点之间连接的方式隐含地控制了描述的结构顺序。因此,我们提出的解码器使用基于图注意力机制分别考虑节点的语义内容和连接结构,使得模型可以基于图流动顺序描述指定的节点内容。
最后,生成的图像描述需要完全覆盖ASG中指定节点,不能有节点内容的缺失或重复。为此,我们在解码过程中逐渐更新编码的图表示,以记录跟踪图中不同节点的访问状态。
1. 本文首次提出ASG抽象场景图以细粒度地控制图像描述生成。ASG可以控制图像描述生成中的不同细节,例如描述什么物体,是否描述物体的属性,以及物体之间的关系等。
2. 所提出的ASG2Caption模型由角色感知图编码器和基于图的语言解码器构成,能够自动识别ASG中的抽象节点,并根据图中指定的语义内容和描述顺序生成所需的图像描述。
3. 由于缺乏具有ASG标注的数据集,我们基于已有图像描述数据集VisualGenome 和 MSCOCO自动构建ASG标签进行训练和测试。我们的模型在这两个数据集上都取得了更好的控制性。此外,模型可基于多样化的ASG生成更具有多样性的图像描述。
![]()
图2. 细粒度可控图像描述ASG2Caption模型框架图。
1、抽象场景图 (Abstract Scene Graph, ASG)
为了细粒度地表达用户意图,我们提出抽象场景图概念(Abstract Scene Graph, ASG)作为控制信号,以生成自定义的图像描述。
如图2左上方所示,ASG中的节点根据意图角色可分为三类:物体节点(object node),属性节点(attribute node)和关系节点 (relationship node)。
如果用户对物体o感兴趣,则可将o在图像的区域添加到ASG中作为物体节点;如果用户希望了解关于物体o的更多细节信息,可以为其添加不同数目的属性节点a,并建立a与o之间的有向边;如果用户希望描述两个物体之间的关系,可在物体间添加一个关系节点r,并建立从关系的主语物体指向r和r指向关系的宾语物体的两条边。
由于ASG不需要任何语义标签,我们仅需要使用预训练的object proposal generator,以及一个简单的判断物体间是否存在关系的二分类器, 就可自动地生成不同的ASG。同时,用户也可以方便地构建抽象场景图ASG,用户不需要繁琐地构建完整的ASG,仅需像前人工作一样指定关注的物体或者想描述的详细程度等,我们可通过算法根据用户需求自动生成完整的ASG用于控制,从而具有良好的用户交互性。
给定图像和指定的ASG,模型目标是生成流利的文本描述,使其严格按照ASG的控制以满足用户的意图。该模型整体框架如图 2所示,包括角色感知图编码器和基于图的语言解码器。
2.1 角色感知图编码器:用于对图像和场景抽象图ASG 编码。
由于节点除需要刻画其在图像中对应的视觉特征外,还应反映出它的意图角色。这由于对于区分具有相同图像区域的节点来说至关重要,例如对应于同一区域的物体节点和属性节点。因此,我们提出使用角色感知向量增强节点表征,得到意图角色相关的节点表示。
由于ASG中的节点不是孤立的,相邻节点的上下文信息有益于理解节点的语义和角色信息。尽管ASG中的边是单向的,但节点之间的影响却是相互的。此外,由于节点的类型不同,信息从一种类型节点传递到另一种类型节点的传递方式与其反方向也是不同的。因此,我们将原始ASG的边扩展为不同的双向边,从而生成一个具有多关系的图,利用多关系图卷积神经网络(MR-GCN)进行图中上下文编码。。
2.2 基于图的语言解码器: 旨在将编码的图转换为图像文本描述。
与之前基于独立的图像向量集合进行解码不同,编码的图不仅包括节点特征表示,还具有图中结构化的连接关系。其中,节点的连接方式反映了用户所希望的描述顺序,不能够被解码器所忽略。例如,如果当前关注的节点为关系节点,那么根据图的流向,下一个需要访问的节点很可能是连接该关系节点的宾语物体节点。
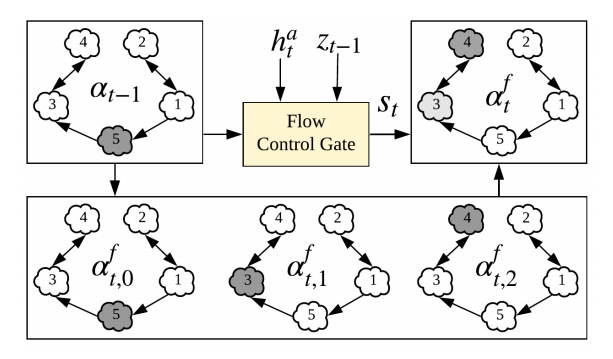
为了同时考虑图中语义内容和图结构信息,我们结合了两种不同的注意力机制,分别称为图语义注意力和图流向注意力。图语义注意力考虑查询向量与图编码向量之间的语义相关性;图流向注意力用于刻画图中的结构流向信息,如图3所示。最后,图注意力机制动态地融合了图语义注意力和图流向注意力。
![]()
图3. 图流向注意力机制考虑图结构信息对图像描述生成的影响。
为满足用户的意图需求,ASG中所有节点都应被文本描述所表达,不能出现缺失或者重复的现象。因此,为了提高从编码图到句子描述的质量,我们提出了一个动态记录图节点访问状态的图更新机制。在每个解码步,我们先将已表达过的ASG中的节点进行动态擦除,如果一个节点并不需要再表达,则可置为0;然后动态写入新的节点信息,更新图中节点的特征表示,以记录不同节点的访问状态。
我们基于两个广泛使用的图像描述数据集VisualGenome和 MSCOCO的标注,自动构建细粒度可控模型所需的训练数据。其中, MSCOCO数据集的ASG比VisualGenome数据集更为复杂,包含更多的关系节点和更长的文本描述。
我们分别从可控性(Controllability)和多样性(Diversity)两个方面评测生成的图像描述质量。
由于细粒度可控图像描述生成是一个新的任务,我们基于现有模型精心设计了以下两类基线模型进行比较。第一类为传统意图无关的图像描述生成模型,第二类模型将上述模型扩展为基于ASG控制的图像描述生成模型。
![]()
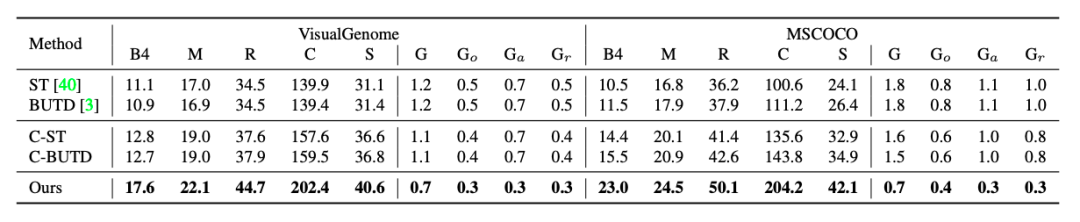
表1:不同模型基于ASG的可控图像描述生成性能对比。
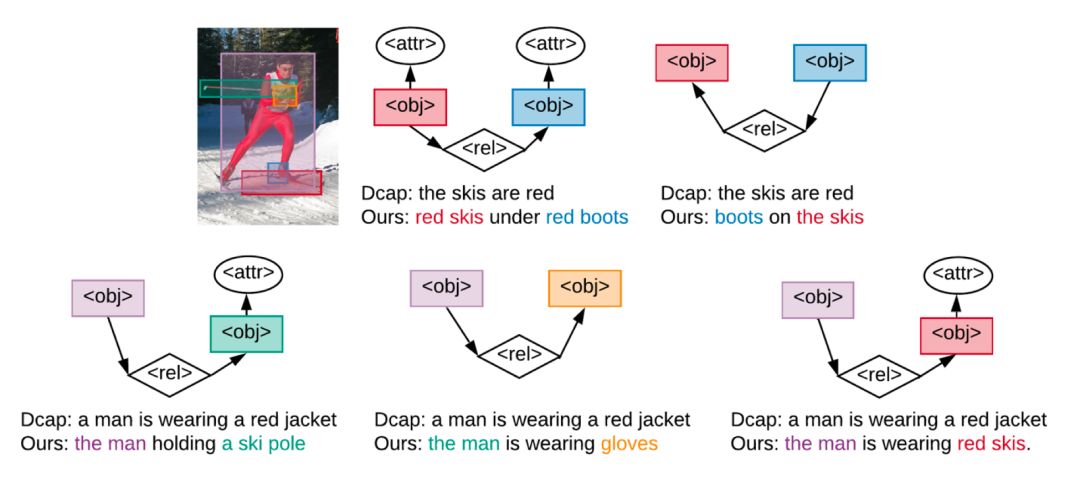
表1比较了不同模型的结果。由于控制信号ASG与标注的文本描述对应,可控类模型性能明显由于意图无关的无控制模型。所提出的ASG2Caption模型在所有的评价指标上都显著地超过了基线模型性能,包括整体图像描述质量和ASG结构对齐性能。尤其对于细粒度的属性控制,我们将属性对齐误差减少了将近一半。图4为基于用户生成的ASG控制图像描述生成的例子。
图4. 模型根据用户指定的不同ASG生成的可控图像文本描述。ASG中细微的差别(例如边的方向)也代表了用户的不同意图,将使得模型生成不同的图像描述。
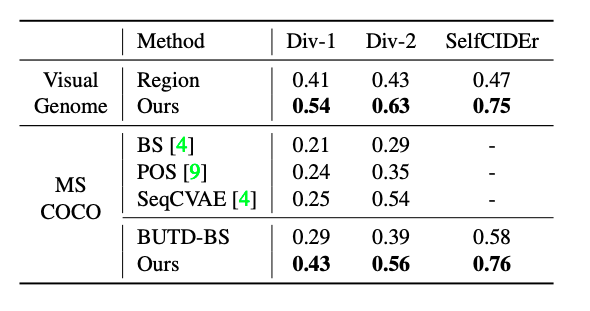
基于ASG控制的图像描述生成的一个好处是可以基于多样化的ASG生成不同的图像描述,以不同层次的细节描述不同方面的图像内容。我们与现有多样性评测最佳的方法进行比较,结果见表2,我们模型生成的图像描述具有更高的多样性。
![]()
表2. 和现有最佳模型比较多样化的图像文本描述生成。
图5展示了为示例图像自动采样生成的不同ASG及其对应生成的可控图像描述。
图5. 基于自动采样的ASG生成多样化图像描述示例
生成的描述有效地按照给定ASG进行句子生成,由于ASGs的多样性使得我们的模型能产生显著多样化的图像文本描述。
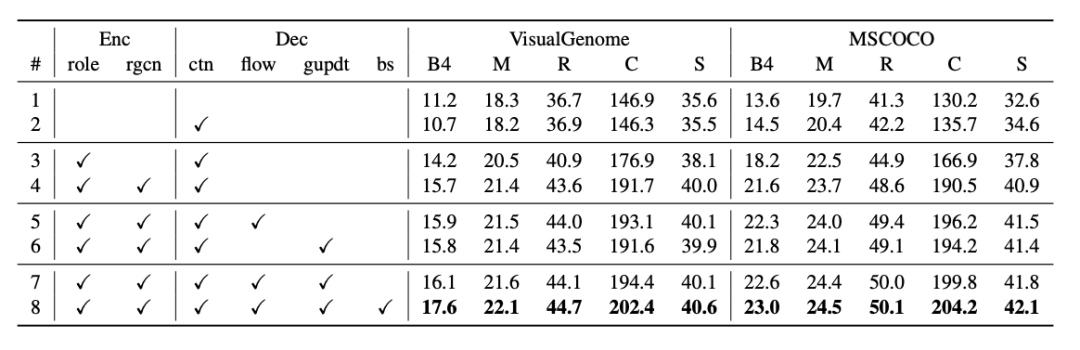
为验证ASG2Caption模型中不同部件的贡献,我们在表3中提供了大量的消融实验结果。所提出的不同模块均对性能具有帮助。
![]()
表3. ASG2Caption模型各组件贡献的消融实验。
现有大部分图像描述工作都是被动地生成句子,完全由训练集中数据的样式来决定可能生成的句子的样式,不能与用户交互自由控制,而且往往多样性也很低。
因此,在这篇论文中,我们探索了一种细粒度的控制信号ASG,用于控制生成的图像描述应该关注图像中的哪些物体、关系、描述的详细程度等,并提出ASG2Caption模型基于图控制生成图像描述。通过这种细粒度控制,我们不仅可以实现更好的交互性、可解释性,同时也使得生成的描述更具有多样性。
文章代码已开源:
https://github.com/cshizhe/asg2cap
CVPR 2020 系列报道
相关报道:
CVPR 2020接收论文公布:录用1470篇,接收率“二连降”,仅22% !
论文集:
17篇入选CVPR 2020,腾讯优图 9 篇精选论文详解
论文解读:
01. [微软] 古有照妖镜,今有换脸识别机,微软 CVPR 2020力作,让伪造人脸无处遁形
02. [港大] PolarMask:将实例分割统一到FCN,有望在工业界大规模应用
03. [牛津大学] RandLA-Net:大场景三维点云语义分割新框架(已开源)
04. [北大&华为] CIFAR-10上做NAS,仅需单卡半天!华为提出基于进化算法和权值共享CARS模型
05. [南京大学] 化繁为简,弱监督目标定位领域的新SOTA - 伪监督目标定位方法
06. [UC 伯克利] 挑战 11 种 GAN的图像真伪,DeepFake鉴别一点都不难
07. [哈斯特帕大学] 学习一个宫崎骏画风的图像风格转换GAN
![]()
![]()
![]() 点击“阅读原文” 查看 更多论文解读
点击“阅读原文” 查看 更多论文解读