「知识增强预训练语言模型」最新研究综述
预训练模型主要从海量未标注、无结构化的数据中学习,但缺少外部知识指导,存在模型学习效率不高、模型效果不佳和知识推理能力 受限等不足。如何在预训练模型中引入语言知识、世界知识等外部知识,提升模型效果以及知识记忆和推理能力是一个难题。本文 对知识增强预训练语言模型(KE-PLMs)进行了全面的综述。

预训练语言模型通过自监督学习方法在大型文本语料库上进行训练,在自然语言处理(NLP)的各种任务中取得了良好的性能。然而,尽管具有大参数的PLM可以有效地拥有从大量训练文本中获得的丰富知识,并在调优阶段对下游任务有利,但由于缺乏外部知识,它们仍然存在推理能力差等局限性。研究人员致力于将知识整合到PLM中,以解决这些问题。在这篇论文中,我们对知识增强预训练语言模型(KE-PLMs)进行了全面的综述,以提供对这一蓬勃发展的领域的清晰洞察。我们分别介绍了自然语言理解(NLU)和自然语言生成(NLG)的适当分类法,以突出自然语言处理的这两个主要任务。对于NLU,我们将知识类型分为四类:语言知识、文本知识、知识图谱(KG)和规则知识。用于NLG的KE-PLMs分为基于KG的方法和基于检索的方法。最后,我们指出了KE-PLMs未来的发展方向。
https://www.zhuanzhi.ai/paper/d29c4e105f7150131e1347d799681e73
1.概述
近年来,随着深度学习技术的不断发展,在海量文本语料库上以无监督目标训练的预训练语言模型(Pre-trained Language Model, PLM)被广泛应用于自然语言处理(Natural Language Processing, NLP)领域,并在各种下游任务上取得了最先进的性能。与传统的监督学习不同的是,基于自监督学习的plm通常先对通用的大规模无标记数据进行预训练,然后针对特定任务对小规模标记数据进行微调。BERT[1]、GPT[2]、T5[3]等代表工作在众多自然语言理解(NLU)和自然语言生成(NLG)任务中不断刷新基准记录,成功推动了自然语言处理(NLP)的发展。
随着PLMs的规模越来越大,拥有数亿个参数的PLMs已被广泛认为能够在某些探测中捕获丰富的语言[4]、[5]、[6]和事实知识[7]、[8]。然而,由于缺乏原始数据中知识的显式表示,PLM在下游任务上的性能受到限制。特别是,先前的研究发现,传统的预训练目标往往具有较弱的符号推理能力[9],因为PLM倾向于集中于词共现信息。将知识整合到plm中可以增强他们的记忆力和推理能力。例如,在“the monument to the people 's Heroes庄严地坐在[MASK] square”的语言理解问题中,传统PLM预测蒙面位置的输出为“the”,而知识增强PLM预测的输出为“天安门”,准确率更高。
对于语言生成,虽然现有PLMs能够从文本语料库中获取丰富的语言信息并生成正确的句子,但由于忽略了外部世界知识[11],几乎所有PLMs都无法生成面向捕捉人类常识的输出。换句话说,PLMs生成的句子往往符合语法规范,但不符合逻辑。例如,给定一个概念集{hand, sink, wash, soap}来生成一个句子,传统的PLM可能会生成“hands washing soap on the sink”,而具有额外知识的PLM生成“man is wash his hands with soap in a sink”,这更自然、更符合逻辑。
为了解决上述问题,将知识明确地融入PLMs已经成为最近NLP研究的一个新兴趋势。Wei等人[12]从三个方面回顾了知识增强的PLM:知识来源类型、知识粒度和应用。Yin等人总结了基于预训练语言模型的知识增强模型(PLMKEs)的最新进展,根据PLMKEs的三个关键元素: 知识来源、知识密集型NLP任务和知识融合方法。在本研究中,考虑到在语言模型中注入知识可以促进NLU和NLG任务的完成,而这两个领域的重点不同,我们旨在对这两个领域的知识增强预训练语言模型(知识增强预训练语言模型,KEPLMs)进行综合综述,以提供知识增强预训练语言模型在NLU和NLG中的各自见解。本综述的主要贡献可归纳如下:
(1) 在本次综述中,我们将KE-PLMs 按照下游任务分为两大类:NLU和NLG。本文分别提出了适当的分类法,以突出说明自然语言处理中这两种不同任务的重点。
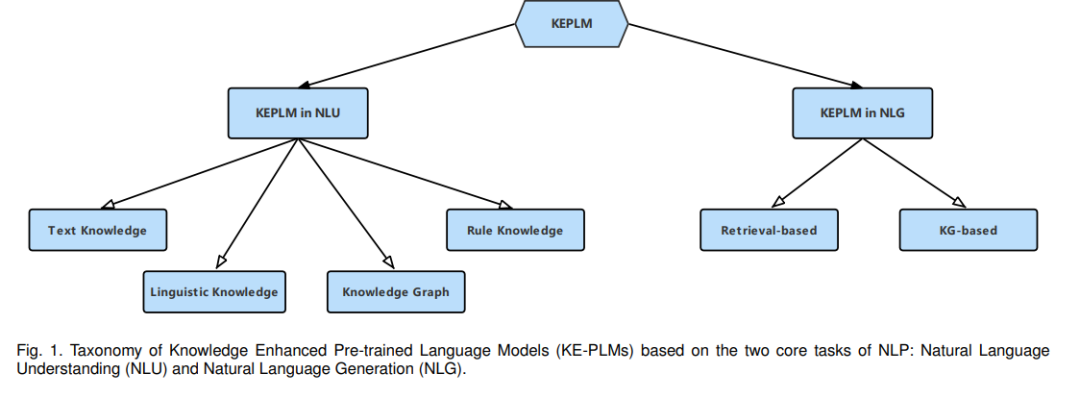
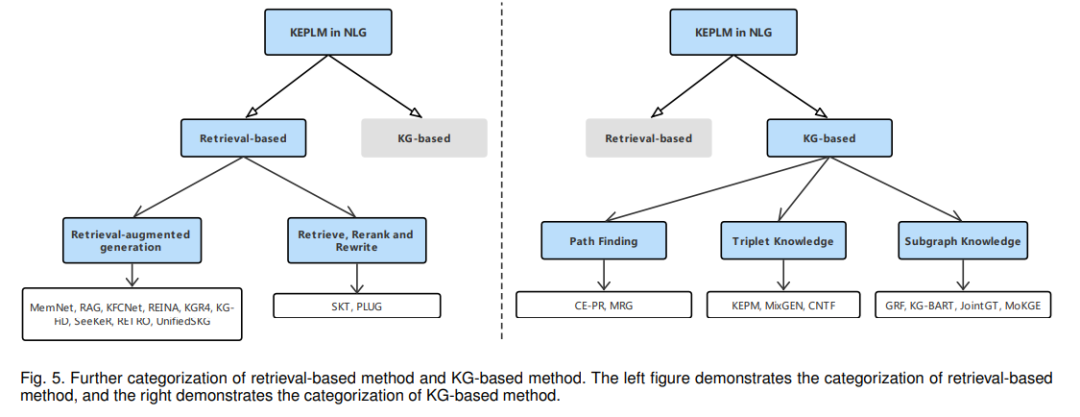
(2) 对于NLU,根据知识类型将KE-PLMs进一步划分为语言知识、文本知识、知识图(KG)和规则知识四个子类别。对于NLG,基于知识来源,将KE-PLMs 进一步分为基于检索的方法和基于KG的方法。图1显示了我们为NLU和NLG提出的分类法。
(3) 讨论了未来可能解决KE-PLMs存在的问题和挑战的一些可能的方向。
本文的其余部分安排如下。在第二节中,我们介绍了自然语言处理中训练范式发展下PLM的背景。在第三节中,我们介绍了NLU领域中KE-PLM的分类。在第4节中,我们介绍了在NLG领域的KE-PLM的分类。对于NLU和NLG领域,我们讨论了分类法中每个叶类的代表性工作。在第五部分中,基于现有的局限性和挑战,我们提出了未来KE-PLM可能的研究方向。最后,我们在第6节中进行总结。
2. 知识增强预训练语言模型自然语言理解
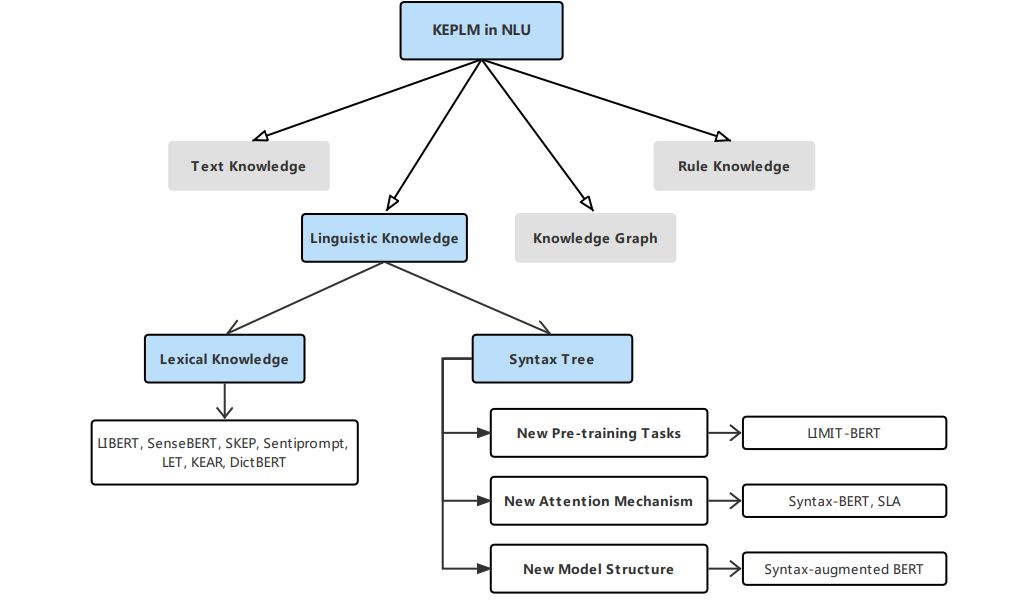
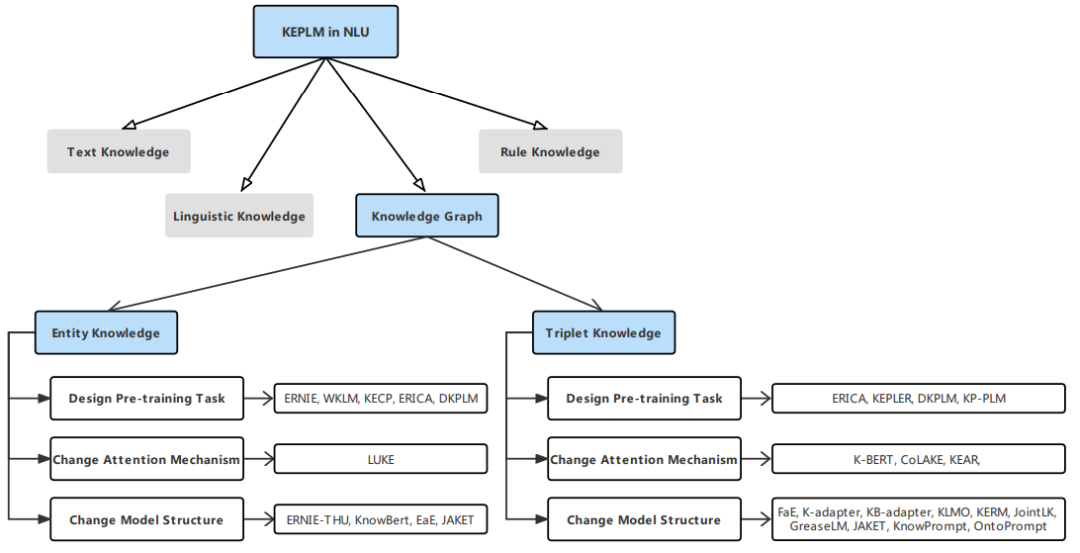
NLU是NLP的一个组成部分,涉及使机器能够理解和解释文本数据内容的所有方法。它从非结构化文本中提取核心语义信息,并将这些信息应用于下游任务,因此在文本分类、关系提取、命名实体识别(NER)和对话系统等应用程序中发挥着重要作用。根据图1所示的分类法,我们将为NLU任务设计的KE-PLM所包含的知识按照不同的类型分为以下四类: 语言知识、文本知识、知识图谱和规则知识。对于每一类,我们讨论了其代表性的方法。
语言知识
知识图谱:
3. 知识增强预训练语言模型自然语言生成
4. 未来发展方向
在本节中,我们提出了未来KE-PLMs可能的研究方向,以应对目前存在的问题和挑战。
整合同质源和异构源的知识
探索多模态知识
提供可解释性证据
持续学习知识
优化知识整合到大模型中的效率
增加生成结果的多样性
专知便捷查看
便捷下载,请关注专知公众号(点击上方蓝色专知关注)
后台回复“KEPM” 就可以获取《「知识增强预训练语言模型」最新研究综述》专知下载链接