

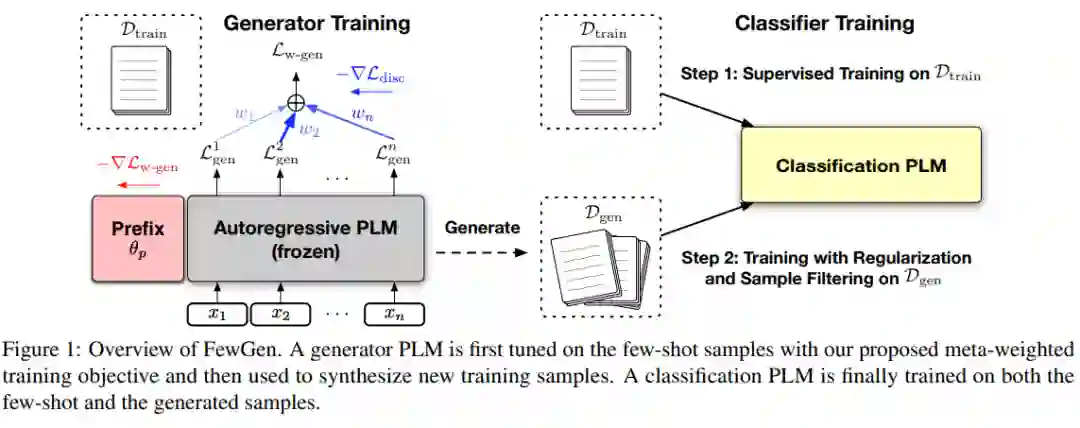
最近的研究揭示了预训练语言模型(PLMs)的有趣的少样本学习能力:他们可以在微调了少量标记数据后快速适应新任务,这些数据被构造成提示,无需大量的任务特定注解。尽管他们的表现很有希望,但大多数只从小型训练集中学习的少样本方法的表现仍然远低于完全监督的训练。在这项工作中,我们从不同的角度研究了PLMs的少样本学习:我们首先调整一个自回归PLM在少样本样本上,然后用它作为生成器来生成大量的新的训练样本,这些样本增加了原始的训练集。为了鼓励生成器产生标签判别样本,我们通过加权最大似然训练它,其中每个token的权重根据判别元学习目标自动调整。然后,一个分类PLM可以在少样本和合成样本上进行微调,并进行正则化以获得更好的泛化和稳定性。我们的方法FewGen在GLUE基准测试的七个分类任务中,比现有的少样本学习方法取得了更好的整体结果,平均提高了无增强方法5+个百分点,超过了增强方法3+个百分点。Tuning Language Models as Training Data Generators for Augmentation-Enhanced Few-Shot Learning
成为VIP会员查看完整内容
相关内容

UniViLM: A Unified Video and Language Pre-Training Model for Multimodal Understanding and Generation
Arxiv
19+阅读 · 2020年2月15日
相关VIP内容
相关资讯
相关论文
UniViLM: A Unified Video and Language Pre-Training Model for Multimodal Understanding and Generation
Arxiv
19+阅读 · 2020年2月15日