

大型语言模型(LLMs)在静态、预先收集的通用数据集上的训练取得的最近成功,已经引发了众多研究方向和应用。其中一个方向解决了将预训练的LLMs整合到动态数据分布、任务结构和用户偏好中的非平凡挑战。这个问题的主要挑战在于平衡模型适应性和知识保存。为特定需求量身定制的预训练LLMs经常在之前的知识领域经历显著的性能退化——这一现象被称为“灾难性遗忘”。虽然在持续学习(CL)社区进行了广泛研究,但在LLMs领域呈现出新的表现形式。在这篇综述中,我们提供了一个关于大型语言模型在持续学习背景下当前研究进展的全面概览和详细讨论。除了介绍初步知识外,这篇综述被分为四个主要部分:我们首先描述了持续学习LLMs的概览,包括两个连续性方向:垂直连续性(或垂直持续学习),即从一般到特定能力的持续适应;和水平连续性(或水平持续学习),即跨时间和领域的持续适应(第3节)。在垂直连续性之后,我们总结了在现代CL背景下学习LLMs的三个阶段:持续预训练(CPT)、领域适应性预训练(DAP)和持续微调(CFT)(第4节)。然后我们提供了LLMs的持续学习评估协议的概览,以及当前可用的数据来源(第5节)。最后,我们讨论了有关LLMs持续学习的引人深思的问题(第6节)。这篇综述揭示了持续预训练、适应和微调大型语言模型这一相对未受到足够研究的领域,表明需要社区更多的关注。需要立即关注的关键领域包括开发实用且易于访问的评估基准,以及专门设计的方法论,以对抗遗忘和在不断演变的LLM学习范式中启用知识转移。在这项综述中检查的完整论文列表可在https://github.com/Wang-ML-Lab/llm-continual-learning-survey找到。
https://www.zhuanzhi.ai/paper/dd092f590f564445a95defcb33397181
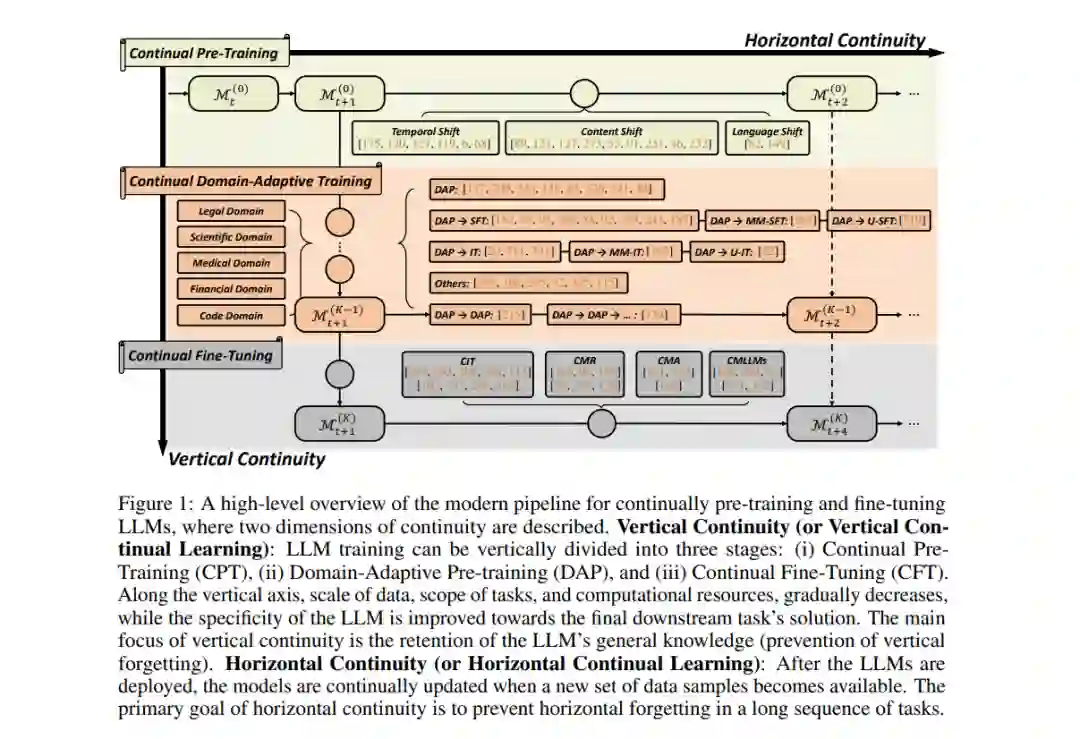
- 垂直连续性(或垂直持续学习),指的是LLMs从大规模通用领域到小规模特定领域的持续适应,涉及学习目标和执行实体的转变。例如,医疗机构可能开发专门为医疗领域定制的LLMs,同时保留其一般推理和问答能力,以服务用户。
- 水平连续性(或水平持续学习),指的是跨时间和领域的持续适应,通常涉及多个训练阶段和对灾难性遗忘的增加脆弱性。例如,社交媒体平台不断更新LLMs以反映最近的趋势,确保精确地定位下游服务如广告和推荐,同时为现有用户提供无缝的用户体验。
在图1中,继垂直连续性之后,我们勾画了现代CL中LLM学习的三个关键阶段:持续预训练(CPT)、领域适应性预训练(DAP)和持续微调(CFT)(第4节)。在CPT中,现有研究主要调查三种类型的分布式转变:时间、内容层次和语言层次。每种都呈现出独特的焦点和挑战。在DAP中,虽然它主要被视为为下游任务准备LLMs的过程,但频繁地使用CL评估和技术。然而,这些技术的多样性明显不足,考虑到传统CL社区的成熟度。在CFT中,我们关注的是学习LLMs的新兴领域,涵盖持续指令调整(CIT)、持续模型精炼(CMR)、持续模型对齐(CMA)和持续多模态LLMs(CMLLMs)等主题。接下来,我们呈现了一系列公开可用的评估协议和基准(第5节)。我们总结我们的综述,讨论了LLMs持续学习的最新出现的特性,传统增量学习类型和LLMs持续学习中的记忆约束的角色变化,以及这个主题的潜在研究方向(第6节)。总结而言,本文提供了一份详尽的现有持续学习研究LLMs的综述,显著区别于相关主题的现有文献。我们的综述突出了持续开发LLMs的研究领域,特别是在持续预训练(CPT)和领域适应性预训练(DAP)领域的研究。我们强调需要社区更多的关注,迫切需要包括开发实用、易于访问且广为认可的评估基准。此外,需要定制方法来解决在新兴的大型语言模型学习范式中的遗忘问题。我们希望这篇综述能提供一个系统而新颖的持续学习视角,在迅速变化的LLMs领域中,帮助持续学习社区为开发更有效、可靠和可持续的LLMs做出贡献。
组织结构
本文的其余部分安排如下。我们首先在第2节介绍大型语言模型和持续学习的背景和初步知识。然后我们在第3节展示了大型语言模型的现代持续学习概览。从垂直角度来看,它可以大致分为三个阶段的LLMs持续训练,我们将在第4节逐一介绍每个阶段。在4.3节中,将介绍持续微调LLMs的独特方面,包括持续指令调整(4.3.3节)、持续模型精炼(4.3.4节)、持续模型对齐(4.3.5节)和持续多模态大型语言模型(4.3.6节)。在第5节中,我们提供了公开可用的LLMs持续学习评估协议和基准的全面介绍。最后,在第6节中,我们讨论了在大型语言模型时代持续学习的角色,包括大规模持续LLMs的新兴能力(6.1节)、三种类型的持续学习(6.2节)、LLMs持续学习中的记忆角色(6.3节)以及未来的研究方向(6.4节)。 持续学习与大型语言模型相遇:概览****大型语言模型(LLMs)在多个维度上都非常庞大,包括模型参数的大小、预训练数据集、计算资源、项目团队和开发周期。LLMs的巨大规模为开发团队带来了显著的挑战,特别是在快速变化的环境中保持更新。举例来说,2023年,用户发布的新推文的平均每日流量超过5亿,即使是在这么大量数据的“小”子集上进行训练也是不可承受的。在考虑到它们对下游应用的连锁影响时,有效且可靠地适应LLMs变得更为关键。下游用户通常缺乏收集和存储大规模数据、维护大规模硬件系统以及自行训练LLMs的专业知识。《可回收调整》是首个明确概述现代LLM生产流水线供应商-消费者结构的先导研究。在供应商侧,模型在一系列大规模未标记数据集上持续进行预训练。每次预训练模型发布后,消费者需要利用更新、更强大的上游模型以获得更好的下游性能。为了提高下游消费者微调的效率,他们最初对持续预训练的LLMs进行了几项关键观察,聚焦于模式连接性和功能相似性。此外,他们提出在上游预训练LLM进行重大更新后,复用过时的微调组件。基于《可回收调整》引入的概念框架,我们在本综述中提出了一个包含各种研究的现代生产流水线的全面框架,涉及持续LLM预训练、适应和部署,如图1所示。我们的框架与现有研究的不同之处在于融入了两个连续性方向:垂直连续性和水平连续性。
结论
在这项工作中,我们提供了一份关于持续LLMs的综述,从持续学习的角度总结了它们在训练和部署方面的最新进展。我们根据它们在我们提出的现代分层持续学习LLMs的更广框架内的位置,对问题和任务进行了分类。虽然这一领域在社区中的兴趣广泛且日益增长,但我们也注意到几个缺失的基石,包括算法多样性以及对大模型行为(如知识遗忘、转移和获取)的基本理解。通过全面而详细的方法,我们希望这篇综述能激励更多从业者探索持续学习技术,最终有助于构建健壮和自我进化的人工智能系统。
