
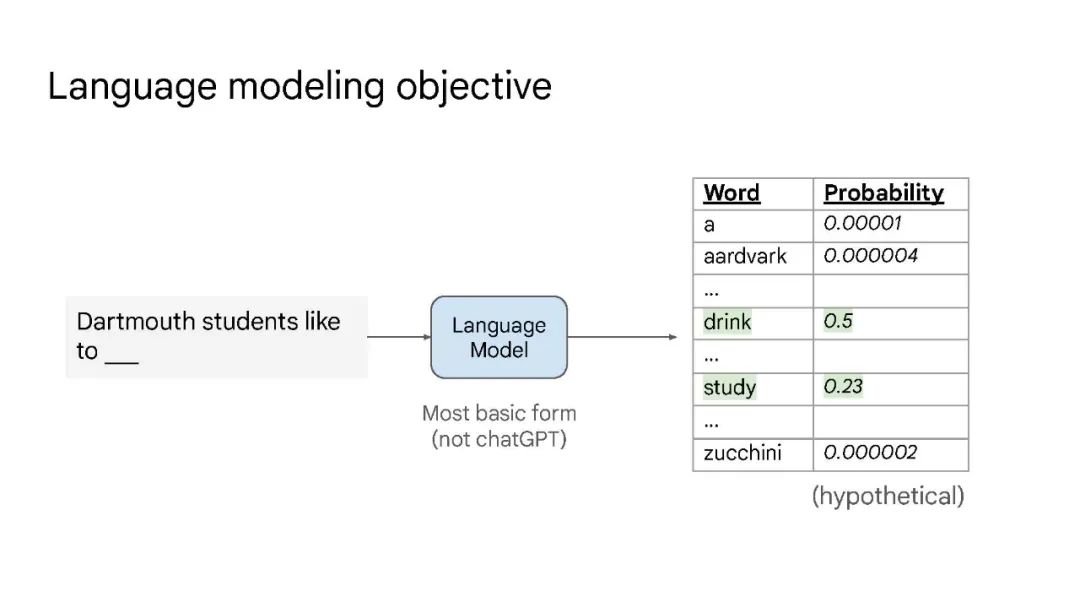
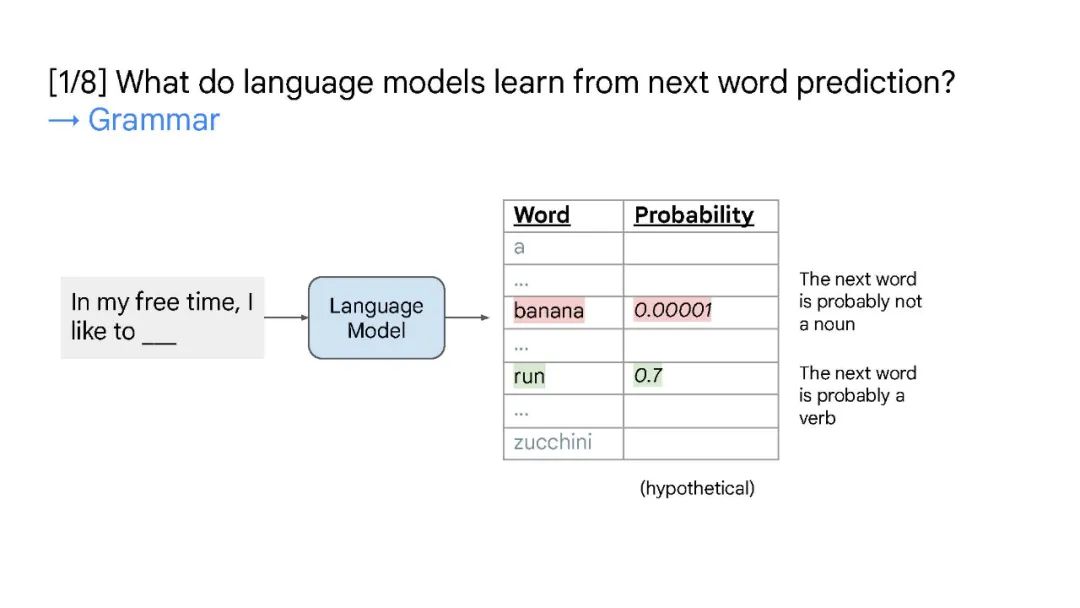
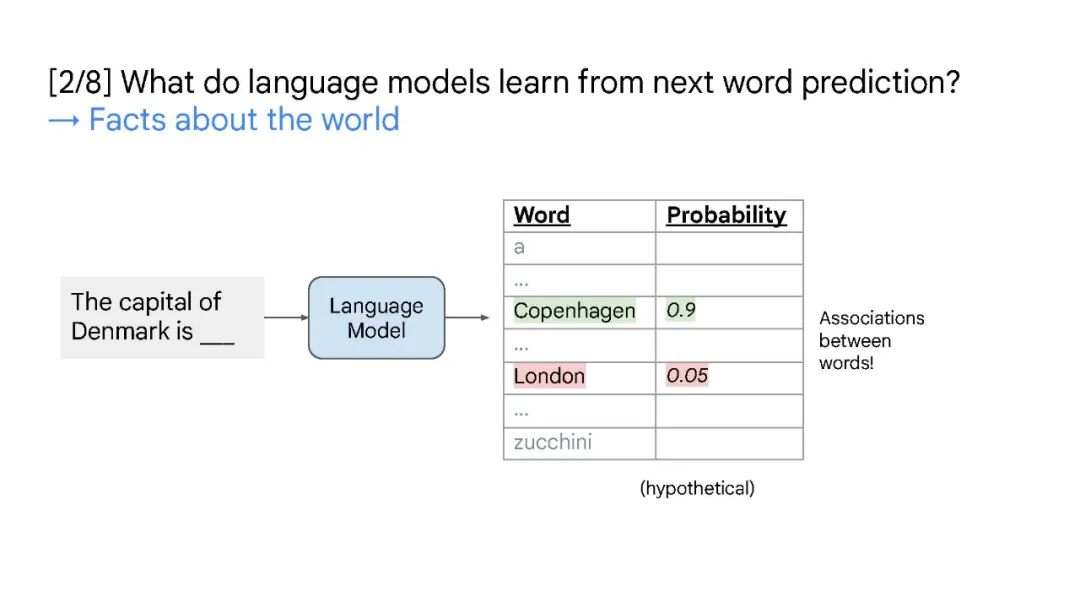
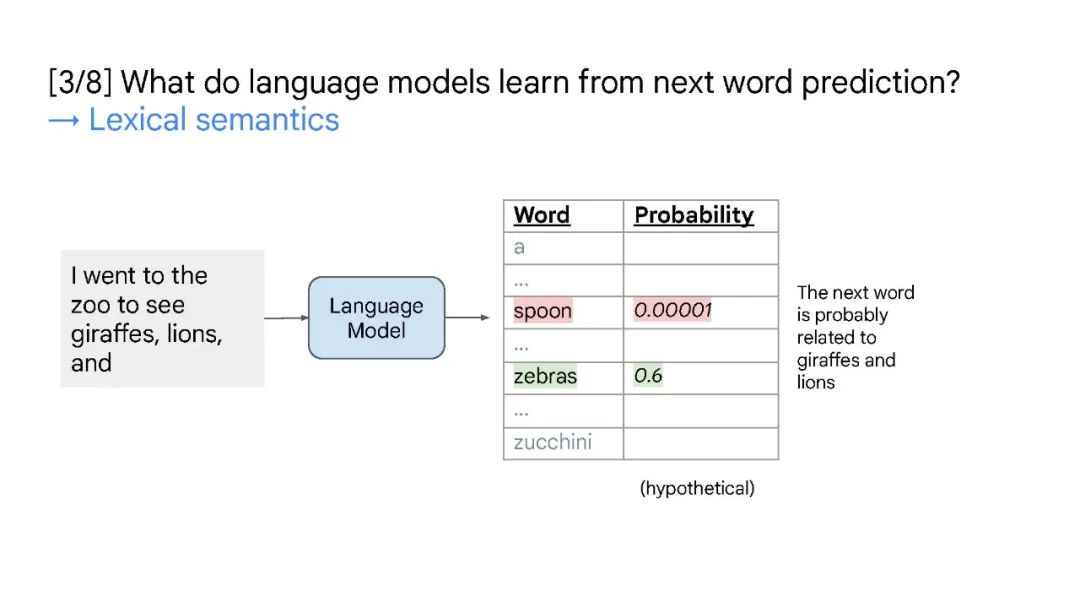
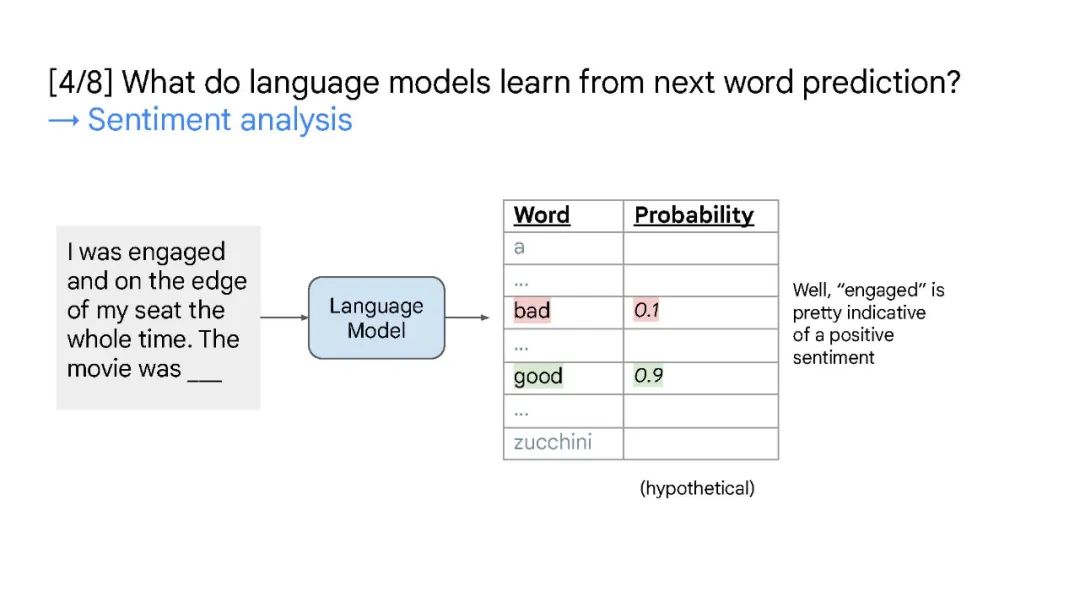
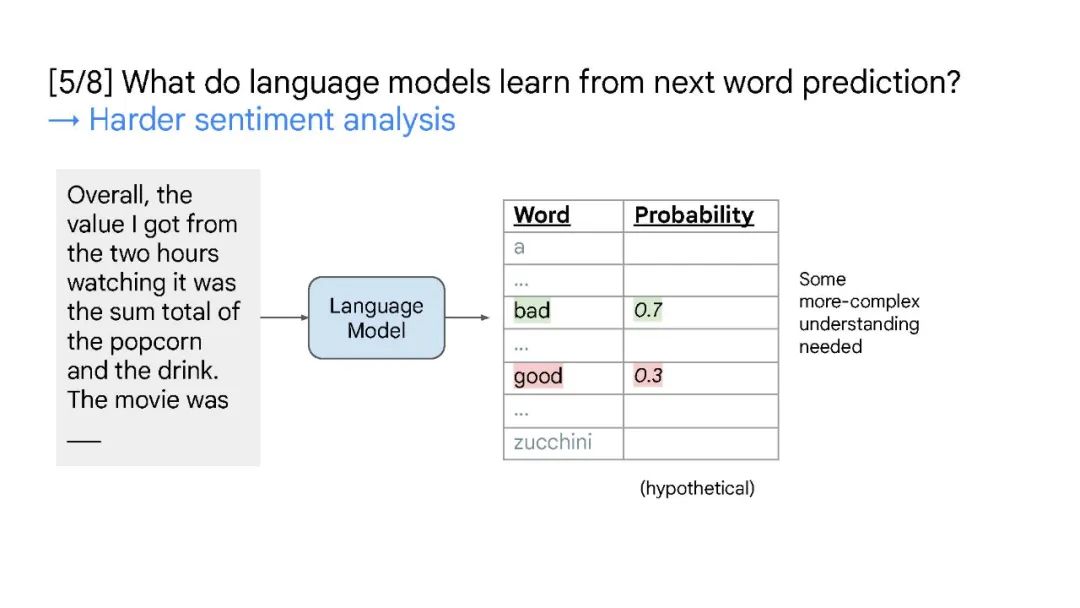
本次演讲将涵盖大型语言模型中的三个概念——缩放、涌现和推理。缩放是增加 LLMs 模型容量的关键因素,最开始 GPT-3 将模型参数增至 1750 亿,随后 PaLM 进一步将模型参数增至 5400 亿。大规模参数对于涌现能力至关重要。缩放不仅针对模型大小,还与数据大小和总计算量有关。大型语言模型中的突现能力是在小型模型中不存在,但在大型模型中存在的能力。涌现能力的存在意味着进一步的扩展可能会导致语言模型具有更多的新能力。推理是机器学习长期以来面临的挑战的关键,例如从少数示例或抽象指令中学习。大型语言模型仅通过思维链提示就显示出了令人印象深刻的推理能力,这鼓励模型在给出最终答案之前生成中间推理步骤。
缩放是一个简单的想法,具有挑战性,但可以预见地使模型更好。(“缩放法”)
由于规模的扩大,大型语言模型获得了小型模型中不存在的新能力。(“涌现能力”)
巧妙的提示引出了语言模型中的多步骤推理,解锁了更多的新任务。(“提示工程”)
Jason Wei是谷歌Brain的高级研究科学家。他的工作围绕大型语言模型的三个方面:指令微调、思维链提示和突发能力。他之前在谷歌的AI实习项目中工作,在此之前他毕业于达特茅斯学院。https://www.jasonwei.net/

成为VIP会员查看完整内容



相关内容

Arxiv
0+阅读 · 2023年6月1日
Arxiv
11+阅读 · 2019年10月30日


相关VIP内容
相关资讯
相关论文
Arxiv
0+阅读 · 2023年6月1日
Arxiv
11+阅读 · 2019年10月30日