
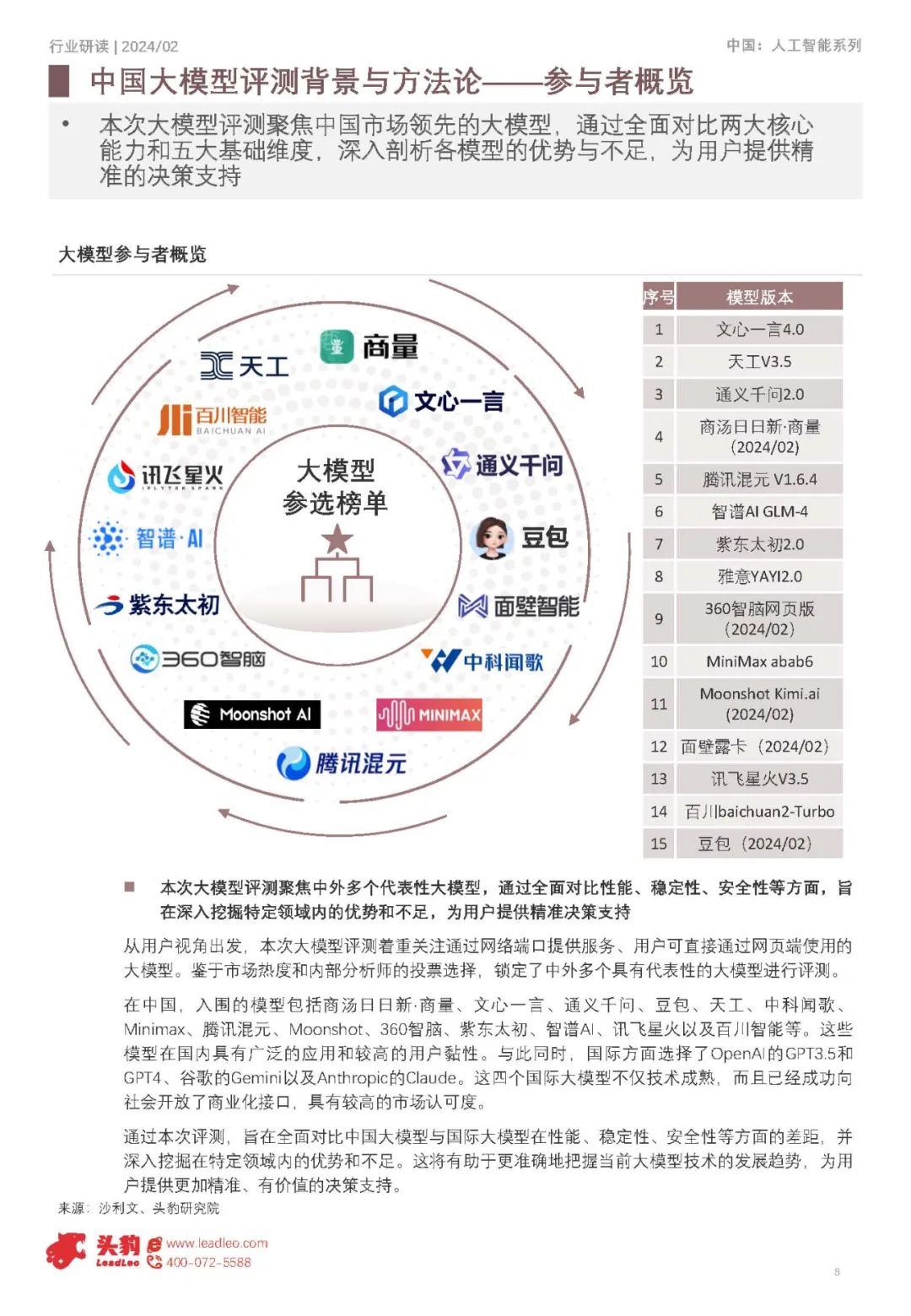
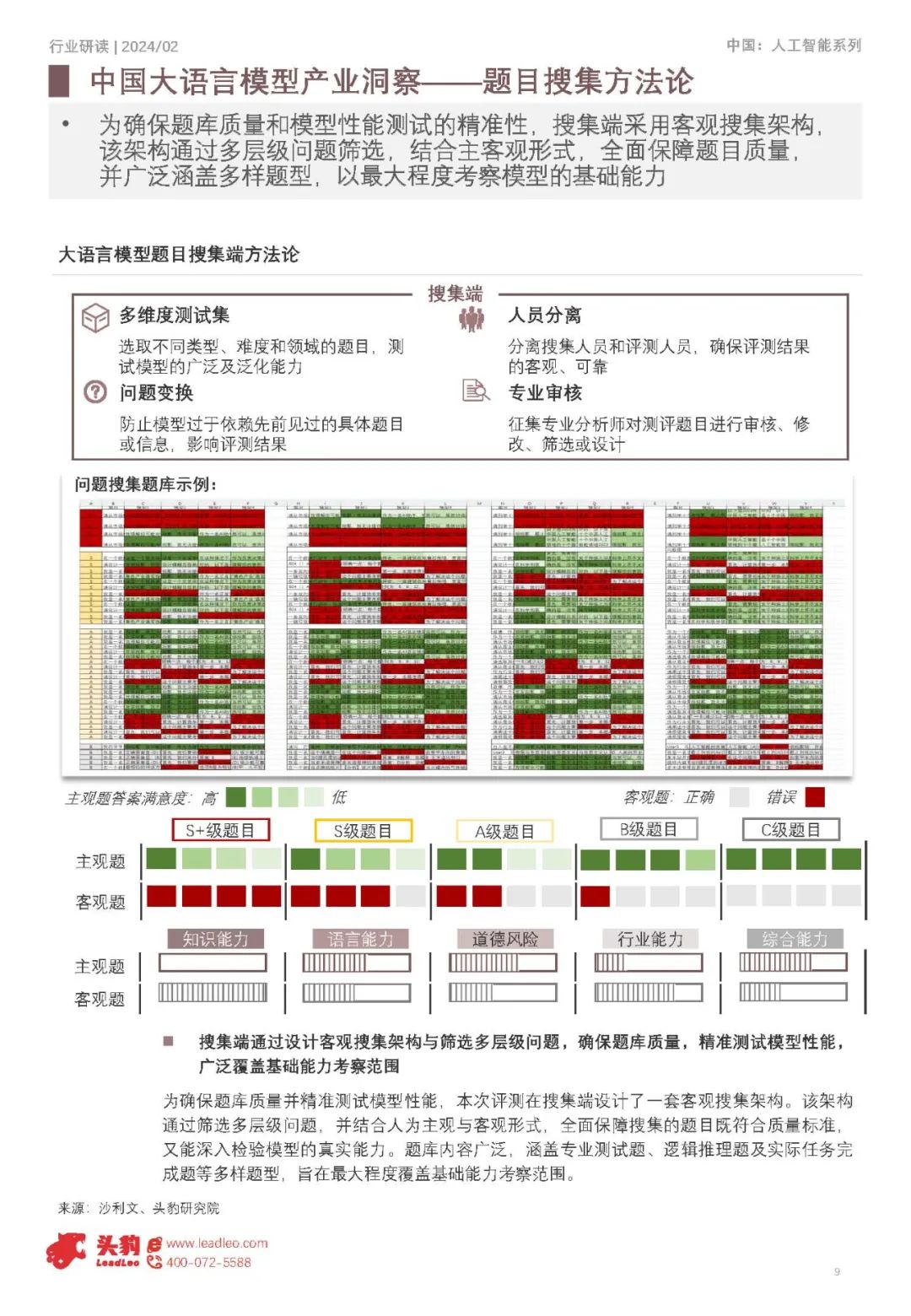
从用户实际使用角度出发,归总出五大一级评测维度,以构建全面科学的评估体系
本次大语言模型评测以用户使用体验和实际使用价值为基准,综合考量知识能力、语言能力、道德风险、行业能力及综合能力五大核心一级维度,并进一步细化为风险信息识别、逻辑推理、类比迁移、角色扮演等多个二级维度,以构建全面、科学的评估体系,确保准确衡量模型的优势与不足。 2024年大语言模型综合评测显示,国际领先模型在通用基础能力和专业应用能力上略优于中国领先模型,其中文心、GPT3.5和通义千问位居第一梯队 根据2024年大语言模型综合评测结果来看,国际领先的模型整体水平略优于中国领先大语言模型的均线。根据国际大语言模型均线、中国大语言模型均线划分出了三个梯队,第一梯队包括文心、GPT3.5以及通义千问;第二梯队包括360智脑、商汤商量、智谱AI、中科闻歌雅意以及腾讯混元;第三梯队包括Minimax、面壁智能、紫东太初、百川智能以及昆仑天工。







成为VIP会员查看完整内容
相关内容

大语言模型是基于海量文本数据训练的深度学习模型。它不仅能够生成自然语言文本,还能够深入理解文本含义,处理各种自然语言任务,如文本摘要、问答、翻译等。2023年,大语言模型及其在人工智能领域的应用已成为全球科技研究的热点,其在规模上的增长尤为引人注目,参数量已从最初的十几亿跃升到如今的一万亿。参数量的提升使得模型能够更加精细地捕捉人类语言微妙之处,更加深入地理解人类语言的复杂性。在过去的一年里,大语言模型在吸纳新知识、分解复杂任务以及图文对齐等多方面都有显著提升。随着技术的不断成熟,它将不断拓展其应用范围,为人类提供更加智能化和个性化的服务,进一步改善人们的生活和生产方式。
专知会员服务
23+阅读 · 2019年11月21日
Arxiv
86+阅读 · 2023年4月4日
Arxiv
152+阅读 · 2023年3月29日
Arxiv
85+阅读 · 2023年3月21日
相关VIP内容
专知会员服务
23+阅读 · 2019年11月21日
相关资讯
相关论文
Arxiv
86+阅读 · 2023年4月4日
Arxiv
152+阅读 · 2023年3月29日
Arxiv
85+阅读 · 2023年3月21日