
GNN是当下关注的焦点,以往研究提出了各种各样的GNN算法模型,但是就GNN加速还缺乏综述性调研。来自中科院计算所、清华大学等学者发布了《图神经网络加速算法研究》综述论文阐述GNN加速算法体系值得关注!

图神经网络(GNN)是近年来研究的一个热点,在各种应用中得到了广泛的应用。然而,随着使用更大的数据和更深入的模型,毫无疑问,迫切需要加速GNN以实现更高效的执行。在本文中,我们从算法的角度对GNN的加速方法进行了全面的研究。我们首先提出一种新的分类法,将现有的加速方法分为五类。在分类的基础上,对这些方法进行了系统的讨论,并重点讨论了它们之间的相关性。接下来,我们对这些方法的效率和特点进行了比较。最后,对未来的研究提出了展望。
https://www.zhuanzhi.ai/paper/12669ebd689ecd66a552eb36ed6946ef
引言
图神经网络(GNN) [Scarselli et al., 2008]是一种基于深度学习的模型,将神经网络应用于图学习和表示。它们是基于理论的[Pope et al., 2019; Ying et al., 2019]和技术熟练[Kipf and Welling, 2017; Velickovi ˇ c´ et al., 2018],在不同的图形相关任务上保持最先进的性能[Hamilton et al., 2017; Xu et al., 2019]。近年来,由于GNNs在各种应用方面取得了显著的成功,人们对GNNs的研究兴趣不断增加,这加速了关注不同研究领域的综述的出现。一些综述[Wu et al., 2020; Zhang et al., 2020; Battaglia et al., 2018]密切关注GNN模型和通用应用,而其他人[Wang et al., 2021b; Zhang et al., 2021]强调GNNs的具体用法。此外,硬件相关架构[Abadal et al., 2021; Han et al., 2021];研究人员还着重考察了GNN的软件相关算法[Lamb et al., 2020]。因此,上述综述进一步促进了GNN的广泛使用。然而,随着GNN在新兴场景中的广泛应用,人们发现GNN存在一些障碍,导致其执行缓慢。接下来,我们将讨论限制GNN执行效率的障碍,并提出我们的动机。
动机: 为什么GNN需要加速?
首先,图数据的爆炸式增长对大规模数据集上的GNN训练提出了巨大的挑战。以前,许多基于图的任务通常是在小规模数据集上执行的,这些数据集与实际应用中的图相比相对较小,这不利于模型的可扩展性和实际使用。因此,文献[Hu et al., 2020a]提出了在大规模的图数据集进行深入研究,使得GNNs的执行(即训练和推断)一个耗时的过程。其次,在巧妙避免过平滑问题的前提下[Rong et al., 2020],使用更深层、更复杂的结构是获得具有良好表达能力的GNN模型的一种有希望的方法[Chiang et al., 2019; Rong et al., 2020],另一方面,这将增加训练表现良好模型的时间成本。第三,特殊设备,如边缘设备,一般对GNN训练和推理有严格的时间限制,特别是在时间敏感的任务中。由于计算和存储资源有限,这些设备上的训练和推理时间很容易变得难以忍受。因此,无论在训练还是推理方面,都迫切需要对GNN进行加速。
然而,目前还没有文献从算法层面系统地研究GNN的加速方法。实际上,算法级别的改进不仅提高了模型的精度,而且加速了模型的学习[Chen et al., 2018b; Bojchevski et al., 2020]。我们认为,GNN的算法加速方法将大大有利于训练和推理过程,同时,GNN框架的整体性能[Fey and Lenssen, 2019; Wang et al., 2019a],因为一个设计良好的框架加上一个优化的算法可以从经验上获得双重提升[Lin et al., 2020]。因此,尽管有一些关于图相关框架和硬件加速器的有见地的综述,但对GNN算法加速方法的全面综述是非常值得期待的,这正是本工作的目标和重点。
本文从算法的角度对gnn的加速方法进行了全面的综述,重点介绍了算法层和模型层的改进。综上所述,我们的贡献如下:
-
新分类(New Taxonomy):我们将现有方法分为五类,采用双层分类法,综合考虑优化因素和核心机制(见第2节)。
-
系统回顾:我们对现有的方法进行全面的综述,并对这些方法进行分类介绍。此外,我们着重讨论这些方法之间的共同点和独特之处(见第3节)。
-
综合比较: 我们对典型加速方法的训练时间性能进行总结,并进一步从整体上进行综合比较,其中特别突出了这些方法之间的相关性(见第4节)。
-
未来展望: 在总体比较的基础上,我们讨论了GNN加速的一些潜在前景,以供参考(见第5节)。
图神经网络加速体系
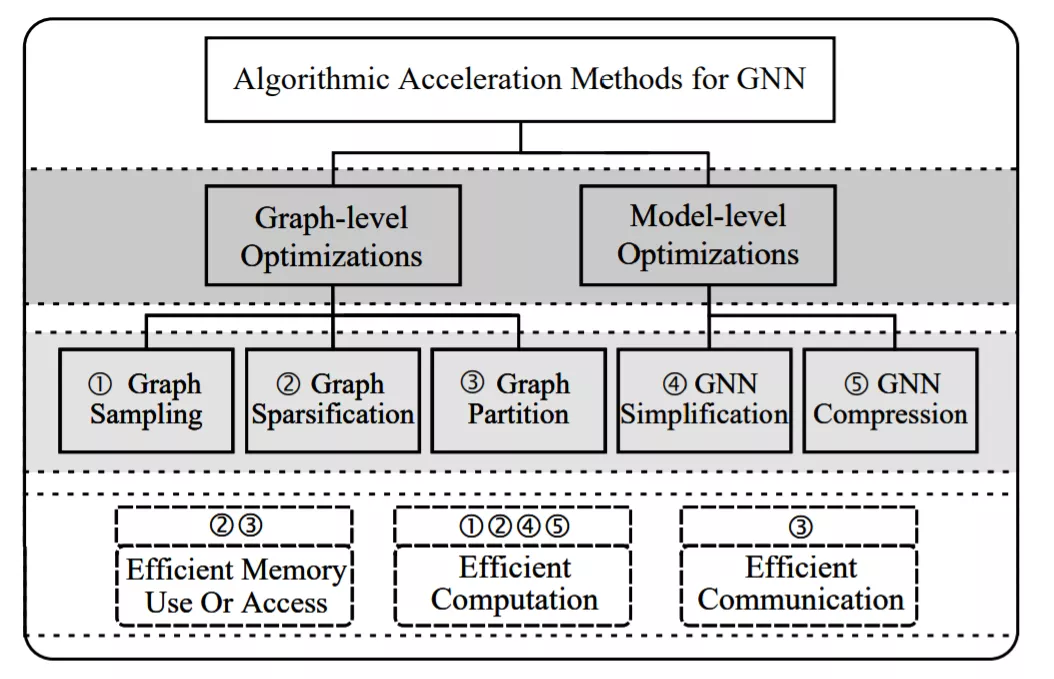
GNN加速方法的分类。通过双层决策,即GNN执行的优化因子(第一级)和这些方法的核心机制(第二级),将这些方法分为五类。此外,它们的目标强调了五类方法。例如,“图稀疏化”和“图分区”方法可以通过高效的内存访问或使用来加速GNN的执行。
图1展示了现有GNN算法加速方法的双层分类。首先,根据优化因子将方法分为两大类。“图级”是指通过修改图的拓扑或密度,对用于训练和推理的图进行优化。“模型级”表示对GNN的模型进行优化,包括对模型结构或权重的修改。并根据执行机制将这些方法分为五类,即图采样算法、图稀疏化算法、图划分算法、GNN简化算法和GNN压缩算法。以“图采样”为例,表示用一种特定的采样方法来训练模型,加快收敛速度。在最后一层,我们通过优化目标来标记这些方法,例如,图采样通过降低计算成本来获得加速。详细的讨论将在第3节中给出。
图神经网络加速方法
Graph-level改进
传统的GNN,特别是GCNs的训练是全批处理的,限制了每次模型更新一次
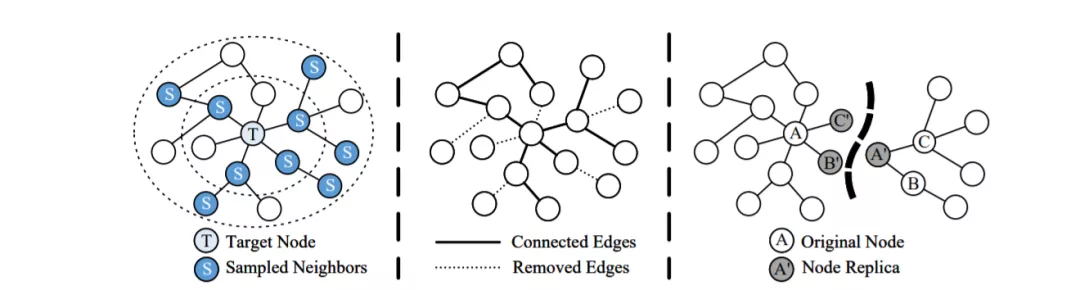
图级改进的说明: (a) 对2跳邻居进行抽样的图抽样方法; (b) 一种去除无用边的图稀疏化方法; c)一种图分区方法,将图划分为两个保存了节点副本的子图。
Model-Level 改进
模型简化
GNN简化是一种特定于模型的方法,它简化了GNN中的操作流程,旨在提高GNN训练和推理的计算效率。广泛应用的GNN模型GCN的层传播如式1所示,将空间维上的邻近信息线性聚合和非线性激活相结合,更新节点表示。
模型压缩
目前的深度学习应用通常严重依赖于庞大的数据和复杂的模型。这样的模型具有很好的代表性,但是包含了数亿个参数,使得模型训练成为一个难以忍受的耗时过程。模型压缩技术是将复杂的模型,如深度神经网络(DNNs)[Cheng et al., 2017],压缩为保存的参数通常较少的轻量级模型,广泛用于加速训练和推理,节省计算成本。本文回顾了在GNN中应用模型压缩以提高计算效率的新趋势,并根据其机理对这些方法进行了讨论。
图神经网络加速方法比较与分析
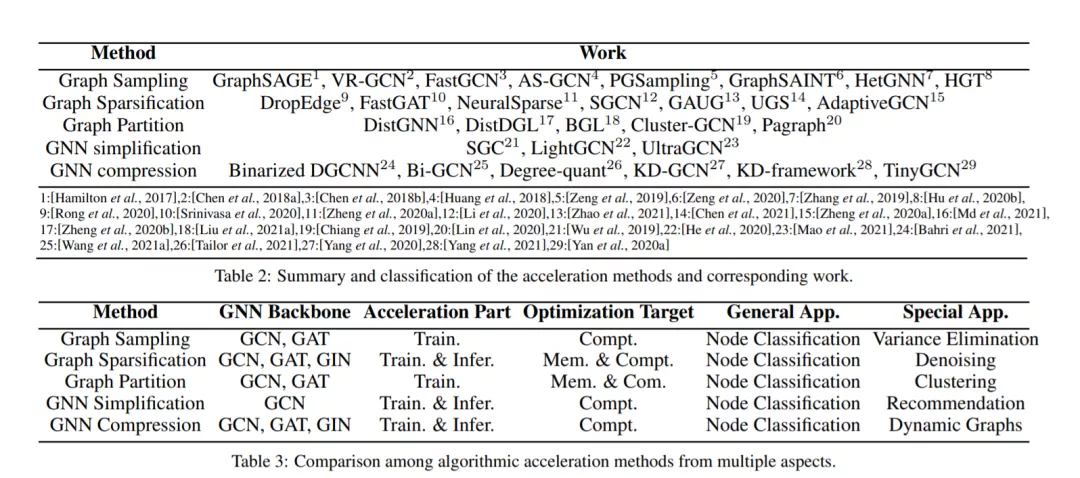
在本节中,模型效率(通过相对训练时间反映)的比较如图3所示。请注意,不同类别的方法是用链线划分的,而相同类别的方法使用相同的数据集和平台进行比较。所有数据均来自文献[Liu et al., 2021b;Mao等人,2021年;Md等,2021]。我们还在表2和表3中对现有方法进行了全面的总结和比较。我们特别注意以下几个方面。
总结与未来展望
本文对GNN算法的加速方法进行了全面的综述,并根据所提出的分类方法对现有文献中的算法进行了系统的分类、讨论和比较。我们相信,通过图级和模型级的优化,可以促进GNN的执行,获得更高的效率,有利于不同平台上与图相关的任务。尽管近年来GNN加速方法取得了巨大的成功和飞跃,但在这一研究领域仍存在许多有待解决的问题。在此基础上,提出了未来研究的一些前景。
动态图的加速: 大多数加速方法采用静态图进行研究。然而,动态图在拓扑和特征空间方面比静态图更灵活,因此很难将这些方法直接应用于动态图。像KD-GCN[Yang等人,2020]和二值化DGCNN [Bahri等人,2021]这样的压缩方法利用一个特殊设计的模块将其扩展到动态图形,提供了一个动态图形加速的范例。
硬件友好算法: 通过利用硬件特性,硬件友好算法有利于模型(或算法)在通用平台上的执行。最近的文献[Liu et al., 2021c]的目标是弥补图采样算法和硬件特性之间的差距,利用位置感知优化来产生显著的图采样速度。然而,这提出了一个问题,在设计GNN加速的硬件友好算法时,应该仔细考虑哪些特征。
算法和硬件协同设计: 不同于GNN的特定领域硬件加速器,如HyGCN [Yan等人,2020b]直接为GNN定制数据路径,算法和硬件协同设计探索了算法和硬件感知的设计空间。具体来说,在GNN加速的这种前景下,总体上可以通过算法和硬件的同时设计来实现优化的协同效应。然而,据我们所知,目前在这方面的工作还很少。
