
2022年,随着ChatGPT的发布,大规模语言模型受到了广泛关注。ChatGPT不仅在参数量和预训练语料库规模上远超前代模型,还通过大量高质量的人工标注数据进行微调,实现了革命性的性能突破。此类进展促使得企业和研究机构认识到,构建更智能、更强大的模型依赖于丰富且高质量的数据集。因此,数据集的建设与优化成为了人工智能领域的关键方向。本文对训练大规模语言模型所需的预训练数据和微调数据的现状进行了总结,涵盖了数据规模、搜集方式、数据类型及其特点、处理流程等,并对当前可用的开源数据集进行了梳理和介绍。


1 引言
在人工智能领域,语言模型的发展一直是推动技术进步的核心动力之一。语言模型的目标是通过模拟文本数据的生成概率,来实现对自然语言的理解和生成。最初的模型,如n-gram,依赖于统计分析来预测词语序列,但这些模型难以捕捉复杂的语本依赖性,因此在处理复杂任务时表现有限。随着深度学习技术的发展,特别是AlexNet在视觉识别领域的突破,神经网络被引入到自然语言处理中。循环神经网络(RNN)及其衍生的LSTM和GRU显著提高了模型对序列数据的建模能力,使其能够更好地建模语言中的时序特征和文本关系。然而,这些方法仍然依赖于传统的监督学习范式,训练数据规模普遍较小,大部分数据集的规模以MB为量级。 真正的革命来自于以Transformer为基础的预训练语言模型的推出。Transformer架构通过自注意力机制(Self-Attention)有效地捕捉长距离依赖关系,并且由于其高并行化特性,极大地提高了语言模型的训练效率。这使得以大规模无标记文本作为训练语料成为可能。GPT和BERT等模型以Transformer为基础,加速了语言模型的迭代性能,将语言模型的“深度”推向了一个新的高度。 预训练语言模型之所以强大,是因为它们能够在未经过人工标注的大规模集群中自动学习丰富的特征。这些模型在预训练阶段以无监督大数据集发现和生成规律,并将其广泛的预测能力扩展到众多任务的表征能力。然而,预训练模型的强大性能离不开高质量大数据的支持,微调阶段在特定任务完成精调工作。因此,随着各个领域的数据集进一步微调,模型模型的更好地适应特定应用需求。 2022年,随着ChatGPT的发布,大规模语言模型受到了广泛关注。ChatGPT不仅拥有远超之前模型的参数量,且使用大规模高质量的人类标注数据对模型进行微调。ChatGPT革命性的性能突破让企业和研究机构认识到,构建更智能、更强大的模型依赖于丰富且高质量的数据集。自此,数据集的建设和优化成为了人工智能领域未来发展的方向。在这个背景下,许多公司和组织参与到训练数据的构建和优化工作中,而许多大规模模型语言集(如Baichuan、Qwen、Chatglm等)已经相继开源,但其训练数据几乎完全保密。 模型训练所涉及的语料的广度和质量是其核心竞争力。当然,也有非常多的公司和组织把投入大量资源构建的数据集进行开源,为社区的发展做出贡献。比如Together AI的RedPajama数据集或Hugging Face的Common Crawl数据。这些数据集中不仅标了降噪和不相关内容,还进行了结构化和标准化处理,使其适用于训练所需高质量数据。 与此同时,尽管许多商业组织的预训练数据与训练语料已被开源,其他在语音和世界的被公开总量并不理想。此外,数据的提升和可视化。随着模型的不断增大。 未来的数据建设成为一种非常核心的关键要求。当前对前沿问题和数据资源的需求是快速且不断增长的挑战之一,而随着对隐私问题和标准化的处理未来更需要建设和高质量基础来推动数据。
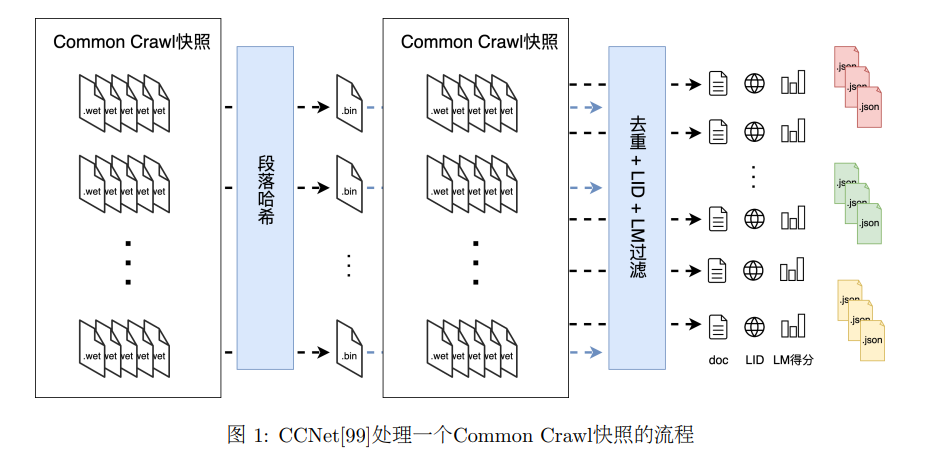
2 预训练数据
预训练任务通过让模型基于已有文本预测未知的Token,以此来学习语言结构和语义规则。自编码训练任务(如BERT)和自回归训练任务(如GPT)分别代表了两种主要的方法。在ChatGPT发布后,自回归训练任务逐渐成为训练大规模语言模型的主流方法。在预训练过程中,模型通过估计预测Token的原始概率,逐步掌握文本的语法和语义,从而积累大量语言知识,提升文本理解和生成能力。核心机制在于,模型能够通过预测文本的一部分,逐渐建立对整个文本结构的理解。此外,模型不仅能记住具体的单词和短语,还能学习更高层次的语言结构和语义关系。这种能力对于生成连贯且有意义的文本至关重要,使得模型在实际应用中能够提供更恰当的回答,上一文一致的回答。 预训练数据集对于训练模型理解和生成能力至关重要,是大规模语言模型开发的基础。预训练数据集通常来自人工标记,含有丰富的语言元素和复杂的结构。这种标注数据为模型提供了真实、自然的语言使用场景,使得模型学习到语言的本质特征和标准规则。预训练语料的背景特征就是规模庞大。大规模的数据集能够提供丰富的语言现象和多样的上下文场景,使模型在训练过程中接触到各种语言结构、词汇用法和语法规则。这种规模保证了模型可以捕捉到更广泛的语言模式和关系,从而在多种任务中表现出色。 除了规模庞大,其第二个重要特性就是来源广泛。预训练语料涵盖了从日常通信到专业学术的各种文本类型。这包括新闻报道、科学论文、文学作品等。这种多样化的文本来源确保了模型能够在不同的语境中灵活应用,既能理解口语的表达,也能处理学术术语和复杂的学术论述。模型通过在这些不同类型的文本中学习,可以获得更全面的语言知识和更强的适应能力。 通过预训练,模型能够积累大量的背景知识,这使得它在面对新的任务时,能够迅速适应并表现出色。预训练就像是让模型“打下上万本书,见多识广”,积累了丰富的知识储备,而微调过程则是让模型在特定领域进行专门训练,以便更好地完成特定任务。此外,预训练数据的多样性和复杂性也意味着在预训练过程中对数据的处理需要结合高度清洗和精细的标注。尽管如此,其中一些噪音可能是模型成长的营养剂,而非阻碍。例如别字、模棱两可的语言、复杂的语音环境中学习,模型能够得到更加健壮和灵活,能够更好地处理实际应用中遇到的各种问题。
3 微调数据
微调过程是训练语言模型不可或缺的一环,其目的是在于将模型从面向语言知识的通用训练转向面向具体任务的针对训练。在预训练阶段,模型通过预测被掩码的Token任务学习了大量的语言知识,使其具备理解和生成文本的能力。然而,这些知识是通用的,无法被直接应用于具体任务的实现。微调阶段旨在针对特定任务的语料库上进行训练,使模型能够学习到具体任务的需求和规则,从而将所学的语言知识和生成能力在应用任务中按特定任务。与预训练阶段相比,微调数据集通常是经过人工标记和精心设计的,记录了特定任务中的输入输出对应关系或其他更精细的上下文标记,从而更有针对性和强关联性。对不同读懂程度任务,微调数据包括任务参考文本、问题和问题的答案。通过这个训练,模型能够学习到解决特定任务的特征和模式,从而将训练阶段学到的通用知识应用到特定任务中。 微调数据集在分布式配置中包含:命令类问题、机器翻译、文本分类、自动问答等。这些任务需要语言模型学习更具体的问题解答能力,自动语言掌握模型的各种领域,知识储备和生成能力的需求。然而,随着ChatGPT的发布,人们发现,机器人语言模型在预训练阶段学到了更多的语言知识,获得了更强的语言能力,便能设计话和领域解决语用中所有高表达意图任务的各种应用任务。这些数据集使得模型在解决复杂多种问题中优化。 传统微调数据有可能有各种形式,如文本大小(机器翻译或其他文本类)等。但在传统微调数据集基础上强调对更高的基准结构变化而构建大规模系统。对于优化微调数据库。
结尾:
主要任务包括指令集跟随,日常对话、数学推理、代码生成、医疗问答等。构建微调数据集的主要问题分为两个方面,问题的收集和答案获取。其构建方式大致可以分为以下几种:人工撰写、真实用户对话、基于已有数据集的扩充、利用语言模型直接生成以及基于传统数据集的改写。下面介绍这几种基本的数据构建方式。 4 总结 本论文概述了大语言模型在预训练和微调阶段的数据构建要点。在预训练数据方面,英文数据在 数量和质量上优于中文数据,成为训练英文大语言模型的有力资源,而中文数据因网页资源有限、学 术数据匮乏、社交媒体平台闭源等因素受限。中文领域开源数据集的缺乏,也阻碍了中文大语言模型 的发展,尽管模型可以通过英文数据学习多语言能力,但中文特有的知识和文本风格仍难以完全涵 盖。此外,数据隐私与开放性之间的平衡成为关注点,语料枯竭也带来新的挑战,促使研究者探索合 成数据等新来源。 在微调数据方面,构建方法多样,包括人工撰写、真实用户数据扩充等。多样性、质量和安全性 是微调数据的重要目标,实际应用中常融合多种数据来源以取得最佳效果,并在不同领域数据配比上 进行优化。总体而言,预训练与微调数据的高质量构建对于提升大语言模型的性能至关重要。特别在 中文领域,各方需协力推动数据来源的拓展与技术改进,使中文大语言模型在各类应用中更具竞争 力。

