综述:Image Caption 任务之语句多样性

作者丨郑逸
学校丨复旦大学媒体计算实验室
研究方向丨Image Caption
知乎丨https://zhihu.com/people/zheng-yi-49-69/
Image Caption 任务是一个需要综合计算机视觉和自然语言处理的任务,需要使用计算机建立某种映射方式,将处于视觉模态当中的数据映射到文本模态当中。
总的来说,这样的映射任务需要如下两个基本需求:1)语法的正确性,映射的过程当中需要遵循自然语言的语法,使得结果具有可读性;2)描述的丰富程度,生成的描述需要能够准确描述对应图片的细节,产生足够复杂的描述。
然而目前应用最广泛的“编码器-解码器”模型使用交叉熵作为损失函数训练参数,这种方法带来的弊端在于,模型会趋向于生成更加“安全”的语句描述,在两幅场景相似但细节不同的图像上,模型会趋向于给出一个更宽泛的描述,忽视了图像的具体细节。

▲ 图1
如图 1 所示,在两幅图像内容相似、但整体环境存在明显差异的情况下,人在描述的过程中能够凭直觉注意到这两幅图像的相似性,并且可以根据这种相似性给两幅图像生成细节描述对其进行区分。但目前使用交叉熵作为损失函数的方法却无法做到,其给出的描述完全一致,忽视了图像的细节特征。ATTN + CIDER 表示使用注意力机制、基于 CIDER 的强化学习方法训练模型。
因此为了解决句子的多样性问题,研究者提出了以下几种在目前看来十分有效的解决方法。
ICCV 2017


文章首先给出了一组对比 MLE(使用交叉熵作为损失函数,最大似然概率),G-GAN(使用生成模型的方式,下文将详细说明)和人类的具体描述方式,如图 2 所示。

▲ 图2
可以看出相比较于 MLE 方法,使用 GAN 生成的结果在句法结构上更加复杂,对于细节的描述非常丰富。使用 MLE 的方法导致生成结果非常死板,语句模式单一,这也是上文所提到的机器更趋向于更“安全”的结果的量化体现。
因此文章提出使用 Conditional GAN 的方法作为生成模型用于生成描述,通过 GAN 的 evaluator 去评价语句描述是否由“人”描述得到,具体方法论如下介绍(下面的介绍默认理解 conditional GAN)。
Generator G,生成模型需要两个输入,图像的特征(经过 CNN 编码)f(I) 和随机的噪声变量 Z,图像特征作为条件变量用于控制生成结果的范围在描述特定的图片,噪声变量用于控制生成结果的多样性。最终生成模型通过 LSTM 作为解码器生成句子。
Evaluator E 也是一个神经网络,网络模型框架和 G 相似,但参数是不共享的,可以理解为结构相似、但实际不同的两个模型。E 通过给定图片和描述的正确配对,通过 CNN 和 LSTM 将其编码映射到相同的语义空间(具体方法感兴趣可以了解跨模态的图文匹配方法),将其点乘根据 logistic function 得到一个 [0,1] 的概率值表示得分,详细公式如下:
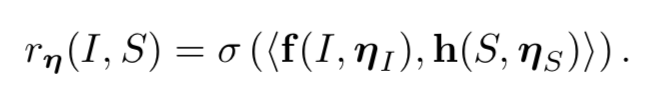
从逻辑上来理解学习的目标函数(实际上在解释 GAN 的逻辑意义),生成模型 G 的目标是使得生成结果能够更加自然,从而“骗得”评价模型 E 能够将其误认为是“人”的描述结果;评价模型 E 的目标是使得能够准确识别句子的来源是“机器”还是“人”,通过循环训练,这个过程将会达到一种动态平衡,从而使得生成模型的结果和真实结果相差无几,并且评价模型最终达到随机判断的形式(即输出 0.5)。
量化的目标函数如下公式所示:
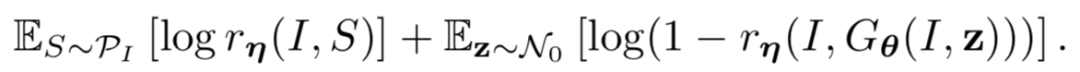
在这里需要注意的是,提出这样一种使用 GAN 的方法训练模型可以取代使用 MLE 的方法训练,从而避免上述使用 MLE 可能出现的问题。
训练 Generator G
此处有一个关键问题,在生成模型单词到单词生成句子的过程中,每生成一个单词都是一个离散的采样过程,在数学上可将其理解为一个不可微的过程,不解决这个问题就无法使用反向传播方法对模型参数进行更新。
为了解决这个问题,我们需要使用 policy gradient 的方法对不可微的过程进行一次建模(属于强化学习的范畴,具体公式推导在此不做说明)。值得一提的是,目前 GAN 的方法在图像领域取得的效果很好,但在 NLP 领域好像没有看到什么非常优秀的结果。
因此目前需要解决的问题为:如何将从 E 当中获得的 feedback 用于反向传播。使用 policy gradient 的基本思想是把一个句子中的所有单词考虑为多个动作 action,每个时间段 t 的 action 就是基于条件概率的一个采样,当采样到结束符 <EOS> 时便完成了句子的生成工作。在采样结束之后,我们就能通过 evaluator 得到一个评价,进而可以根据此评价对参数进行更新。
然而这里存在另一个问题,就是需要等到整个句子生成结束后才能够得到结果。这显然会有很多问题,比如误差会被积累,或者梯度弥散、梯度爆炸等一系列的问题。
为了解决这个问题,作者在论文中采用了 early feedback 的方式,即可以在句子生成尚未结束时求解期望 reward,具体形式如下公式所示:
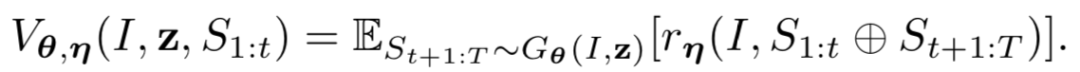
这里具体使用的是蒙特卡洛采样方式,t 时刻之前的是真实生成的结果,之后的是通过采样法得到的结果。总的梯度可以表示为如下公式,具体解释详见论文。
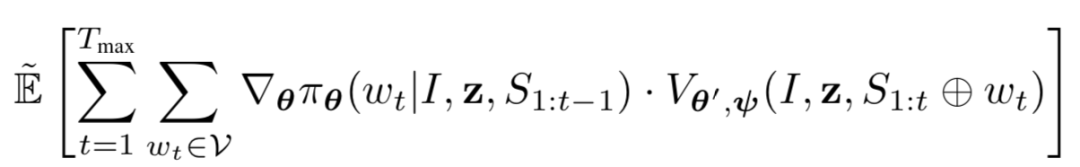
这样一来,就可以解决使用不可微采样并通过反向传播方法优化参数,同时通过蒙特卡洛采样可在任意时刻求得 reward,加快优化速度。
训练 Evaluator E
E 的逻辑理解目标在于评价描述 S 是否能准确、自然、丰富地描述给定图片 I,给出的输出是一个 [0,1] 之间的值,越大表示描述越好。
为了能够加强 E 的能力,在真实的目标函数中除了引入 I 所对应的真实结果和生成预测结果,还需要引入真实的但对应其他图片的一个结果,即总共 3 种来源不同的语句描述。目的是加强真实语句的得分,抑制其他两个来源的句子得分。这一表示形式的建模可以表示为如下公式:
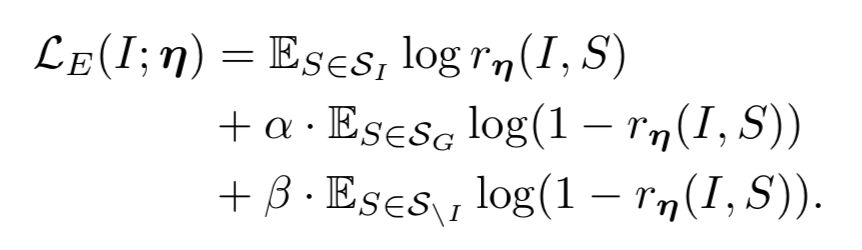
Extensions for Generating Paragraphs
在这篇文章中,作者还做了生成段落描述的实验,在此不再赘述,感兴趣的话可以 follow 层次结构的 LSTM 和斯坦福的 DenseCap。 最终论文的实验和量化分析感兴趣的话可以参考论文,此文仅对模型的使用方法做出自己的理解,结果究竟好坏还需要读者自行拿捏。
CVPR 2017


这篇文章主要研究了在给定两个相近标注时,如何能根据描述中的不同具体细节,忽略其相同部分并索引到正确的图片。文章提出的方法可以称为 speaker-listener 模型,从本质上来说和上文的 generator-evaluator 模型较为相似。
本文除了考虑 discriminative image caption 任务之外,还提出了 justification 这一任务。基于这个任务,论文给出了一个新的数据集。在下文中,笔者将仅针对 caption 任务进行讨论。
在总体介绍之前先对部分符号表示做出规范,sentence s, a sequence of words{}, image I, target concept , distractor concept , distractor concept 表示相似的语句但是对应到不同的图片,加强模型对句子细节的理解。
Reasoning Speaker
Speaker 对给定图片和正确语句的概率进行建模,即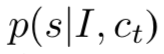
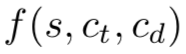
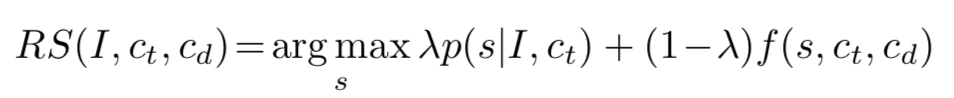
▲ 公式1
前一项表示描述的精确度,后一项表示丰富程度,即区别程度。同时文章也提到这样的建模方式会产生以下两种无法避免的问题:
1. 预测的过程在指数级的空间当中,是一个无法追踪的状态;
2. 不希望 listener 在建模过程中对句子分解在单词的层面上进行判断,而是希望模型将句子看作一个整体进行判断。
Introspective Speaker
作者为了解决这一问题,将 listener 相较于以前的方法做出了改变,具体表现为 log 似然函数的一个比例,形式如下:
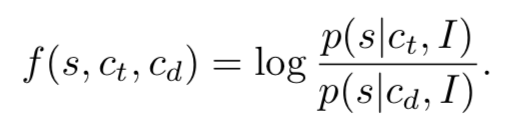
这样的 listener 建模方法只基于生成模型 G,即 speaker,作者将其命名为内省法(introspective),优点在于重用了生成模型,不引入多余的训练步骤完成了对 listener 的建模。因此公式 1 可以改写为:
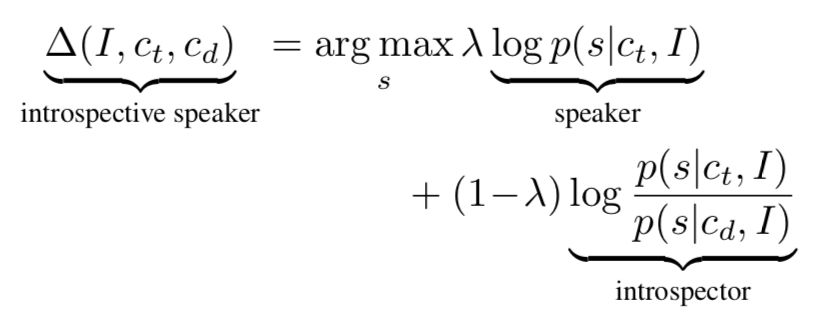
▲ 公式2
Emitter-Suppressor (ES) Beam Search for RNNs
公式 2 利用马尔科夫链和贝叶斯公式可以改写为:
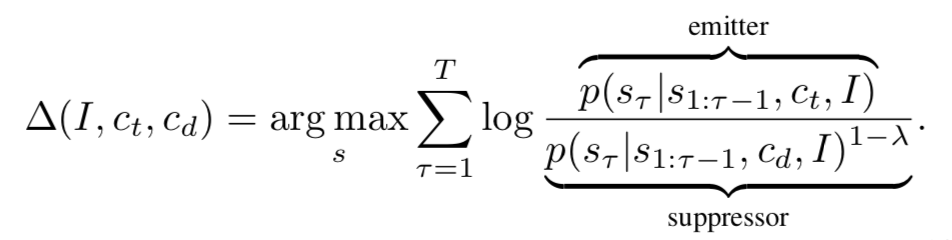
如果对具体的数学公式推导不感兴趣,下图可以从图形的方式量化理解这一训练过程。
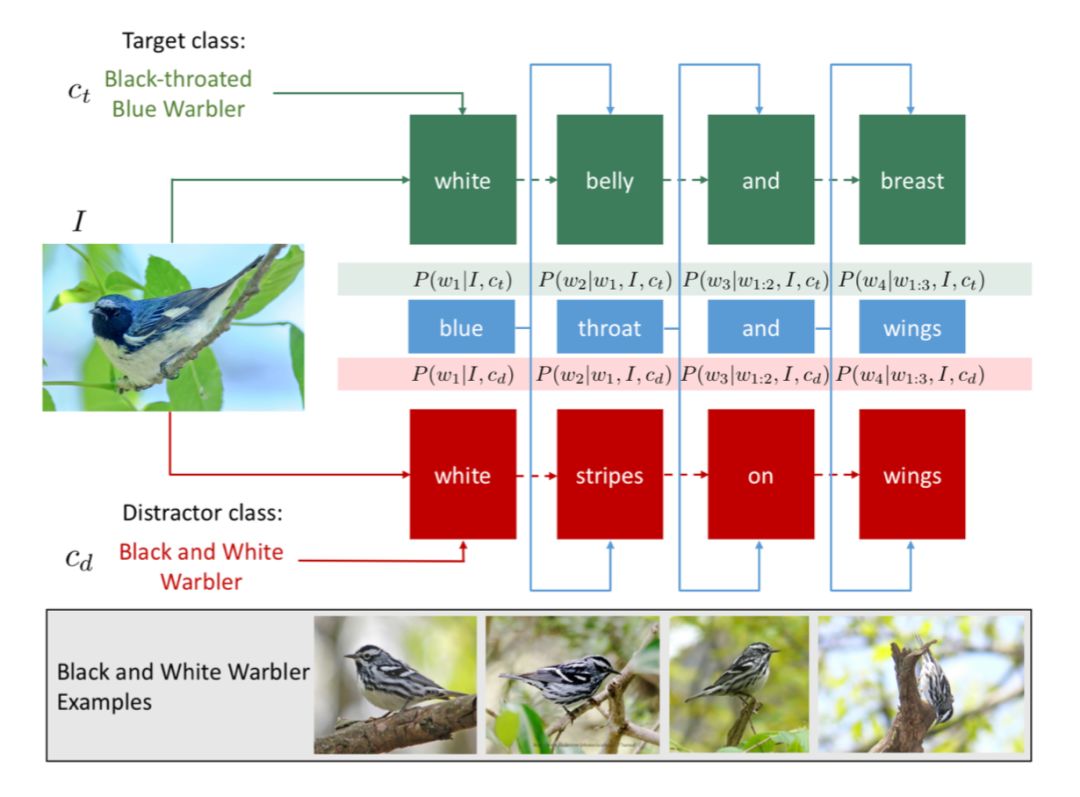
▲ 图3
如图 3 所示,绿色背景的字表示正确对应描述,红色背景的字表示相似图片对应的描述,蓝色表示使用 RS 模型得到的结果。可以看出同时出现的”white”单词将会被抑制,只出现在正确描述、但没有出现在迷惑描述中的”blue”将被选中, 从而可以得到对应图片的更加细节的表述。
将这样的思想应用在 discriminative image caption 领域当中,对应的真实数据和迷惑数据将表示为图片,在两幅相似图片的基础下,获取对应图片的细节信息从而生成更准确的描述。具体公式表示如下:
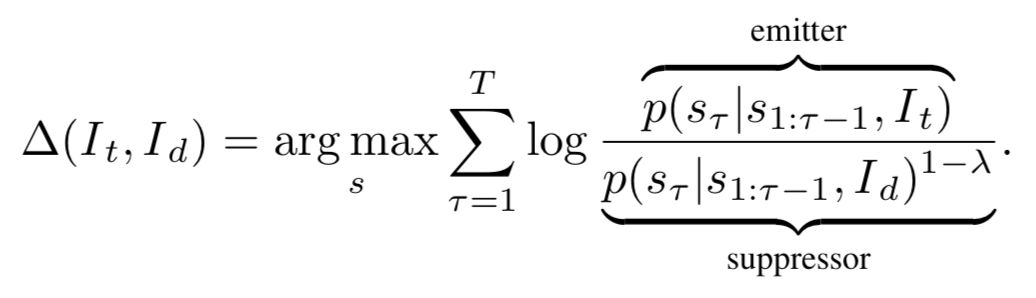
这篇文章的贡献在于做了大量具体实验和分析,在此不赘述,是一篇值得看的好文。
NIPS 2017


这篇文章提出了一个新的方法:对比学习模式,与上一篇文章的反省学习方法有借鉴意义,值得一提的是,这篇文章的第一作者就是第一篇使用 GAN 方法的作者。
本文方法受启发于噪声对比估计(Noise Contrastive Estimation, NCE),具体 NCE 的介绍可以查看如下链接,主要用于 NLP 当中:
https://blog.csdn.net/littlely_ll/article/details/79252064
需要注意的是,不同于上文其他两个方法,本文是对传统 MLE 方法的一个“颠覆”操作,作者使用的方法可以作为一个插件,用于修正任何模型的生成结果。
Self Retrieval
无论使用什么方法增强句子的丰富程度,但要找到一个合适的、标量化的评价标准,对句子的丰富程度做出准确评价是一个比较复杂的任务。
基于此任务需求,本文提出了一种“自我检索”方式,使用生成的描述语句来检索图片,根据检索到图片的准确率来标量化句子的丰富程度。这一方法从经验上来看具有可参考性,一个丰富的句子所具有的特性一定是 discriminative,学习到了图片的具体细节,从理论上说应该可以根据这些细节还原原始的图像。
Contrastive Learning
在对比学习中,我们需要学习的模型建模为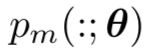
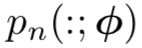
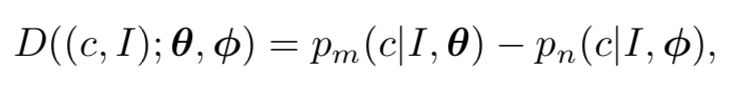
▲ 公式3
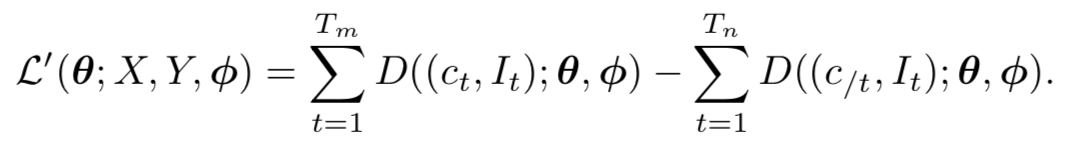
▲ 公式4
在具体的建模过程中,如果直接使用上述建模方式,将会遇到如下几个问题:
1. 使用概率值的差,但实际情况当中,概率值较小,因此可能会引起数值问题;
2. 因为样本的随机采样,公式 4 对简单数据将会非常容易判断(不匹配数据完全不相关),而对于困难数据(即不匹配数据和真实数据的相关性较高)则不尽如人意。显然,我们不能将所有数据对损失函数的贡献一视同仁。
为了解决这两个问题,需要使用 NCE 中的方法。
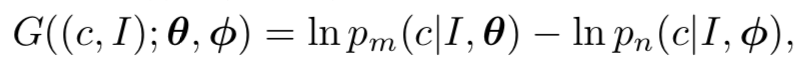
▲ 公式5
首先需要将公式 3 改写为公式 5 的形式,即使用 log 函数计算概率值,原本 [0,1] 之间的概率值可以被建模为 [-infinity, 0],避免了数值问题的影响。同时引入 logistic function 针对不同数据对 loss 的不同贡献度进行建模,如以下公式所示:
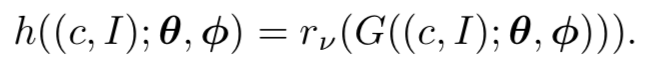
在 logistic function 的作用下,针对容易的数据,函数值将会落入梯度较小的区域从而对最终结果的影响较小。通过这种方法得到的最终损失函数如下:
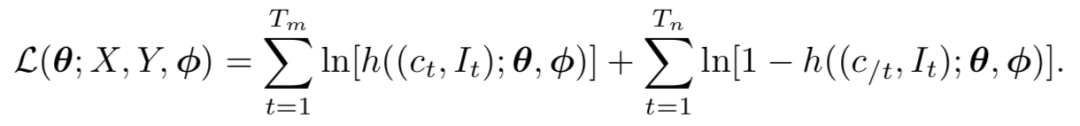
具体在采样过程中如何采样迷惑数据,以及如何选择迷惑数据的方式详见论文实验部分。
总结
目前看来,Image Caption 任务的性能虽在得到不断改善,但如何使机器能够更加贴近人类的思维模式仍是目前急需解决的问题之一,在这个任务中即反应为如何能够生成更加多元话的结果。

点击以下标题查看更多往期内容:
关于PaperWeekly
PaperWeekly 是一个推荐、解读、讨论、报道人工智能前沿论文成果的学术平台。如果你研究或从事 AI 领域,欢迎在公众号后台点击「交流群」,小助手将把你带入 PaperWeekly 的交流群里。

▽ 点击 | 阅读原文 | 获取最新论文推荐



