
新加坡公立大学最新《有限数据、少量样本和零样本下的生成建模》综述》,详述在数据约束下的生成建模,非常值得关注!

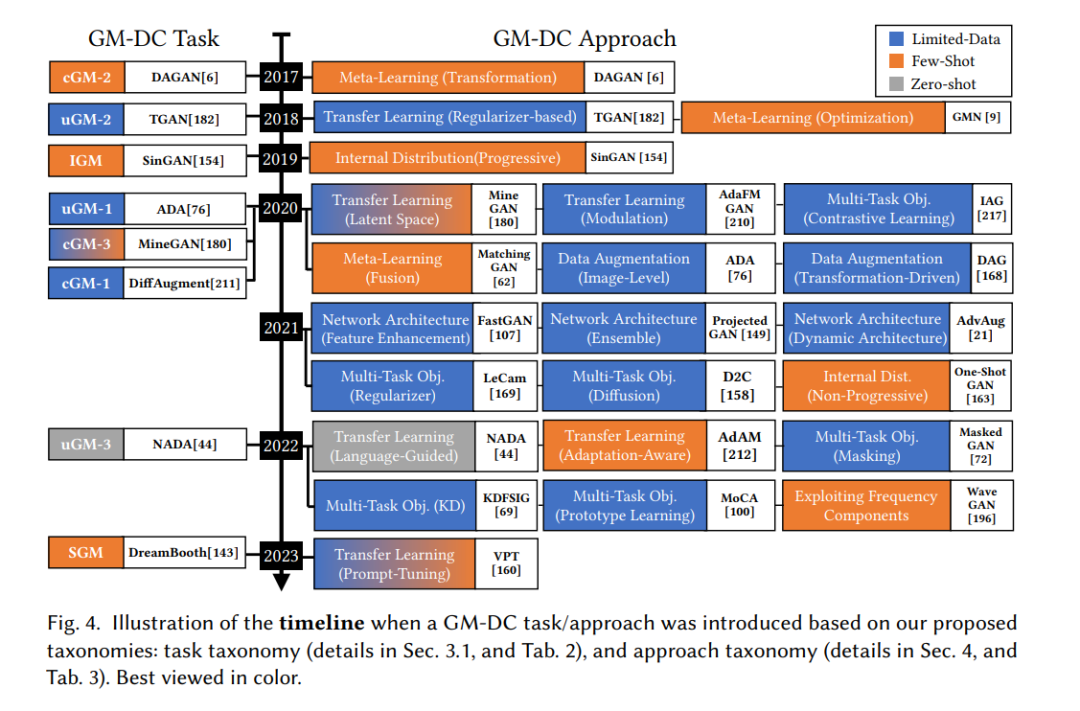
生成建模是机器学习的一个领域,专注于学习训练样本的底层分布,从而能够生成与训练数据在统计属性上相似的新样本。生成建模在多个领域都产生了深远的影响,包括计算机视觉[12, 78, 134]、自然语言处理[52, 171, 202]和数据工程[6, 76, 168]。多年来,生成建模取得了显著的进展。诸如生成对抗网络(GANs)[7, 12, 22, 48, 77, 125, 223]、变分自动编码器(VAEs)[83, 170, 171]和扩散模型(DMs)[32, 118, 140, 161]这样的创新方法在提高生成样本的质量和多样性上起到了核心作用。生成建模的进步推动了生成AI的最近的变革,为各种应用如图像合成[24, 136]、文本生成[56, 66]、音乐创作[37, 190]、基因组学[115]等解锁了新的可能性,还有更多其他应用[86, 148]。生成真实和多样的样本的能力为创意应用和新奇解决方案打开了大门[137, 142]。对生成建模的研究主要集中在拥有大型训练数据集的设置上。StyleGAN [77] 使用Flickr-Faces-HQ (FFHQ) 学习生成逼真和多样的人脸图像,FFHQ是一个从图片分享网站Flickr上收集的高质量的7万张人脸图片的数据集。更近期的文本到图像生成模型是基于数百万的图像-文本对进行训练的,例如,潜在扩散模型[140]是在拥有4亿样本的LAION-400M上训练的[152]。但是,在许多领域(例如,医学),收集数据样本是具有挑战性且昂贵的。在本文中,我们调查在数据约束下的生成建模 (GM-DC)。这个研究领域对于许多存在数据收集挑战的领域/应用来说是非常重要的。我们对有限数据、少量样本和零样本下的学习生成模型进行了深入的文献综述。我们的调查是第一个为GM-DC中研究的所有类型的生成模型、任务和方法提供全面概述和详细分析的,为研究景观提供了一个易于访问的指南(图1)。我们涵盖了基本的背景,提供了GM-DC的独特挑战的详细分析,讨论了当前的趋势,并介绍了GM-DC的最新进展。我们的贡献包括:i) GM-DC的趋势、技术进化和统计数据(图3; 图4; 第5.1节); ii) 对GM-DC挑战的新见解(第3.2节); iii) 两个新的、详细的分类法,一个是关于GM-DC任务(第3.1节),另一个是关于GM-DC方法(第4节); iv) 一个新的桑基图,用于可视化研究景观以及GM-DC任务、方法和方法之间的关系(图1); v) 对单个GM-DC作品的有组织的总结(第4节); vi) 对未来方向的讨论(第5.2节)。我们还提供了一个项目网站,其中包含一个交互式图表,用于可视化GM-DC的景观。我们的调查旨在为当前的研究景观提供新的视角,为综合文献提供有组织的指针,并对GM-DC的最新进展提供有见地的趋势。对于GM-DC的调查是不足的,我们的工作旨在填补这一空白。我们在arXiv上只找到了一篇关于GM-DC早期工作的调查,重点是GM-DC的某些方面[105]。这篇之前的调查集中在一部分GM-DC的论文上,只研究了以GANs为生成模型和一部分技术任务/方法的工作。我们的调查与[105]的差异在于:i) 范围 - 我们的调查是第一个涵盖所有类型的生成模型以及所有GM-DC任务和方法的调查(图3); ii) 规模 - 我们的研究包括了113篇论文,并广泛涵盖了GM-DC的工作,而之前的调查[105]只涵盖了我们调查中讨论的工作的≈27%(图2); iii) 时效性 - 我们的调查收集并调查了GM-DC中最新的论文; iv) 详细性 - 我们的论文包括详细的可视化(桑基图、图表)和表格,以突出显示GM-DC文献的交互和重要属性; v) 技术进化分析 - 我们的论文分析了GM-DC任务和方法的进化,为最近的进展提供了新的视角; vi) 视野分析 - 我们的论文讨论了在GM-DC中遇到的独特障碍,并确定了未来研究的方向。本文的其余部分组织如下。在第2节,我们提供了必要的背景。在第3节,我们讨论GM-DC的任务和独特的挑战。在第4节,我们分析了GM-DC的方法和手段。在第5节,我们讨论开放的研究问题和未来的方向。第6节总结了这次调查。
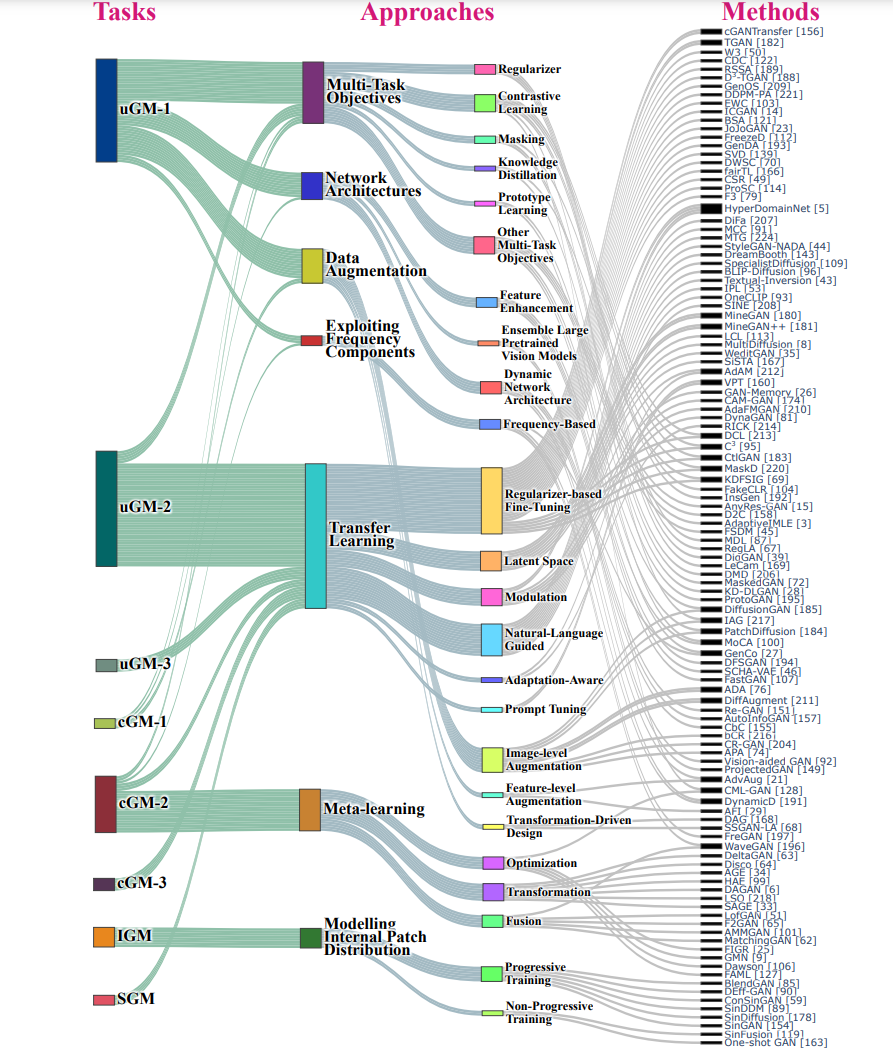
图1. GM-DC的研究景观。该图展示了GM-DC任务与方法(主要和子类别)以及GM-DC方法之间的互动。任务在我们提议的分类法中的表2中定义,方法在我们提议的分类法中的表3中定义。该图的互动版本可以在我们的项目网站上查看。最好以彩色并放大查看
在数据约束下的生成建模:任务分类、挑战
在本节中,首先,我们介绍了我们提出的关于不同GM-DC任务的分类方法(第3.1节),基于它们的属性(例如,无条件或有条件的生成)来强调它们之间的关系和差异。接着,我们介绍了GM-DC的独特挑战(第3.2节),包括像领域接近度和不兼容的知识转移等新的见解。后面,在第4节,我们介绍了我们提出的关于GM-DC方法的分类,其中详细回顾了按照我们提出的分类法组织的各个工作。
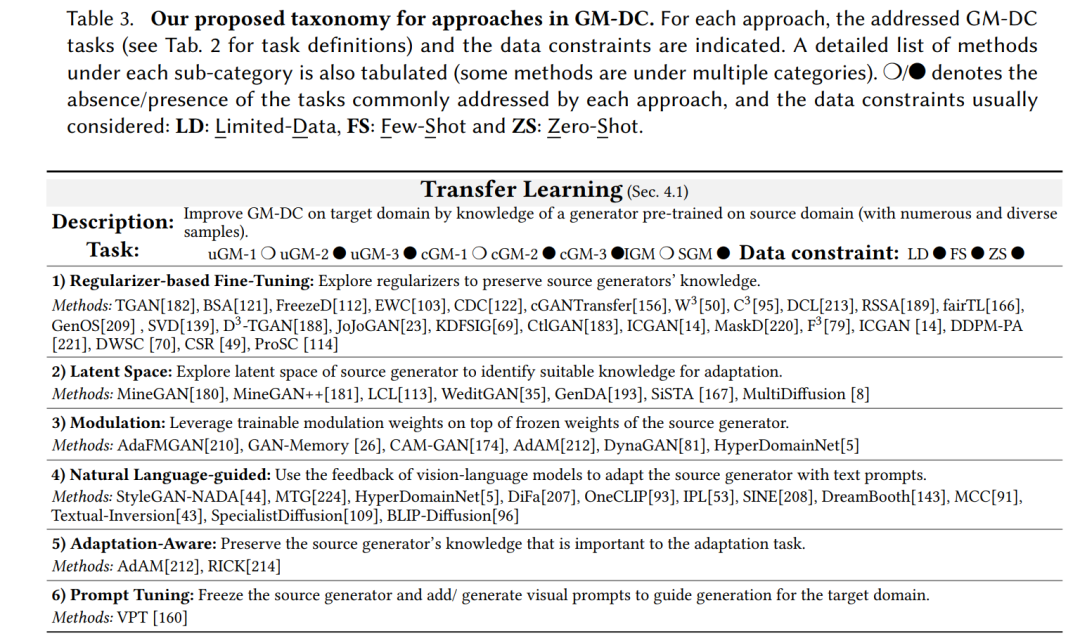

在这一节中,首先,我们将展示我们为GM-DC提出的方法分类法。这种分类法系统地将GM-DC方法根据这些方法的主要思想分为七种方法(表3)。然后,我们将讨论在我们提出的分类法下组织的各种GM-DC方法。 我们为GM-DC提出的方法分类法将GM-DC方法分为七组: (1)迁移学习:在GM-DC中,迁移学习的目的是使用在源域(拥有众多和多样的样本)上预先训练过的生成器的知识,来改善目标域生成器的学习效果。例如,此类别下的一些方法使用StyleGAN2在大型FFHQ[77]上的预训练知识,来改进仅使用艺术家的少量画作图像为该艺术家的脸部画作生成学习[122, 189, 213]。基于TL的GM-DC的主要挑战是确定、选择并保留源生成器对目标生成器有用的知识。在这一点上,有六个子类别:i) 基于正则化的微调,探索正则化来保留适当的源生成器知识以改进目标生成器的学习;ii) 隐空间,探索源生成器隐空间的转换/操作;iii) 调制,将源生成器的权重冻结并传输给目标生成器,并在冻结权重之上添加可训练的调制权重,以增加对目标域的适应能力;iv) 自然语言引导,使用自然语言提示和语言-视觉模型的监督信号来适应源生成器到目标域;v) 适应性意识,确定并保留对适应任务有重要意义的源生成器知识;vi) 提示调整,这是一个新兴的思想,它冻结源生成器的权重,并学习生成视觉提示(令牌)来引导目标域的生成。
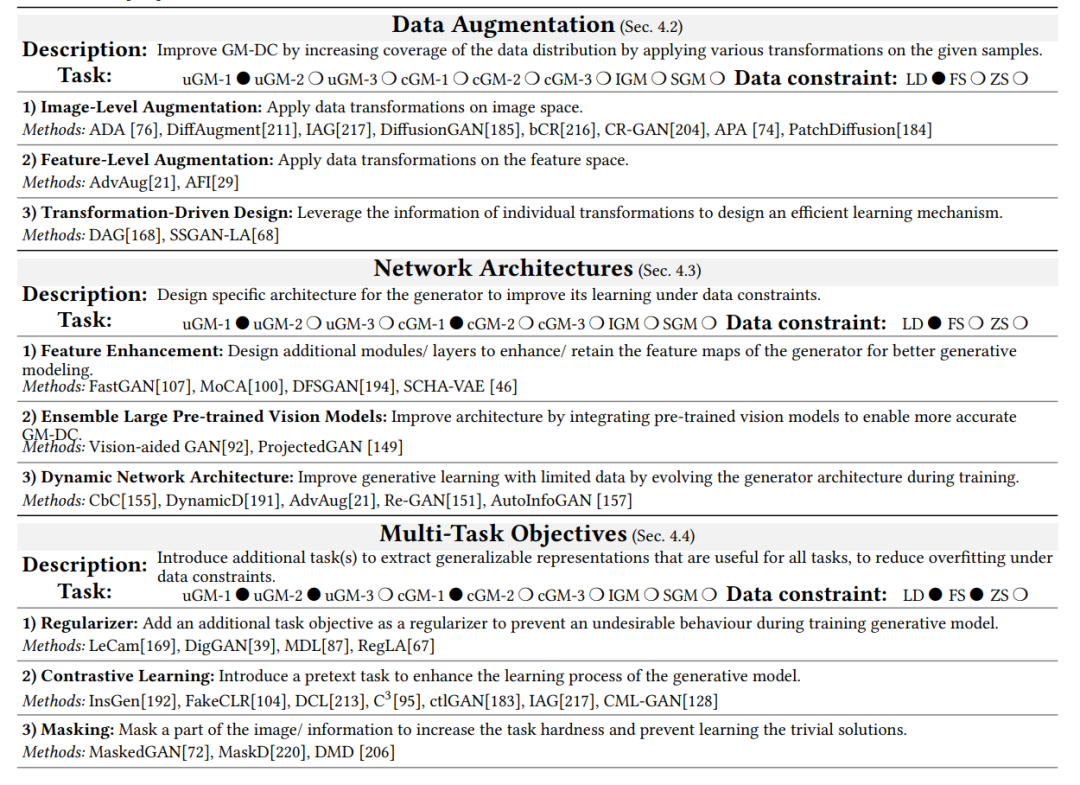
(2)数据增强:增强的目的是通过对可用数据应用各种变换{𝑇𝑘 } 𝐾 𝑘=1来增加数据分布的覆盖面,从而改善GM-DC。例如,在此类别内,一些作品对可用的有限数据进行增强,使用100张Obama数据集训练一个无条件的StyleGAN2[78],或者仅使用CIFAR-100数据集的10%训练一个有条件的BigGAN[12]。这些方法的主要挑战是增强泄露,其中生成器学习了增强的分布,例如,生成旋转/噪音样本。有三个代表性的类别:i) 图像级增强,在图像空间上应用变换;ii) 特征级增强,在特征空间上应用变换;iii) 变换驱动设计,利用每个单独变换𝑇𝑘的信息为高效的学习机制。
(3) 网络架构:这些方法为生成器设计特定的架构,以在数据受限情况下提高其学习效果。此类别中的一些工作设计了浅层/稀疏的生成器,以防止由于过度参数化而对训练数据过度拟合。设计新架构时的主要挑战是,发现最优超参数的过程可能是费力的。对于GM-DC,有三种主要的架构设计:i) 特征增强,引入附加模块以增强/保留特征图中的知识;ii) 集成大型预训练视觉模型,利用大型预训练的视觉模型来帮助更准确的生成建模;iii) 动态网络架构,在训练过程中发展生成模型的架构,以补偿数据受限。
(4) 多任务目标:这些方法通过引入额外的任务来修改生成模型的学习目标,以提取泛化表示并在数据受限情况下减少过度拟合。例如,一些工作基于对比学习[54]定义了一个前景任务,除了原始的生成学习任务,还可以拉近正样本并推远负样本,以防止在有限的可用数据下过度拟合。在数据受限情况下,新目标与生成学习目标的有效整合可能具有挑战性。这些工作可以被归类为几种方法:i) 正则化器,增加一个额外的学习目标作为正则化器,在数据受限时防止生成模型训练过程中的不良行为。注意,此类别与基于正则化的微调不同,后者旨在保留源知识,而前者是在没有源生成器的情况下进行训练;ii) 对比学习,增加与前景任务相关的学习目标,使用解决此前景任务的额外监督信号来增强生成模型的学习过程;iii) 遮蔽,通过遮蔽图像/信息的一部分引入替代学习目标,以提高生成建模,增加任务难度并防止学习琐碎的解决方案;iv) 知识蒸馏,引入一个额外的学习目标,使生成器遵循一个强大的老师;v) 原型学习,强调学习分布中样本/概念的原型作为一个额外的目标;vi) 其他多任务目标,包括共同训练、块级学习和使用扩散来增强生成。
(5) 利用频率成分:深度生成模型显示出频率偏见,倾向于忽略高频信号,因为它们很难生成[153]。数据受限可能会加剧这个问题[197]。此类别中的方法旨在通过在训练过程中利用频率组件来提高生成模型的频率意识。例如,某些方法采用Haar小波变换从样本中提取高频组件。然后,这些频率组件通过跳过连接输入到各种层,以减轻与生成高频细节相关的挑战。尽管这种方法有效,但对于GM-DC使用频率组件还没有被彻底研究。通过合并更先进的提取频率组件的技术,可以增强性能。
(6) 元学习:这些方法为看到的类创建带有数据约束的样本生成任务,并在元训练期间跨这些任务学习元知识——所有任务共享的知识。然后,这些元知识被用于改善具有数据约束的未见类的生成建模。例如,一些研究作为元知识,学习融合花卉数据集[120]的看到类别𝐶𝑠𝑒𝑒𝑛的样本进行样本生成。这种元知识使模型能够从未见类𝐶𝑢𝑛𝑠𝑒𝑒𝑛生成新样本,只需融合每个类的3个样本。注意,由于这些作品在生成框架内采用了情景学习,训练稳定性可能受到影响。沿这条线提出的方法可以归类为三个类别:i) 优化,使用在看到的类上学到的权重初始化生成模型作为元知识,以便快速适应只有有限步骤优化的未见类;ii) 转换,从看到的类的样本中学习跨类别转换作为元知识,并将它们应用于未见类的可用样本以生成新样本;iii) 融合,学习融合看到的类的样本作为元知识,并将学到的元知识应用于通过融合未见类的样本进行样本生成。
(7) 建模内部块分布:这些方法旨在学习一个图像(在某些情况下是几个图像)内部的块分布,然后生成具有任意大小和纵横比的多样本,这些样本具有相同的视觉内容(块分布)。例如,一些作品使用单个图像训练扩散模型,如“滨海湾金沙”,训练后,扩散模型可以生成类似的图像,但包括顶部相似的“金沙天空公园”的附加塔楼。然而,这些方法的主要限制在于,对于每一张单独的图像,通常都要从头开始训练一个单独的生成模型,忽略了在这种情境下知识转移的有效训练潜力。沿这一线提出的方法可以归类为两个主要群体:i) 渐进训练,逐步训练生成模型,以在不同的尺度或噪声水平上学习块分布;ii) 非渐进训练,通过实施额外的采样技术或新模型架构在单一尺度上学习生成模型。

