论文浅尝 | 当知识图谱遇上零样本学习——零样本学习综述
随着监督学习在机器学习领域取得的巨大发展,如何减少人工在样本方面的处理工作,以及如何使模型快速适应层出不穷的新样本,成为亟待解决的问题。零样本学习(Zero-Shot Learning, ZSL)的提出,则有效地解决了此类问题,它利用样本之间潜在的语义关系,使得模型可以处理一些之前从未处理过的样本,对于探索实现真正的人工智能具有非常重要的意义。而知识图谱作为包含丰富语义知识的一种载体,在零样本学习建立语义关系方面成为一种天然的帮助。
因此,本次论文浅尝将针对零样本学习现有的研究方法以及其中的知识图谱工作做一些分享。考虑到目前 ZSL 在 CV 领域应用比较广泛,此次的论文分享也以“图片分类”等与图片相关的任务为主。
1 Introduction
1.1 Zero-Shot Learning(ZSL)定义
(1)相关符号
训练数据 X_tr 及其类别标签 Y_tr,即模型可用来训练的数据(马,老虎,熊猫);
测试数据 X_te 及其类别标签 Y_te,即模型待分类的数据(斑马);
类别描述(class/labeldescription) A,对应类别集合(Y=Y_tr+Y_te)中的每一个类别(class) y_i ∈ Y ,可表示为一个语义向量 a_i∈A。
(2)ZSL定义:
对于测试集中的样本,模型先使用训练数据 X_tr 及其类别标签 Y_tr 进行训练,再通过学习训练类别标签(training classes)和测试类别标签(testingclasses)之间的语义信息,实现对测试数据的分类,进而实现知识的迁移。
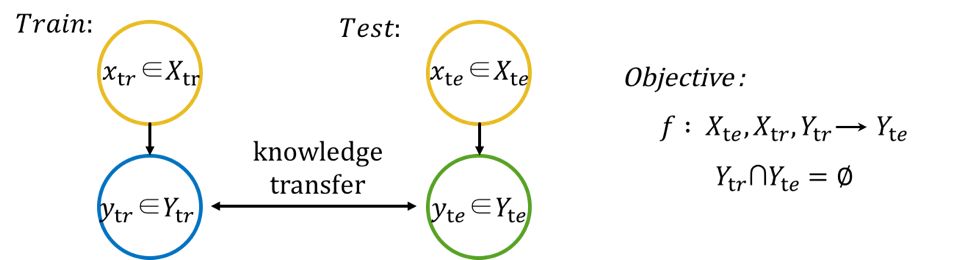
ZSL强调 Y_tr 和 Y_te 之间没有重叠,即在训练期间不会出现测试集的样本数据。其中,将在训练期间出现的类别称为 seen class,只在测试期间出现的类别称为 unseen class。
1.2 相关数据集
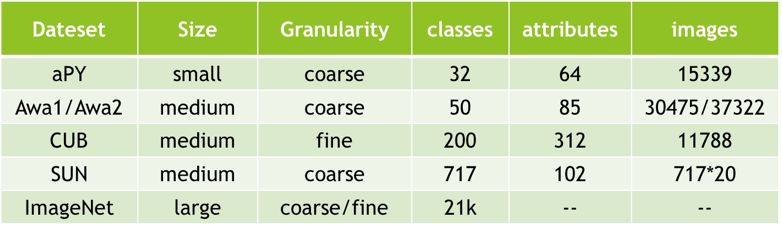
如下图所示列举了目前ZSL使用较多的各个数据集,分别列举了数据集的规模、粒度、包含class的数量、图片的数量,以及数据集图片相关属性描述的attribute数量。其中Awa是与动物相关的数据集,Awa1仅包含属性,但没有original image的数据集,Awa2表示根据Awa1提供的class从互联网上收集图片组织到的数据集;CUB数据集与鸟类相关;而ImageNet是由WordNet组织的图片数据集,规模较大,且图片类别,即包含细粒度的划分,也包含粗粒度的划分,但它不包含图片的属性信息。
2 Current Work
总结现有的工作,ZSL 工作的框架主要分为三个部分:
(1) 样本数据特征空间 X 的学习,如利用深度网络提取图片特征;
(2) 关于语义空间 A 中 class 的描述,即构建 seen class 和 unseen class 之间潜在的语义关系;
(3) 特征空间 X 和语义空间 A 之间的映射。
其中,图片分类任务方面,特征空间的表示学习现阶段已经趋于成熟,而语义空间A的构建则是目前比较关注的点。A的表示主要有以下几种方式:
(1) attribute description:数据集中的每个class都附加了一些与可描述图片的 attribute,如黑色/白色/水生/陆生;
(2) embedding 表示:每个 class 可作为词,获取语义向量;
(3) Knowledge Graph/Knowledge Base:每个 class 可对应KG/KB中的一个实体。
下面的部分,以语义空间A的构建方式为划分,分享若干论文。
2.1 ZSL相关论文
1、基于attribute description构建语义空间 A
论文题目:Learning To Detect Unseen Object Classes by Between-Class Attribute Transfer

论文链接:http://pub.ist.ac.at/~chl/papers/lampert-cvpr2009.pdf
基于 attribute description 的方法,其数据集中的每张图片都标注了若干attribute用以描述图片信息。一些标注了attribute的示例图片如下图所示。

这篇论文通过上述每张图片预定义的特征,构建了样本数据的特征表示空间 X;同时,通过若干 classes 集合或图片集合学习可用于表示数据集中所有 class 的 attribute description,完成语义空间 A 的构建;最后,论文提出了使用两种方式建立X和A之间的映射。两种方式为:Direct AttributePrediction(DAP)和Indirect Attribute Prediction(IAP),如下图所示。
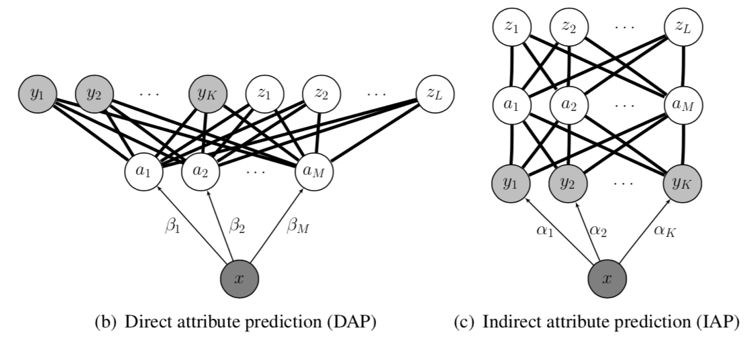
DAP:训练时,由已知标签的训练集,学习有关 attribute 参数 β;预测时,为每一个测试样本预测其 attribute 参数,进而根据 attribute 建立的 seen class(y) 和 unseen class(z) 之间的关系,推导得出测试样本的 label。
IAP:训练时,按多分类的方式学习参数 α;预测时,根据 attribute 建立的seen class(y) 和 unseen class(z) 之间的关系,推导得到 unseen class 的分布。
DAP在预测时仅依据属性层,而IAP将训练样本的类标也作为一个中间层,一定程度上能限定测试样本生成新类标的范围,使得学习到的连接控制在对于Y来说,有意义的范围内,因此可以增强系统的鲁棒性。但实际上,在作者后面的实验中,DAP的效果要比IAP的效果好很多。依据AwA1数据集,并收集class set相应图片的实验中,DAP的效果为40.5%,而IAP只有27.8%。
这是比较早期的一篇文章,虽然效果没有传统的深度学习方法好,但确实在一定程度上表达了“知识迁移”的思想,不仅利用图片训练相应的特征,更是加入了属性这类的高维特征描述,实现了从“低维图片特征分类器”到“高维语义特征(属性)分类器”的转变。
Attribute description相关论文列表:
<CVPR-2009>Describing Objects by their Attributes
<TPAMI-2014>Attribute-based Classification for Zero-Shot Visual Object Categorization
<TPAMI-2017>Zero-Shot Learning-A Comprehensive Evaluation of the Good, the Bad and the Ugly
<CVPR-2017>Semantic Autoencoder for Zero-Shot Learning
<CVPR-2016>Recovering the Missing Link: Predicting Class-Attribute Associations for Unsupervised Zero-Shot Learning
2、基于embedding表示构建语义空间A
论文题目:DeViSE: A Deep Visual-Semantic Embedding Model

论文链接:http://papers.nips.cc/paper/5204-devise-a-deep-visual-semantic-embedding-model.pdf
本文提出的 DeViSE 模型,数据集每个 class/label 可作为一个词在语义空间进行 embedding 表示,如使用预训练 skip-gram 模型得到有关 class 的 language feature vector,同时利用预训练的 CNN-based 模型提取图片的 visualfeature vector,将两个向量映射到同一维度的空间,进行相似度的计算。测试时,即可根据语义之间的相似性进行图片的分类。模型结构如下图所示。
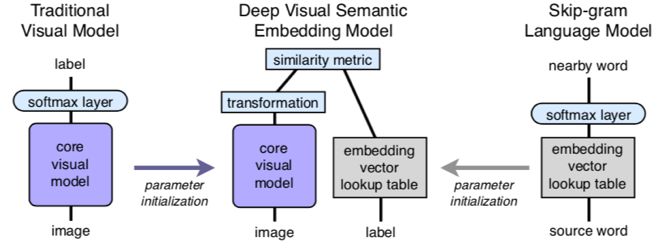
考虑到训练时负样本发挥的作用,模型的损失函数选择hingeloss。其中,通过dot-product计算相似度。
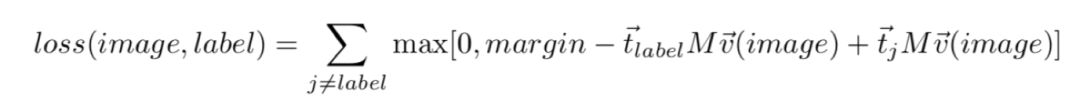
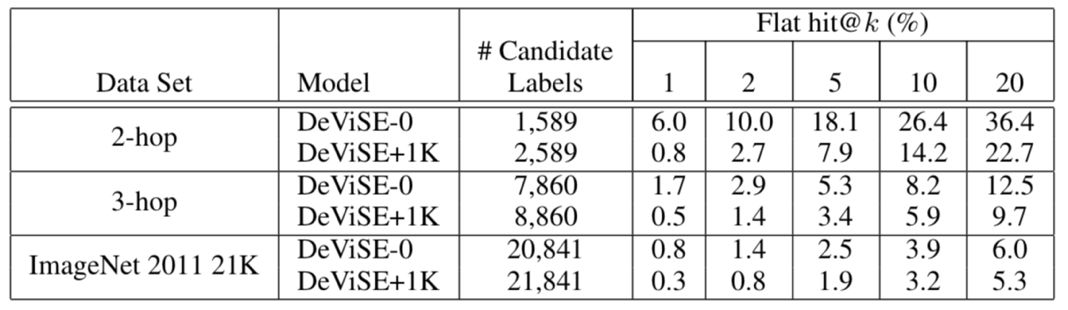
在 ZSL 场景下,最终实验使用 ImageNet 1k class(seen class) 训练模型,ImageNet 2-hops/3-hops/all (unseen class) 三个测试集测试模型的效果,同时也考虑了generalized ZSL,即在真实场景下测试时也会处理训练集中出现过的 class(如使用 1k+2-hops 的数据作为测试)。实验结果如下图所示。
Embedding表示相关论文列表:
<ICCV-2015>Predicting Deep Zero-Shot Convolutional Neural Networks using TextualDescriptions
<CVPR-2016>Learning Deep Representations of Fine-grained Visual Descriptions
<CVPR-2015>Evaluation of Output Embeddings for Fine-grained Image Classification
<CVPR-2016>Latent Embeddings for Zero-shot Classification
3、基于KG/KB构建语义空间A
(1)论文1:Zero-shot Recognition via Semantic Embeddings and Knowledge Graphs

论文链接:https://arxiv.org/pdf/1803.08035.pdf
本文基于 Graph Convolutional Network(GCN,一种处理 Graph-structured 数据的神经网络)引入 Knowledge Graph 的 hierarchy 结构进行计算。模型分为两个独立的部分,首先使用 CNN-based 方法(如 resnet, inception 等)为输入的图片抽取特征向量,即 CNN 部分(图所示上方的 CNN 网络);其次,GCN 部分(图所示下方的 GCN 网络)将数据集中的每个 class 作为 Graph 中的一个节点,并对其作 embedding 表示输入 GCN 网络(即输入为由 N 个 k 维节点组成的 N*k 特征矩阵),通过神经网络每一层之间信息的传递和计算,为每个节点(class)输出一组权重向量(D维),即输出是一个 N*D 的特征矩阵。
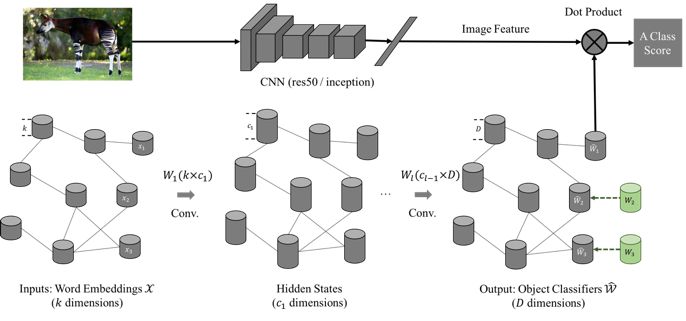
模型训练时,Graph 中 seen class 节点有来自 CNN 部分的图片特征向量作为监督信号(图所示绿色节点)训练 GCN 模型的参数;而测试时,Graph 中的 unseen class 节点输出对应的权重向量,同时,与 CNN 部分对应图片输出的特征向量,最终得到分类的结果。
这里提及的 Graph 为可表示 ImageNet class 之间结构的 WordNet 知识库,实验选取了其中一部分与 ImageNet 相关的子集。
(2)论文2:Rethinking Knowledge Graph Propagation for Zero-Shot Learning

论文链接:https://arxiv.org/pdf/1805.11724v1.pdf
本文在论文 1 的基础上进行了改进,包括以下几个方面:
(1)更少的 GCN 层数,论文 1 中使用了 6 层神经网络进行训练,考虑到模型参数的优化问题,本文只使用了 2 层神经网络进行计算,即 GPM;
(2)减少层数的同时,一些较远节点将不被考虑在内,为了解决这个问题,作者将一些节点的祖先节点/子孙节点直接与该节点相连,生成了更密集的图,即DGPM;同时,这些直接相连的边按照距离的远近,加入attention机制进行了加权计算,即 ADGPM;
(3)作者还提出了在CNN部分根据graph信息进行fine tune的计算方式,使得提取图片特征的卷积网络可根据一些新出现的class进行更新。
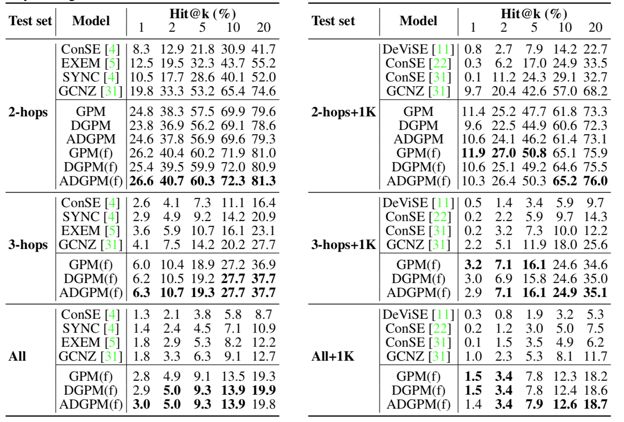
作者使用了与论文1中相同的数据集,即ImageNet 2012 1kclass(seen class)作为训练,ImageNet 2-hops/3-hops/all(unseen class)三个测试集作为测试。对比结果如下,其中GCNZ代表论文1中的方法,GPM、DGPM、ADGPM分别表示上述优化的(1)(2)方面,GPM(f)、DGPM(f)、ADGPM(f)表示finetune的结果,同样地,“2-hops+1k”表示generalizedZSL。
KG/KB相关论文列表:
<IJCAI-2018>Fine-grained Image Classification by Visual-Semantic Embedding
<CVPR-2018>Multi-Label Zero-Shot Learning with Structured Knowledge Graphs
<NIPS-2009>Zero-Shot Learning with Semantic Output Codes
少样本学习(Few-Shot Learning, FSL)
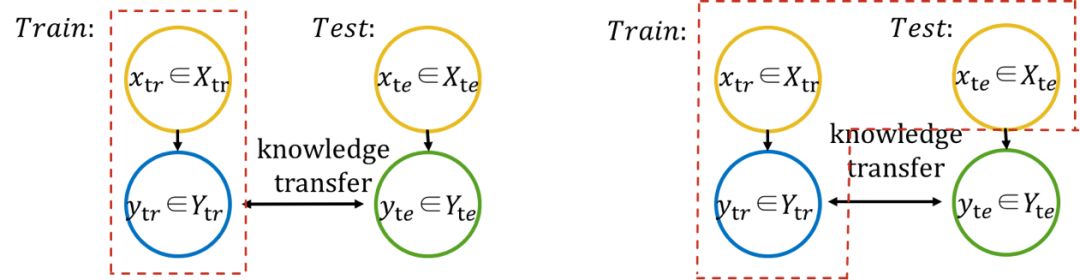
前面 2.2 部分提到的论文,其迁移知识的方式主要是通过在语义空间构建 seen class 与 unseen class 之间的关系(下图左),而 Transductive Setting 则提出可通过 seen class 和 unseen class 的少量样本训练得到class之间的关联(下图右),即少样本学习(Few-ShotLearning, FSL)。
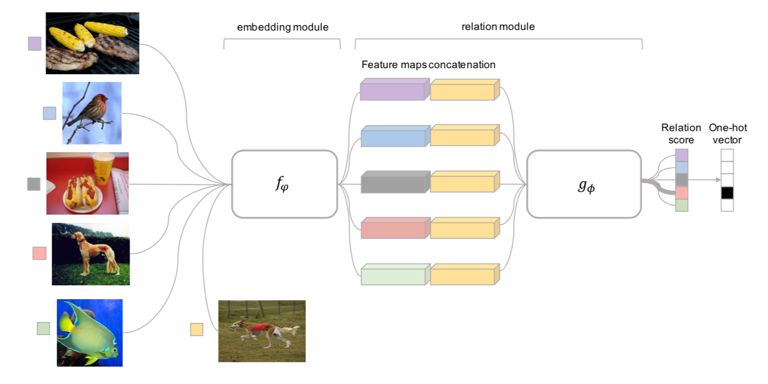
论文题目:Learning to Compare: RelationNetwork for Few-Shot Learning

论文链接:https://arxiv.org/pdf/1711.06025.pdf
本文从每个 class 中采样少量样本,作为参考样本(如下图左侧 5 张图片,分别代表 5 个 classes),以建立 class 之间的关系。本文所构建的 class relation 主要为相似关系,模型通过 embedding module 提取图片的特征向量,再分别将测试图片(下图所示袋鼠图片)的特征向量与参考样本的特征向量进行拼接输入 relation module,通过神经网络计算测试图片和参考样本图片之间的相似性,最终判断测试图片属于参考图片代表 class 的哪一类。
FSL相关论文列表:
<ICLR-2018>Few-Shot Learning with Graph Neural Networks
<BigData-2017>One-shot Learning for Fine-grained Relation Extraction via ConvolutionalSiamese Neural Network
<NIPS-2016>Matching Networks for One Shot Learning
<NIPS-2017>Prototypical Networks for Few-hot Learning
<ICLR-2017>Optimization as a model for few-shot learning
<ICML-2016>Meta-learningwith Memory-augmented Neural Networks
论文笔记整理:耿玉霞,浙江大学直博生,研究方向:知识图谱、零样本学习。
OpenKG.CN
中文开放知识图谱(简称OpenKG.CN)旨在促进中文知识图谱数据的开放与互联,促进知识图谱和语义技术的普及和广泛应用。

点击阅读原文,进入 OpenKG 博客。



