近年来,基础语言模型(LMs)在自然语言处理(NLP)和计算机视觉(CV)领域取得了显著成就。与传统神经网络模型不同,基础语言模型通过在大量无监督数据集上进行预训练,获得了丰富的常识知识,并且具有强大的迁移学习能力。然而,由于灾难性遗忘,基础语言模型仍然无法模拟人类的持续学习能力。因此,各种基于持续学习(CL)的方法被开发出来,以改进语言模型,使其能够在适应新任务的同时不遗忘以前的知识。然而,现有方法的系统分类和性能比较仍然缺乏,这正是本综述旨在填补的空白。我们深入综述、总结并分类了现有文献中应用于基础语言模型的持续学习方法,如预训练语言模型(PLMs)、大语言模型(LLMs)和视觉-语言模型(VLMs)。我们将这些研究分为离线持续学习和在线持续学习,其中包括传统方法、基于参数高效的方法、基于提示调优的方法和持续预训练方法。离线持续学习包括领域增量学习、任务增量学习和类别增量学习,而在线持续学习则细分为硬任务边界和模糊任务边界设置。此外,我们概述了持续学习研究中使用的典型数据集和指标,并详细分析了基于语言模型的持续学习所面临的挑战和未来工作。
** 1 引言**
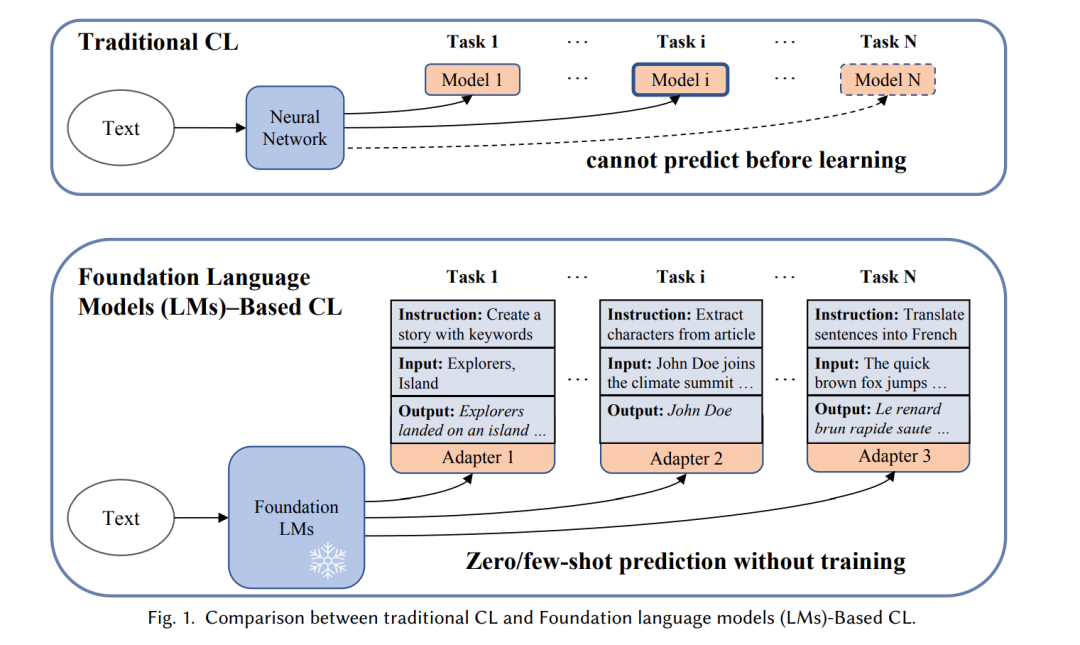
近年来,基础语言模型(LMs)在自然语言处理(NLP)[136, 226, 232]和计算机视觉(CV)[188]领域设立了新的基准。基础语言模型主要包括三大类:预训练语言模型(PLMs)[136]、大语言模型(LLMs)[226]和视觉-语言模型(VLMs)[42]。PLMs如BERT [88]、RoBERTa [120]和BART [102]专注于文本任务,通过利用掩码语言建模等任务进行预训练,对于理解和生成语言至关重要。LLMs如GPT-4 [1]和LLaMA [173]通过扩大模型架构和训练数据的规模,扩展了PLMs的能力,从而增强了它们在更广泛任务中的普适性和适应性。VLMs如VisualBERT [106]、CLIP [154]、LLaVA [113]和DALL-E [156]集成了文本和图像模态,使视觉和文本信息之间能够进行复杂交互。这些模型的基本范式是通过在广泛的、通常是无标签的数据集上进行预训练来捕获丰富的语义信息,然后针对具体任务或领域进行微调。这种方法不仅提升了各类应用的性能,还显著增强了模型的灵活性和任务适应性 。 然而,这些基础模型在具有一系列任务的动态环境中往往表现出局限性,主要原因是训练完成后参数固定。这些模型通常缺乏在不进行重新训练的情况下整合新数据或概念的能力。一个重要挑战是“灾难性遗忘”[92],即模型在学习新信息时会丧失先前获得的知识。这与人类的持续学习过程形成鲜明对比,人类学习过程本质上是连续且适应性的。尽管多任务学习(MTL)和迁移学习(TL)在某些应用中取得了成功,但它们在现实场景中有其局限性。MTL需要在开始时就提供所有任务及其数据,这在推出新服务时构成挑战,因为模型必须重新训练所有数据。此外,TL通常只涉及两个任务,即源任务和目标任务,这对于拥有多个目标任务的现实在线平台来说是不切实际的。为了解决这些挑战,模型需要处理和学习不断扩展和多样化的数据集。这需要允许模型在适应新语言现象和趋势的同时,不影响对历史数据的准确性和敏感性的机制。
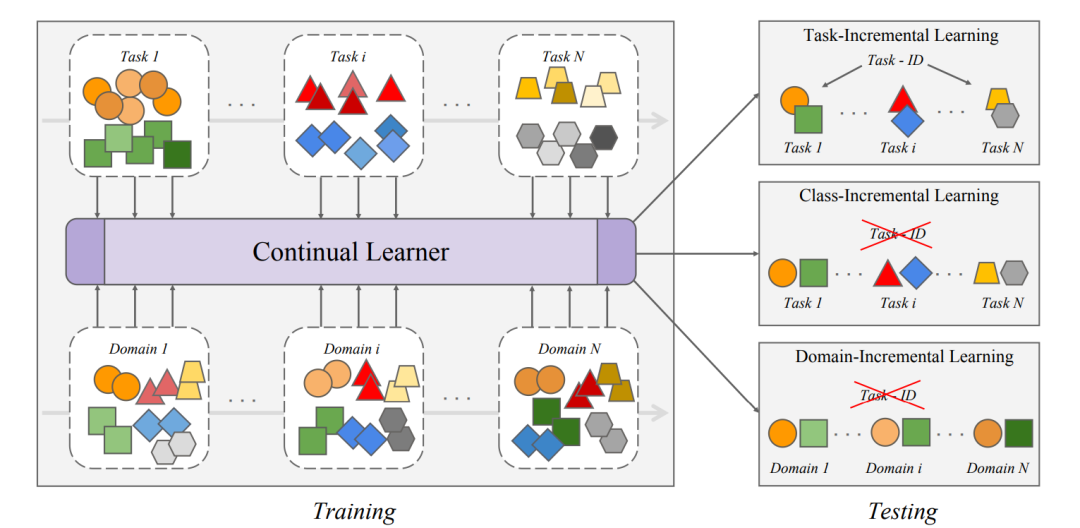
因此,持续学习(CL)[175, 186],也被称为终身学习[145]或增量学习[230],是人工智能中的一个关键领域,旨在开发能够持续更新自身并获取新知识的系统,而不遗忘先前学到的信息,类似于人类学习[34]。这一范式在基础语言模型(LMs)的背景下尤为重要,因为它们面临灾难性遗忘(CF)和跨任务知识转移(KT)等特定问题。灾难性遗忘是一个显著挑战,模型在学习新信息时倾向于丧失先前获得的知识。为了解决这一问题,语言模型必须在适应新的语言趋势的同时,保持对过去语言数据的稳固掌握。此外,跨任务知识转移对于增强持续学习过程至关重要。有效的知识转移不仅加速新任务的学习曲线(前向转移),还通过新知识的反馈提高模型在先前任务上的性能(反向转移)。
持续学习方法的最新进展大大提升了基础语言模型(LMs)的适应性和知识保留能力。这些进展对于解决CL中先前观察到的复杂挑战至关重要。研究人员制定了创新策略来减轻这些挑战,从而使LMs能够在各种任务中保持高性能,同时持续整合新知识[30, 99, 134]。在不同的下游任务中记录了显著的成功,例如基于方面的情感分析,其中持续学习使动态适应不断变化的方面和情感成为可能[84]。同样,在对话生成中,新技术通过持续交互帮助模型改进和扩展其对话能力[164]。在文本分类中,持续学习促进了新类别的整合和对文本分布变化的调整,而无需完全重新训练[158]。此外,在视觉问答领域,持续学习对于更新模型处理和响应新类型视觉内容和查询的能力至关重要[148, 220]。上述工作强调了持续学习对提升基础语言模型性能的潜力。
在持续学习领域,传统方法向整合基础语言模型的方法发生了显著的范式转变(见图1)。首先,基础语言模型由于在大规模数据集上的广泛预训练,展示了增强的泛化和迁移学习能力。模型具有快速适应下游任务的专门迁移能力,只需少量样本。因此,在促进新技能获取的同时,减轻零样本迁移和历史任务能力的退化至关重要。其次,由于基础语言模型中大量的参数,采用参数高效技术[59]如提示调优[119]和适配器[140],无需全面重新训练即可更新参数。第三,基础语言模型具备通过指令学习[39, 144]进行动态和上下文感知交互的能力。
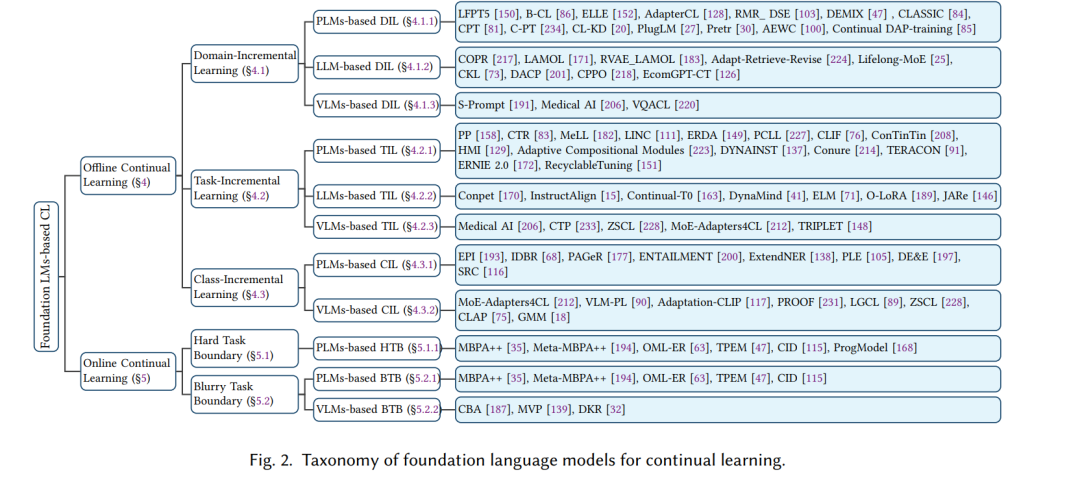
本综述系统地将这些策略和技术分类为两个核心领域:离线持续学习和在线持续学习(图2)。我们首先给出离线和在线CL的详细定义和场景,其中离线CL包括领域增量、任务增量和类别增量CL,而在线CL包括硬任务边界和模糊任务边界。这些学习策略进一步细分为基于预训练语言模型(PLMs)、大语言模型(LLMs)和视觉-语言模型(VLMs)的方法。然后,我们总结了与传统方法、持续预训练方法、参数高效调优方法和基于指令方法相关的论文。最后,我们从多个角度统计了主要数据集,并回顾了评估模型遗忘和知识转移的关键指标。
本综述论文的主要贡献如下:
- 我们全面回顾了现有的基于基础语言模型的持续学习方法文献,这些方法将基础语言模型与CL整合起来,在不重新训练模型的情况下学习新知识。这与传统CL大不相同,因为基础语言模型具有强大的迁移学习、零样本和指令跟随能力,并且参数庞大。
- 我们定义了不同的设置,并将这些研究分类为各种类型,以便更好地理解该领域的发展。除了传统方法如重放、正则化和参数隔离算法外,我们还总结了持续预训练方法、参数高效调优方法和基于指令调优的方法。
- 我们提供了现有持续学习数据集的特征,并展示了评估防止遗忘和知识转移性能的主要指标。
- 我们讨论了基于基础语言模型的持续学习面临的最具挑战性的问题,并指出了该领域未来有前景的研究方向。 本文结构如下:在第2节中,我们回顾了与持续学习相关的主要综述。然后,在第3节中,我们介绍了持续学习的基本设置和学习模式,包括CL的定义和场景。此外,我们在第4节中展示了与离线持续学习相关的研究,这些研究可以分为领域增量学习、任务增量学习和类别增量学习。在第5节中,我们重点介绍了在线持续学习,包括硬任务边界和模糊任务边界设置。第6和第7节提供了典型数据集和指标。最后,我们在第8节分析了挑战和进一步的工作,并在第9节给出结论。