

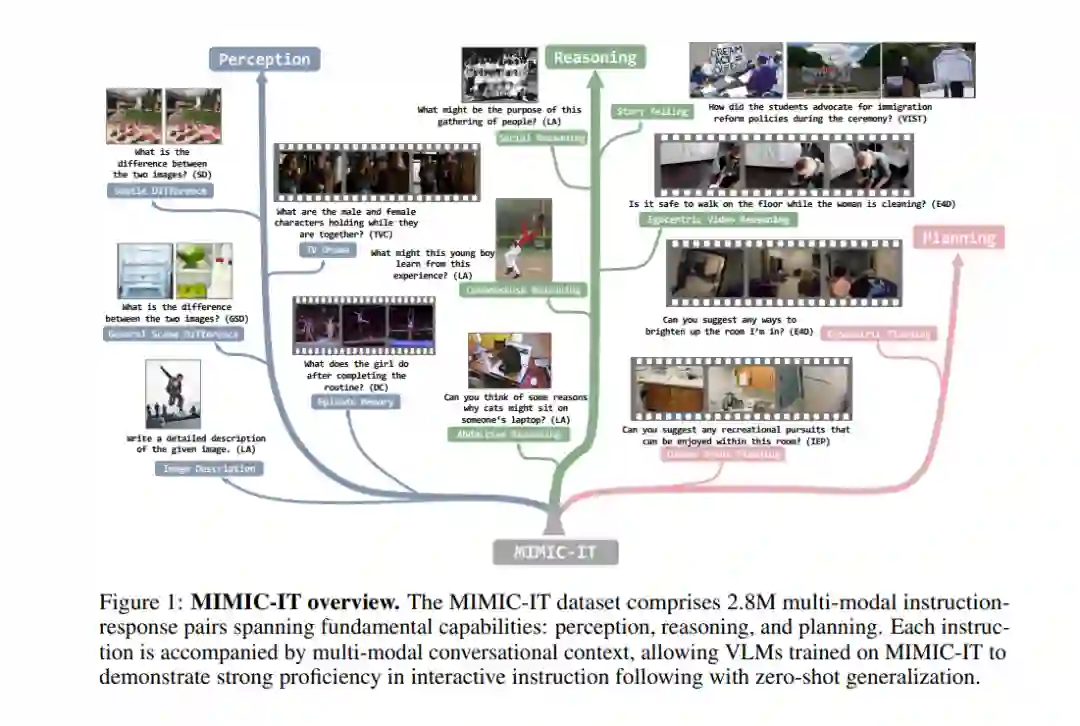
高质量的指令和回应对于大型语言模型在自然语言交互任务中的零样本性能至关重要。对于涉及复杂视觉场景的交互式视觉语言任务,大量多样性和创新性的指令回应对应关系对于调优视觉语言模型(VLM)应该是至关重要的。然而,目前在数量、多样性和创造性方面,视觉语言指令回应对应关系的可获取性仍然有限,这对交互式VLM的泛化能力提出了挑战。在这里,我们提出了一种名为MultI-Modal In-Context Instruction Tuning(多模态上下文指令调整,简称MIMIC-IT)的数据集,它包含280万对多模态指令回应对应关系,其中220万个独特的指令源自图片和视频。每对指令回应都附带有多模态上下文信息,形成了旨在提升VLM在感知、推理和规划能力的对话上下文。我们将收集指令回应的过程称为Syphus,它通过结合人类的专业知识和GPT的能力,使用自动注释流程进行扩展。使用MIMIC-IT数据集,我们训练了一个大型的VLM,名为Otter。在对视觉语言基准进行广泛评估的基础上,我们观察到Otter在多模态感知、推理和上下文学习方面表现出显著的熟练程度。人类评估揭示,它有效地与用户的意图对齐。我们发布了MIMIC-IT数据集、指令回应收集流程、基准和Otter模型。
成为VIP会员查看完整内容
相关内容

相关VIP内容
相关资讯