

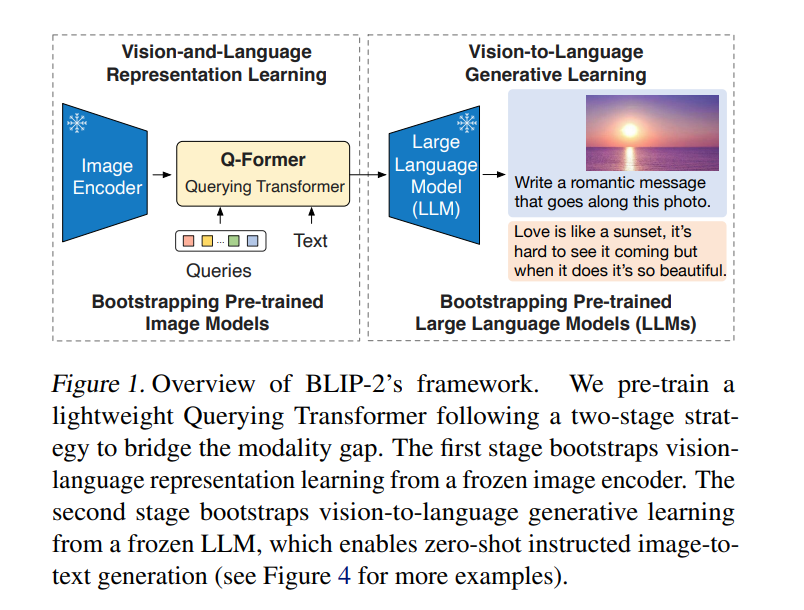
由于大规模模型的端到端训练,视觉和语言预训练的成本变得越来越令人望而却步。本文提出BLIP-2,一种通用而有效的预训练策略,从现成的冻结预训练图像编码器和冻结的大型语言模型中引导视觉-语言预训练。BLIP-2通过一个轻量级的查询Transformer弥合了模式差距,该Transformer分两个阶段进行预训练。第一阶段从冻结的图像编码器中引导视觉-语言表示学习。第二阶段从一个冻结的语言模型中引导视觉到语言的生成学习。BLIP-2在各种视觉语言任务上取得了最先进的性能,尽管可训练参数比现有方法少得多。例如,所提出模型在零样本VQAv2上的表现比Flamingo80B高出8.7%,可训练参数减少了54倍。还展示了该模型的零样本图像到文本生成的新兴能力,可以遵循自然语言指令。
https://www.zhuanzhi.ai/paper/07f6ce13e18cd1dc714cf3d3f88d1e56

成为VIP会员查看完整内容
相关内容

Arxiv
0+阅读 · 2023年6月12日
Arxiv
0+阅读 · 2023年6月12日
Arxiv
0+阅读 · 2023年6月8日
Arxiv
42+阅读 · 2023年4月19日
Arxiv
11+阅读 · 2019年10月30日

相关VIP内容
相关资讯
相关论文
Arxiv
0+阅读 · 2023年6月12日
Arxiv
0+阅读 · 2023年6月12日
Arxiv
0+阅读 · 2023年6月8日
Arxiv
42+阅读 · 2023年4月19日
Arxiv
11+阅读 · 2019年10月30日