

偏好调整是将深度生成模型与人类偏好对齐的关键过程。本文对偏好调整及其与人类反馈的整合的最新进展进行了全面综述。文章分为三个主要部分:
介绍和预备知识:介绍强化学习框架、偏好调整任务、模型和跨不同模态(语言、语音、视觉)的数据集,以及不同的策略方法;
深入分析每种偏好调整方法:详细分析偏好调整中使用的方法;
应用、讨论与未来方向:探讨偏好调整在下游任务中的应用,包括不同模态的评估方法,以及未来研究方向的展望。
我们的目标是展示偏好调整与模型对齐的最新方法,提升研究人员和从业者对该领域的理解。我们希望能够激励更多人参与并推动这一领域的创新。 关键词:偏好调整、人类偏好、强化学习、多模态、多语言、大型语言模型、视觉语言模型、语音语言模型、生成模型、综述、DPO、RLHF。
1 引言
从人类反馈中学习是将生成模型与人类偏好对齐的重要步骤,旨在生成与人类语言和写作相似的输出。尽管生成模型在自监督学习中的学习能力强大,但这些模型经常误解指令,导致生成出现幻觉 (Ji 等, 2023a; Yao 等, 2023a)。此外,确保生成内容的安全性仍是这些模型面临的重大挑战。关于使用人类反馈进行偏好调整的广泛研究表明,对抗样本可以用来破解系统 (Rando 和 Tram`er, 2023; Wei 等, 2024)。理想情况下,生成模型需要受到控制,以确保其输出是安全的并且不会造成伤害。模型通常会表现出意外行为,例如编造事实 (Chen 和 Shu, 2023; Sun 等, 2024),生成带有偏见或有害的文本 (Hartvigsen 等, 2022),或未能遵循用户指令 (Ji 等, 2023b; Tonmoy 等, 2024)。此外,数据隐私的保护至关重要,以确保模型的安全运行并保护用户隐私 (Brown 等, 2022)。在文本到图像生成任务中,大规模模型常常难以生成与文本提示紧密对齐的图像 (Feng 等, 2022),尤其是在组合图像生成 (Liu 等, 2022; Lee 等, 2023) 和连贯生成方面 (Liu 等, 2023a)。同样,在文本到语音任务中,Zhang 等 (2024a) 和 Chen 等 (2024a) 将主观人类评价整合到训练循环中,以更好地使合成语音符合人类偏好。 偏好调整已广泛应用于语言任务,通过训练指令调整的大型语言模型(LLM)来实现,例如 Llama (Touvron 等, 2023b; Dubey 等, 2024),Phi (Abdin 等, 2024),Mistral (Jiang 等, 2023a),Nemotron (Parmar 等, 2024; Adler 等, 2024),Gemma (Team 等, 2024)。诸如 GPT-4 (Achiam 等, 2023),Gemini (Team 等, 2023; Reid 等, 2024),Claude (Anthropic, 2024),Command-R 和 Reka (Ormazabal 等, 2024) 等商业模型也利用了人类偏好对齐来提升其性能。LLM 的对齐提高了任务特定技能、连贯性、流畅性,并有助于避免不期望的输出。此外,多语言 LLM 的对齐研究也有所裨益,例如 Aya (Aryabumi 等, 2024; Ust¨un 等, 2024),BLOOMZ 和 mT0 (Muennighoff 等, 2023),以及区域性 LLM 如 Cendol (Cahyawijaya 等, 2024) 和 SEALLM (Nguyen 等, 2023)。实现 LLM 对齐的常见方法包括使用强化学习技术,通过最大化奖励来引导语言模型遵循偏好样本。通过人类反馈的强化学习(RLHF)(Christiano 等, 2017) 是最早用于使模型与人类偏好对齐的方法,进一步应用于深度学习领域,并通过其在 LLM 中的成功(Ouyang 等, 2022;Bai 等, 2022a)得到普及,采用了 PPO (Schulman 等, 2017),REINFORCE (Kool 等, 2019),在线定向偏好优化 (Guo 等, 2024a) 和监督微调 (SFT)-类方法 (Dong 等, 2023)。它通常包括三个关键方面:人类反馈收集、奖励建模和在线 RL 进行策略优化。然而,最近的方法允许在离线方式下与策略模型一起训练奖励模型,正如 DPO (Rafailov 等, 2024) 所展示的那样,并通过离线和在线策略的联合训练 (Zhao 等, 2023) 进行优化。此外,偏好调整还应用于视觉文本任务,已被证明能够通过图像和文本嵌入的对齐分数(使用预训练的视觉文本模型,如 CLIP (Radford 等, 2021) 和 CoCa (Yu 等, 2022a) 进行衡量)来改善图像和文本的表示 (Ramesh 等, 2022;Saharia 等, 2022;Yu 等, 2022b)。Wu 等 (2023c) 使用 LoRA (Hu 等, 2021) 对齐 Stable Diffusion (Lee 等, 2023),这是一种视觉文本预训练模型。关于语音的应用尚未被广泛探索,相关文献中仅有少量工作。Zhang 等 (2024a) 研究了代码与文本之间的对齐。
本文对不同模态下的人类反馈偏好调整的最新进展进行了综述。它不仅提供了一个全面的介绍,包括相关基础知识以帮助读者熟悉这一主题,还对最新提出的方法进行了深入回顾和讨论。总结来说,本文包括以下贡献: * 我们对语言、语音和视觉任务等不同模态的模型的偏好调整进行了全面概述,并扩展到所有现有的偏好调整方法,包括强化学习(RL)方法。 * 我们从现有文献中整理并系统化了偏好调整的框架和分类。 * 我们展示了偏好调整在使用人类反馈改善生成方面的各种应用,并描述了用于评估深度生成模型质量的自动和基于人类的评估方法。 * 我们讨论了偏好调整的机会和未来研究方向。
通过这篇综述,我们旨在展示偏好调整和生成模型对齐的最新方法,使研究人员和从业者能够更好地理解这一主题并进一步创新。
分类法
我们为所有偏好调整方法定义了以下类别,如表 2 所示。图 1 展示了我们在本综述文章中研究的五个类别,并描述如下:

采样
类似于强化学习(RL)文献,我们根据如何采样数据并使用它们进行训练或获取奖励对方法进行分类:离线和在线的人类对齐。这一分类与我们如何计算奖励并将其用于策略模型有关。在在线人类对齐设置中,智能体通过与环境交互收集一批样本,并使用它们更新策略。这些样本的奖励可以通过奖励模型收集,或由策略模型生成的样本获得。而在离线人类对齐设置中,数据来自于离线的人类演示。对于在线方法,我们还将这些方法分类为同策略(行为策略与优化策略相同)或异策略(行为策略与优化策略不同)。
模态
我们研究了偏好调整在不同模态中的使用,例如文本、语音、视觉、运动觉等。如果我们无法对其进行分类,则归为“其他”。在自然语言处理(NLP)的最新进展中,强化学习的理念已进一步扩展到语言和语音任务,甚至跨模态任务(如视觉-文本)。因此,按研究的模态(例如文本、语音、视觉、视觉-文本)对论文进行分类是非常重要的。
语言
我们探索了偏好调整在不同语言中的应用。在这种情况下,我们将方法分类为英语、非英语和多语言。
奖励粒度
在偏好调整中,奖励可以在不同的粒度水平上计算。粒度水平可扩展为两类:样本级和标记级。每种模态的标记级可能不同,例如在文本任务中,我们可以使用词汇中的子词作为标记;在视觉任务中,图像的片段可以作为标记。
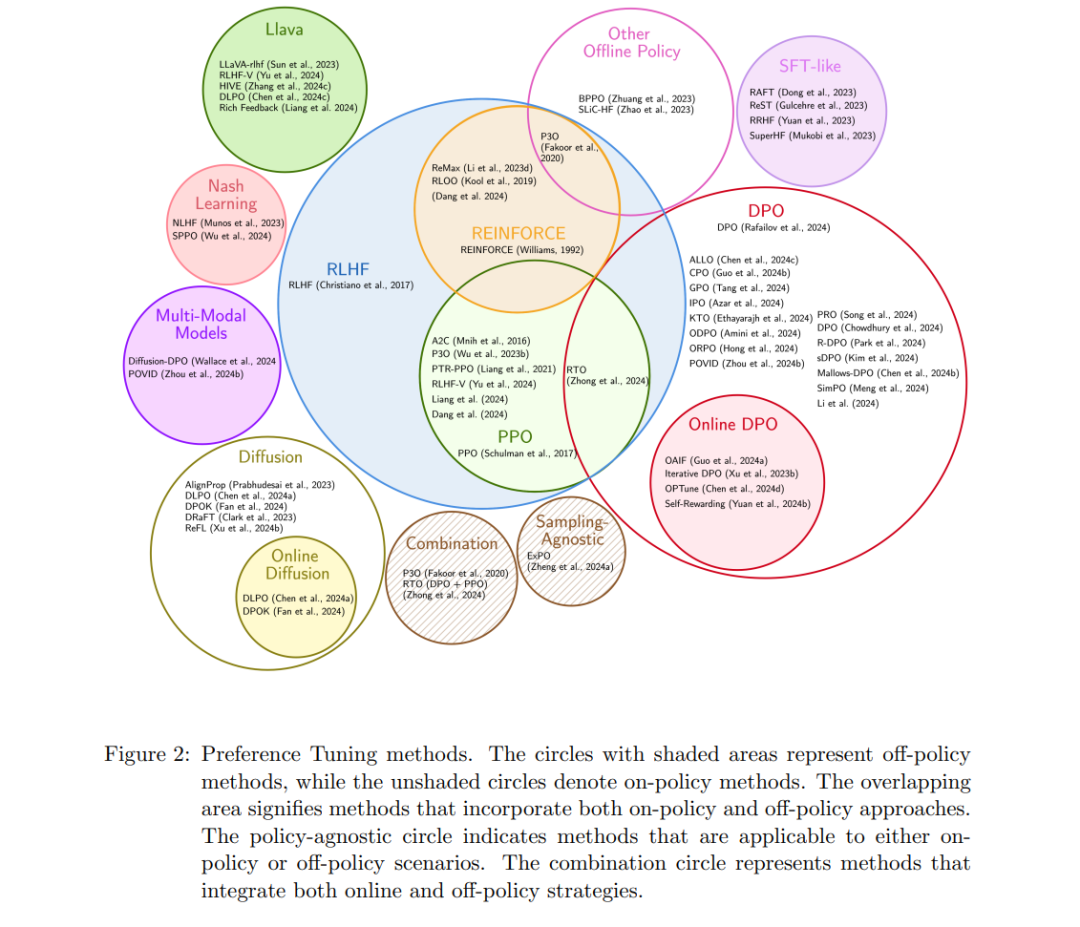
偏好调整
在本节中,我们介绍了用于训练偏好调整生成模型的通用框架。如表 3 所示,偏好调整的训练框架通常从**监督微调(SFT)**阶段开始,在此期间,生成模型通过下一个标记预测任务进行训练,或者使用经过指令微调的模型作为基础初始化模型。SFT 的重点在于提升模型生成标记的能力,因为它引导模型如何响应输入提示。当模型能够正确生成流畅的文本序列后,通过强化学习(RL)进一步进行策略优化,使模型与偏好目标对齐。对齐的目的是引导模型根据偏好目标以适当的方式回答问题。这一步是确保模型生成与人类偏好一致的必要训练阶段,因此模型的行为会更接近人类的表现。值得注意的是,人类对齐阶段也可以与 SFT 进行联合训练。


