大语言模型(LLM)已彻底改变了自然语言处理领域,并催生了多种应用。基于大规模互联网数据的预训练奠定了这些模型的基础,然而,研究社区如今正越来越多地将关注点转向后训练(post-training)技术,以推动进一步的突破。尽管预训练提供了广泛的语言基础,后训练方法能够使LLM细化其知识,提升推理能力,提高事实准确性,并更有效地对齐用户意图与伦理规范。微调(fine-tuning)、强化学习(reinforcement learning)以及测试时扩展(test-time scaling)等策略,已成为优化LLM性能、增强其鲁棒性并提升其在各种现实任务中的适应性的关键手段。 本综述系统性探讨了后训练方法,分析其在超越预训练阶段细化LLM的作用,并探讨灾难性遗忘(catastrophic forgetting)、**奖励投机(reward hacking)以及推理时权衡(inference-time trade-offs)**等核心挑战。此外,我们还重点介绍了模型对齐(model alignment)、可扩展适配(scalable adaptation)和推理时优化(inference-time reasoning)等新兴方向,并展望未来研究趋势。为便于跟踪这一快速发展的领域,我们提供了一个公开的资源库,以持续更新最新进展:https://github.com/mbzuai-oryx/Awesome-LLM-Post-training。 索引词—推理模型、大语言模型、强化学习、奖励建模、测试时扩展
1 引言
当代大语言模型(LLM)在广泛的任务中展现出卓越能力,不仅涵盖文本生成 [1, 2, 3] 和问答系统 [4, 5, 6, 7],还包括复杂的多步推理 [8, 9, 10, 11]。LLM 赋能于自然语言理解 [12, 13, 14, 15, 16, 17]、内容生成 [18, 19, 20, 21, 22, 23, 24, 25]、自动推理 [26, 27, 28, 29] 以及多模态交互 [30, 31, 32, 33] 等领域。通过大规模自监督训练语料库,LLM 在许多情况下能够近似人类认知 [34, 35, 36, 37, 38],展现出卓越的适应性。然而,尽管取得了显著进展,LLM 仍存在诸多关键缺陷。例如,它们可能生成误导性或事实不准确的内容(通常称为“幻觉”),并可能在长文本生成过程中难以保持逻辑一致性 [41, 42, 43, 44, 45, 46]。 此外,LLM 的推理能力仍然存在争议。尽管这些模型可以生成表面上逻辑连贯的响应,但其推理过程本质上与人类的逻辑推理不同 [47, 34, 48, 49]。这种区别至关重要,因为它解释了为什么 LLM 能够生成令人信服的输出,但在相对简单的逻辑任务上仍然容易出错。与基于符号推理(symbolic reasoning)明确操控规则和事实的方式不同,LLM 采用隐式、概率性的推理方式 [50, 42, 51]。在本研究的范围内,LLM 的“推理”指的是其基于数据中的统计模式生成逻辑连贯响应的能力,而非基于显式逻辑推理或符号操作的推理。此外,仅通过**下一个标记预测(next-token prediction)**训练的模型,可能无法与用户期望或伦理标准保持一致,特别是在存在模糊性或恶意输入的情况下 [4, 52]。这些问题凸显了需要专门的策略来提升 LLM 的可靠性、公正性及上下文敏感性。 LLM 训练通常可分为两个阶段:
- 预训练(pre-training)——基于大规模语料进行下一个标记预测任务,以建立广泛的语言基础;
- 后训练(post-training)——包括多个轮次的微调(fine-tuning)和对齐(alignment),以优化模型行为,使其输出更符合人类意图,减少偏差和不准确性 [53]。
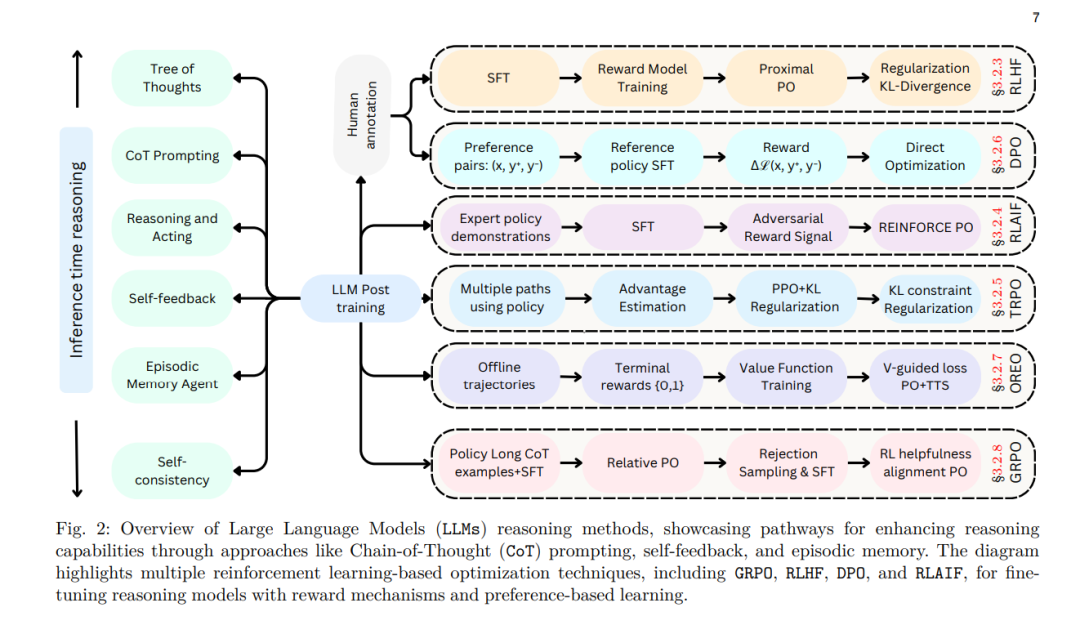
针对特定领域任务的 LLM 适配通常涉及微调(fine-tuning)[54, 55, 56],该方法能够实现任务特定的学习,但存在过拟合(overfitting)和高计算成本(high computational cost)的风险。为了解决这些挑战,强化学习(Reinforcement Learning, RL)[57, 58, 59] 通过动态反馈优化序列决策,提高 LLM 的适应性。此外,低秩适配(Low-Rank Adaptation, LoRA)[60]、适配器(adapters)以及检索增强生成(Retrieval-Augmented Generation, RAG)[61, 62, 63] 等扩展技术能够提高计算效率和事实准确性。这些策略结合分布式训练框架,有助于大规模部署 LLM 并提高其在不同应用场景中的可用性(图 1)。通过这些后训练技术,LLM 能够更好地对齐人类意图和伦理要求,从而增强其在现实世界中的应用价值。
1.1 后训练关键阶段
**(a) LLM 微调(Fine-Tuning)
微调是指在特定任务或领域上对预训练 LLM 进行参数更新,以提升其在特定任务上的表现 [64, 65, 66, 54, 55, 67, 56]。尽管 LLM 在大规模预训练后表现出较强的泛化能力,但微调能够进一步提升其在情感分析[68, 69]、问答及特定领域应用(如医学诊断 [70, 71, 72])等任务中的表现。然而,微调存在以下挑战:
- 过拟合风险——模型可能对训练数据过度拟合,导致泛化能力下降。
- 计算成本高——完整的参数微调需要大量计算资源。
- 数据偏差敏感——数据分布偏差可能影响微调效果 [56, 31, 16]。
为此,参数高效微调技术(如 LoRA [60] 和适配器)可以在不更新所有参数的情况下,学习特定任务的适配性,显著减少计算开销。然而,随着模型专业化,其在领域外任务(out-of-domain tasks)上的泛化能力可能下降,形成特定性与通用性之间的权衡。
**(b) 强化学习在 LLM 中的应用(Reinforcement Learning in LLMs)
传统强化学习(RL)涉及智能体与环境的交互,通过执行**离散动作(discrete actions)**优化累计奖励 [73],常用于机器人控制、棋类游戏及控制系统 [74, 75]。然而,在 LLM 领域,RL 任务与传统 RL 存在显著差异:
- 高维动作空间——LLM 需从庞大词汇表中选择标记,而非离散的动作集 [16, 59, 76, 57]。
- 稀疏、主观且延迟的反馈——LLM 评估依赖启发式评分和用户偏好,而非明确的奖励信号 [77, 78, 79, 58]。
- 多目标优化——LLM 需要平衡多个目标,如上下文一致性、伦理约束和生成质量,而传统 RL 通常优化单一目标。
为提升 RL 训练效果,研究者结合过程奖励(process-based rewards)(如思维链推理 Chain-of-Thought Reasoning)和结果评价(outcome-based evaluations)(如生成质量评估)[8, 80, 81],以优化 LLM 学习过程。因此,LLM 的 RL 训练需要专门的优化技术,以处理高维输出、非平稳目标和复杂奖励结构,确保模型生成符合用户期望的上下文相关响应。
**(c) LLM 扩展与推理优化(Scaling in LLMs)
扩展(Scaling)在提升 LLM 性能和效率方面起着关键作用。尽管扩展能够提高任务泛化能力,但同时带来了巨大的计算挑战 [82, 83]。为平衡性能与计算效率,在推理阶段采用以下优化策略:
- 思维链推理(CoT)[8] 和思维树(ToT)[84] 通过分解复杂问题,提升多步推理能力。
- 搜索增强方法 [85, 86, 87, 88] 允许模型在推理过程中探索多种可能答案,提高事实准确性。
- RAG [61, 62, 89] 结合外部知识检索,减少静态训练数据的局限性 [62, 24, 90]。
- 分布式训练框架 利用并行计算降低大规模 LLM 训练的计算压力。
- 测试时扩展(test-time scaling)[83, 91] 通过动态调整推理参数,优化计算效率与输出质量。
尽管扩展策略带来了性能提升,但仍面临收益递减(diminishing returns)、推理时间增长及环境影响等挑战 [82],特别是在测试时执行搜索算法时,计算成本显著增加。因此,优化 LLM 的可访问性和可行性仍是部署高效 LLM 的关键任务。
1.2 本文贡献
本综述的主要贡献如下: ✔ 系统性回顾LLM 的后训练方法,包括微调、强化学习和扩展,揭示其相互作用和优化策略。 ✔ 构建后训练技术分类体系,分析关键挑战,并探讨 LLM 在现实世界应用中的优化方向。 ✔ 提供实用指南,涵盖关键基准、数据集和评估指标,以促进 LLM 在实际应用中的优化和部署。