论文推荐|[CVPR 2020]增广学习:面向文本行识别的网络优化协同数据增广方法

本文简要介绍CVPR 2020录用论文“Learn to Augment: Joint DataAugmentation and Network Optimization for Text Recognition”的主要工作。该论文针对训练数据的几何多样性不足的问题,提出了一种面向文本行图像的几何增广方法,并联合识别器协同训练,以提高识别器的泛化性能。
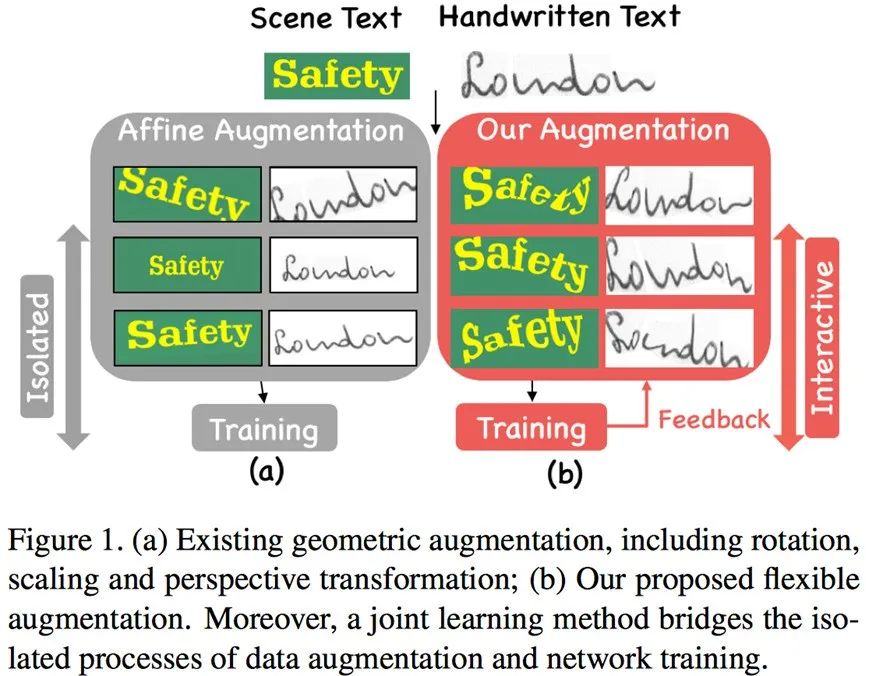
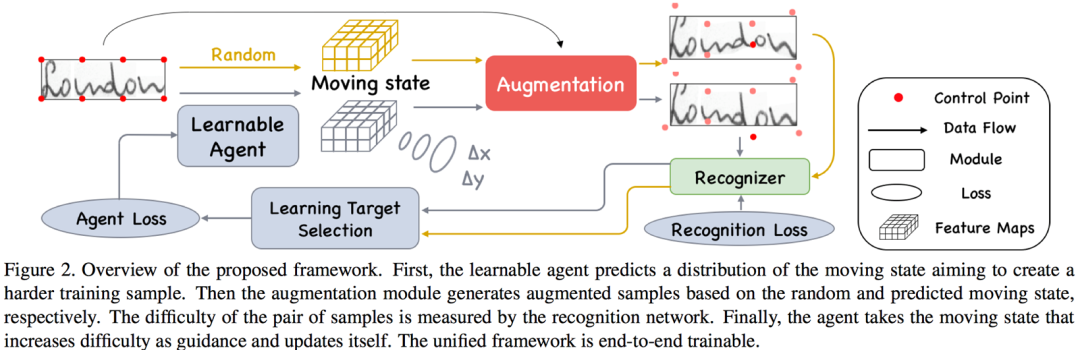
风格多变的手写文本和形状各异的场景文本,因为几何形变问题,给识别任务带来巨大的挑战[1] [2] 。在深度学习时代,为了训练一个鲁棒的识别器,大量的训练样本是必不可少的。相对于数据收集和标注来说,数据增广的成本更低,是值得选择的初步解决方案。然而,如Figure 1(a)所示,现有的几何变换方法,如旋转、缩放和透视变换,对于文本行图像来说过于简单。一张文本图像通常包含若干个字符,更合理的增广方式应该是增加各个字符的几何多样性。因此,该论文提出一种面向文本行图像的几何增广方法,可以结合识别器联合训练。据我们了解,这有可能是第一个针对文本行图像设计的联合学习优化几何增广方法。
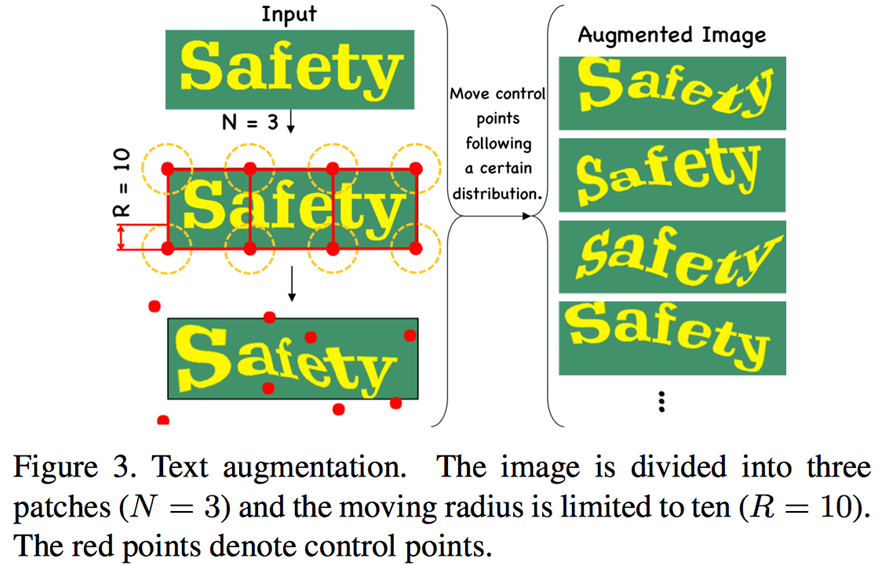
给定一张文本行图像,几何增广的目的是增加每个字符的几何多样性。从这个角度出发,作者在图像上初始化更多的控制点,并移动这些控制点以扭曲图像,如Figure 3所示。
在几何变换方法的选择上,作者对比和讨论了两种常用的图像变换方法[3] :Similarity Transformation和Rigid Transformation。如Figure 4所示,对于普通物体来说,Rigid Transformation可以保持物体的真实感,而文本行图像的增广则优先考虑变换的灵活性,所以Similarity Transformation更合适。后续的实验也证明了这一点。

Similarity Transformation的流程如下。给定图像上的点u,通过线性变换M得到新的位置,
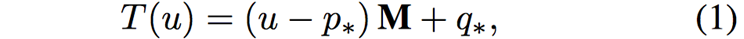
其中,p*和q*分别是控制点移动前和移动后的加权质心,
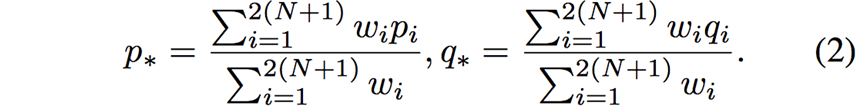
权重的物理意义为:离点u越近的控制点,对u影响越大。定义为
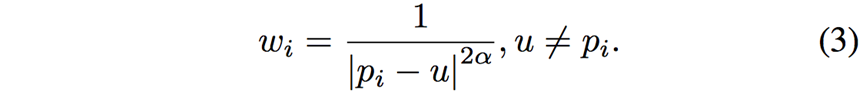
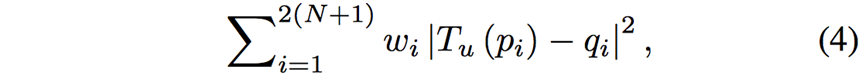

首先作者探究了训练数据量、Patch数量和控制点移动距离范围对性能的影响。实验结果如Table 2-4及Figure 5所示。
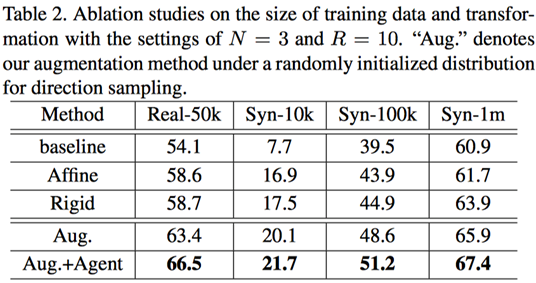
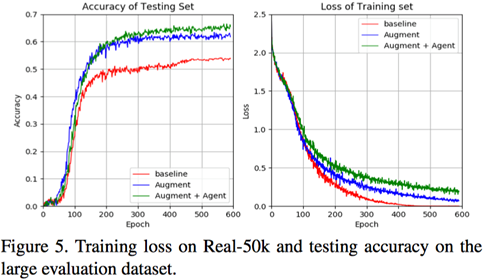
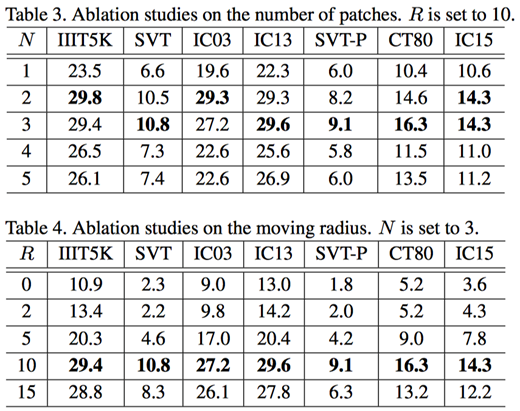
在小训练集的设置下,该论文提出的增广方法优于现存的增广方法,带来了显著的提升(见Table 2)。在该论文的实验设置下,作者发现N=3和R=10可以得到最优效果(Table 3-4),并把该设置沿用到后续实验中。
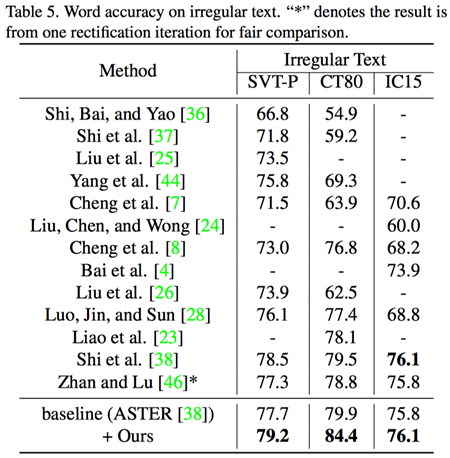
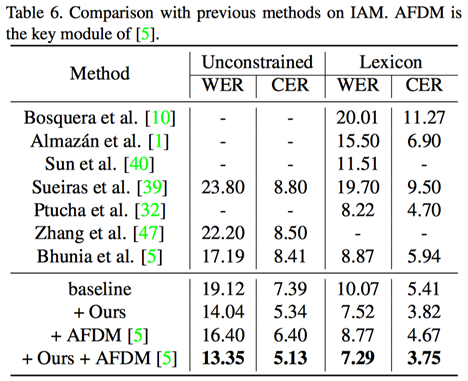
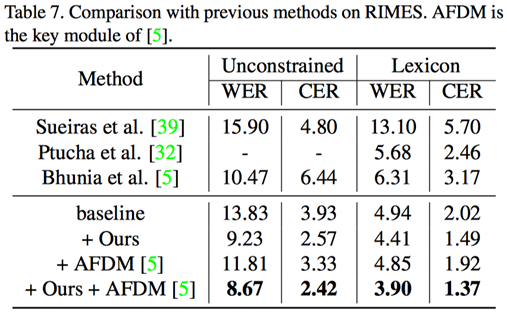
值得注意的是,该论文提出的方法作为一个元框架(Metaframework),可以和更多的增广方法相结合,例如CVPR 2019的AFDM方法[1] ,可以得到更好的效果(见Table 6-7所示)。
该论文提出了一种面向文本行图像的几何增广方法,和简单的几何变换不同,这种方法可以丰富各个字符的几何多样性。作者进一步提出一种可学习增广方式,可以联合识别器端到端训练。这是针对文本行图像增广的初步探索,该问题仍然有很大的研究空间。文本图像的合成和增广,作为文本识别领域的特色问题,值得我们进一步讨论和研究。
论文地址:https://arxiv.org/abs/2003.06606
数据增广工具包下载地址: (1)https://github.com/Canjie-Luo/Text-Image-Augmentation (2)https://github.com/HCIILAB/Text-Image-Augmentation
[1] Bhunia A K, Das A, Bhunia A K, et al. “Handwriting recognition in low-resource scripts using adversarial learning.” CVPR, 2019,pp. 4767-4776.
[2] B. Shi, M. Yang, X. Wang, P. Lyu, C. Yao, and X. Bai, “ASTER: AnAttentional Scene Text Recognizer with Flexible Rectification.” IEEE TPAMI,vol. 41, no. 9, pp. 2035–2048, Sep. 2019.
[3] S. Schaefer, T. McPhail, and J.Warren, “Image deformation using Moving Least Squares.” ACM TOG, 2006, vol. 25,no. 3, pp. 533–540.
原文作者:Canjie Luo, YuanzhiZhu, Lianwen Jin,Yongpan Wang
编排:高 学
审校:连宙辉
发布:金连文







