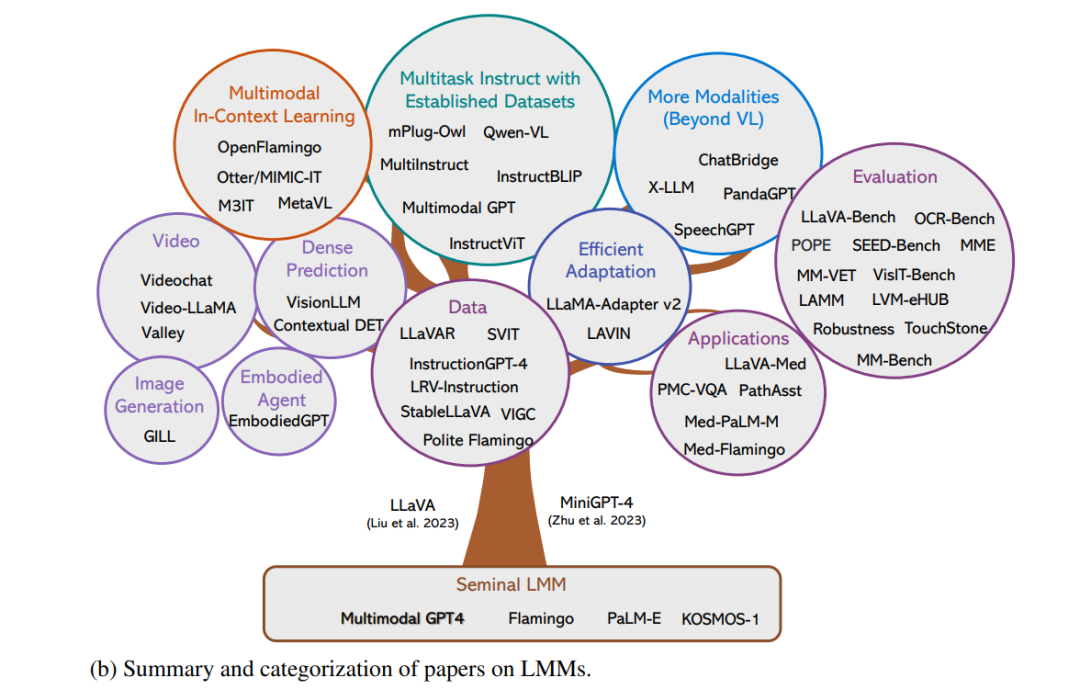
本文提供了对多模态基础模型的分类和演变的全面综述,这些模型展示了视觉和视觉-语言能力,重点关注从专家模型到通用助手的转变。研究范围涵盖了五个核心主题,分为两类。(i) 我们从对既定研究领域的调查开始:为特定目的预训练的多模态基础模型,包括两个主题 - 学习视觉基础架构的方法,用于视觉理解和文本到图像生成。(ii) 然后,我们介绍了探索性、开放性研究领域的最新进展:旨在担任通用助手角色的多模态基础模型,包括三个主题 - 由大型语言模型(LLMs)启发的统一视觉模型,多模态LLMs的端到端训练,以及将多模态工具与LLMs链接。本文的目标读者是计算机视觉和视觉-语言多模态社区的研究人员、研究生和专业人士,他们渴望了解多模态基础模型的基础知识和最新进展。

视觉是人类和许多生物感知和与世界互动的主要渠道之一。人工智能(AI)的核心愿望之一是开发能够模仿这种能力的AI智能体,以有效地感知和生成视觉信号,从而推理和与视觉世界互动。例如,识别场景中的对象和动作,以及为交流创建素描和图片。建立具有视觉能力的基础模型是一个旨在实现此目标的普遍研究领域。
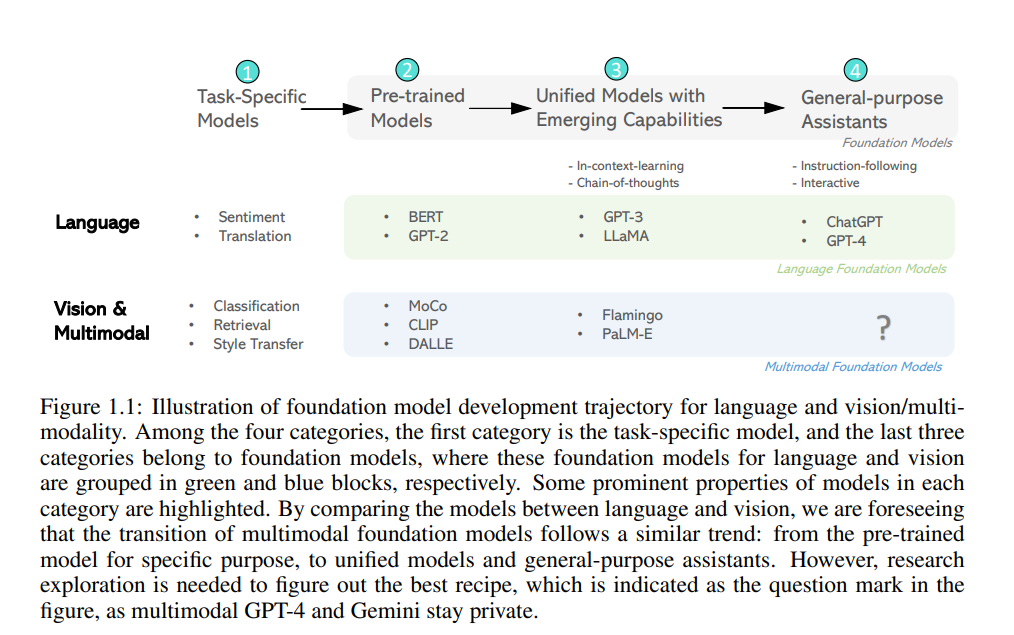
在过去的十年中,AI领域在模型的开发中经历了丰硕的轨迹。我们将它们分为图1.1所示的四个类别。这个分类可以在AI的不同领域中共享,包括语言、视觉和多模态。我们首先使用自然语言处理中的语言模型来说明演变过程。(i)在早期,为各个数据集和任务开发了特定任务的模型,通常是从头开始训练的。(ii)通过大规模的预训练,语言模型在许多已建立的语言理解和生成任务上实现了最先进的性能,例如BERT(Devlin等,2019)、RoBERTa(Liu等,2019)、T5(Raffel等,2020)、DeBERTa(He等,2021)和GPT-2(Radford等,2019)。这些预训练的模型为下游任务适应提供了基础。(iii)由GPT-3(Brown等,2020)举例,大型语言模型(LLMs)将各种语言理解和生成任务统一到一个模型中。随着网络规模的训练和统一,出现了一些新的能力,如上下文学习和思维链。(iv)伴随着人工智能对齐的最新进展,LLMs开始扮演通用助手的角色,遵循人类的意图,完成广泛的语言任务,例如ChatGPT(OpenAI,2022)和GPT-4(OpenAI,2023a)。这些助手展示了有趣的能力,如交互和工具使用,并为开发通用AI智能体奠定了基础。重要的是要注意,最新一代的基础模型在提供额外功能的同时,也借鉴了其早期版本的显著特性。
**受到NLP中LLMs的巨大成功的启发,计算机视觉和视觉-语言社区的研究人员自然会问:ChatGPT/GPT-4在视觉、视觉-语言和多模态模型方面的对等物是什么?**毫无疑问,自从BERT诞生以来,视觉预训练和视觉-语言预训练(VLP)越来越受到关注,并已成为视觉的主流学习范式,承诺学习通用的可迁移的视觉和视觉-语言表示,或生成高度可能的图像。可以说,它们可以被视为多模态基础模型的早期生成,就像BERT/GPT-2对语言领域一样。虽然建立像ChatGPT这样的语言通用助手的路线图很清晰,但研究社区越来越需要探索建立计算机视觉的对等物:通用视觉助手的可行解决方案。总的来说,建立通用智能体一直是AI的长期目标。具有新兴属性的LLMs已显著降低了为语言任务建立此类智能体的成本。同样,我们预见到视觉模型将展现出新的能力,例如遵循由各种视觉提示组成的指令,如用户上传的图像、人类绘制的点击、素描和遮罩,除了文本提示。这样强大的零样本视觉任务组成能力可以显著降低建立AI智能体的成本。
在这篇文章中,我们将多模态基础模型的范围限制在视觉和视觉-语言领域。相关主题的最新综述论文包括:(i) 图像理解模型,如自监督学习(Jaiswal等,2020;Jing和Tian,2020;Ozbulak等,2023),切分任何东西(SAM)(Zhang等,2023a,c);(ii) 图像生成模型(Zhang等,2023b;Zhou和Shimada,2023);以及(iii) 视觉-语言预训练(VLP)。现有的VLP综述论文涵盖了在预训练时代之前,针对特定VL问题的VLP方法,图像-文本任务,核心视觉任务,和/或视频-文本任务(Zhang等,2020;Du等,2022;Li等,2022c;Ruan和Jin,2022;Chen等,2022a;Gan等,2022;Zhang等,2023g)。两篇最新的综述论文讨论了视觉模型与LLM的集成(Awais等,2023;Yin等,2022)。
其中,Gan等(2022)是一篇关于VLP的综述,涵盖了2022年及之前的CVPR关于视觉和语言研究的最新进展系列教程。本文总结了2023年CVPR关于视觉基础模型最新进展的教程。与前述主要侧重于给定研究主题的文献回顾的综述论文不同,本文提出了我们对多模态基础模型从专家到大型语言模型时代的通用视觉助手的角色转变的观点。本综述论文的贡献总结如下。
•** 我们提供了一篇全面且及时的现代多模态基础模型的综述**,不仅涵盖了视觉表示学习和图像生成的成熟模型,还总结了过去6个月由LLM启发的新兴主题,包括统一视觉模型,与LLM的训练和链接。 • 本文旨在为观众提供一种观点,推崇在开发多模态基础模型中的一种转变。在特定视觉问题的伟大建模成功的基础上,我们正朝着构建能够按照人类意图完成广泛计算机视觉任务的通用助手迈进。我们对这些高级主题进行了深入讨论,展示了开发通用视觉助手的潜力。
1.1 什么是多模态基础模型?
正如Stanford基础模型论文(Bommasani等,2021)所阐述的,AI正随着诸如BERT、GPT家族、CLIP(Radford等,2021)和DALL-E(Ramesh等,2021a)这些模型的兴起而经历一场范式转变,这些模型经过广泛的数据训练,可以适应各种下游任务。他们将这些模型称为基础模型,以强调它们在核心上的关键性但不完整的特性:研究社区的方法论的同质化和新能力的出现。从技术角度来看,使基础模型成为可能的是迁移学习,使它们变得强大的是规模。基础模型的出现主要观察到在NLP领域,范例包括从BERT到ChatGPT。这一趋势在近年来获得了推动,扩展到计算机视觉和其他领域。在NLP中,BERT在2018年底的推出被视为基础模型时代的开始。BERT的显著成功迅速激发了计算机视觉社区对自监督学习的兴趣,催生了如SimCLR(Chen等,2020a)、MoCo(He等,2020)、BEiT(Bao等,2022)和MAE(He等,2022a)等模型。在同一时期,预训练的成功也显著推动了视觉-语言多模态领域达到了前所未有的关注度。
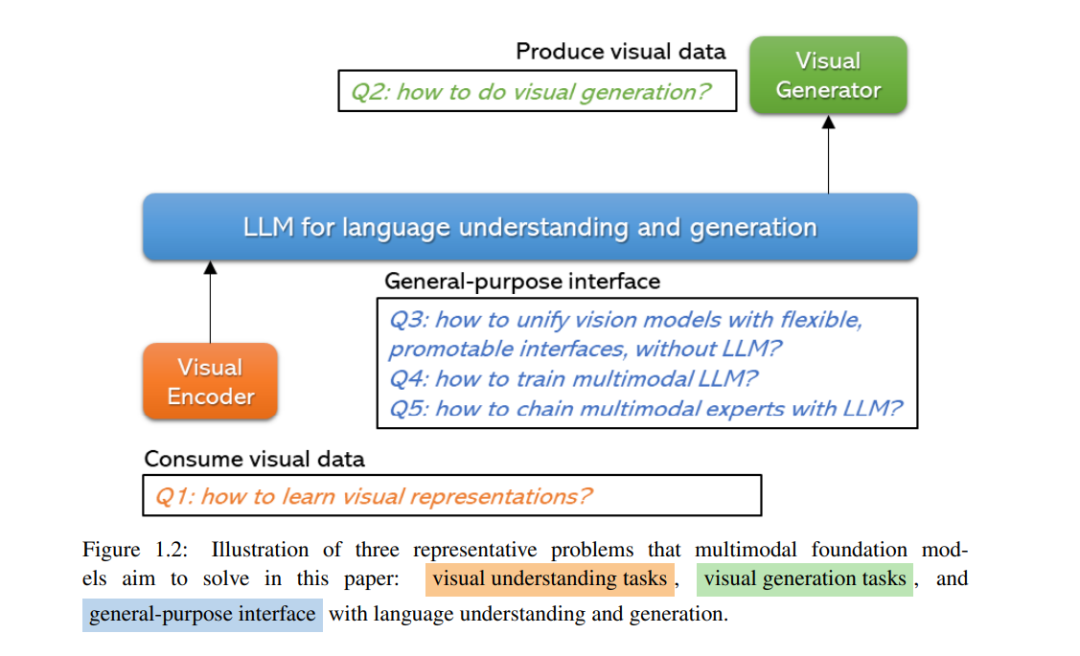
在本文中,我们关注的是多模态基础模型,这些模型继承了Stanford论文(Bommasani等,2021)中讨论的所有基础模型的属性,但侧重于具有处理视觉和视觉-语言模态能力的模型。在不断增长的文献中,我们基于功能和通用性对多模态基础模型进行分类,见图1.2。对于每个类别,我们都展示了一些示例模型,展示了这些多模态基础模型固有的主要能力。
视觉理解模型(在图1.2中用橙色突出显示)
学习通用视觉表示对于构建视觉基础模型至关重要,因为预训练一个强大的视觉主干对所有类型的计算机视觉下游任务都是基础,这些任务范围从图像级别(例如,图像分类、检索和字幕)、区域级别(例如,检测和定位)到像素级别任务(例如,分割)。我们将方法分为三类,取决于用于训练模型的监督信号类型:
-
标签监督。像ImageNet(Krizhevsky等,2012)和ImageNet21K(Ridnik等,2021)这样的数据集一直受到监督学习的欢迎,更大规模的专有数据集也在工业实验室中使用(Sun等,2017;Singh等,2022b;Zhai等,2022a)。
-
语言监督。语言是一种更丰富的监督形式。像CLIP(Radford等,2021)和ALIGN(Jia等,2021)这样的模型使用来自网络的数百万甚至数十亿噪声图像-文本对上的对比损失进行预训练。这些模型使得零射击图像分类成为可能,并使传统的计算机视觉(CV)模型执行开放词汇CV任务。我们提倡在野外进行计算机视觉的概念,并鼓励未来基础模型的开发和评估。
-
仅图像自监督。这一工作方向旨在从图像本身中挖掘出监督信号来学习图像表示,范围从对比学习(Chen等,2020a;He等,2020)、非对比学习(Grill等,2020;Chen和He,2021;Caron等,2021)到遮蔽图像建模(Bao等,2022;He等,2022a)。
-
多模态融合,区域级和像素级预训练。除了预训练图像主干的方法外,我们还将讨论允许多模态融合的预训练方法,例如CoCa(Yu等,2022a)、Flamingo(Alayrac等,2022),区域级和像素级图像理解,例如开放集对象检测(例如,GLIP(Li等,2022e))和可提示分割(例如,SAM(Kirillov等,2023))。这些方法通常依赖于预训练的图像编码器或预训练的图像-文本编码器对。
视觉生成模型(在图1.2中用绿色突出显示)
最近,由于大规模图像-文本数据的出现,已经构建了基础图像生成模型。使之成为可能的技术包括向量量化VAE方法(Razavi等,2019)、基于扩散的模型(Dhariwal和Nichol,2021)和自回归模型。
-
基于文本的视觉生成。这个研究领域关注的是生成忠实的视觉内容,包括图像、视频等,这些内容是以开放式文本描述/提示为条件的。文本到图像生成发展了生成模型,这些模型合成了忠实于文本提示的高保真度图像。主要例子包括DALL-E(Ramesh等,2021a)、DALL-E 2(Ramesh等,2022)、Stable Diffusion(Rombach等,2021;sta,2022)、Imagen(Saharia等,2022)和Parti(Yu等,2022b)。基于文本到图像生成模型的成功,文本到视频生成模型基于文本提示生成视频,例如Imagen Video(Ho等,2022)和Make-A-Video(Singer等,2022)。
-
与人类意图一致的视觉生成器。这个研究领域关注的是改善预训练的视觉生成器,以更好地遵循人类意图。为解决基础视觉生成器固有的各种挑战,已经进行了努力。这些包括改善空间可控性(Zhang和Agrawala,2023;Yang等,2023b)、确保更好地遵循文本提示(Black等,2023)、支持灵活的基于文本的编辑(Brooks等
1.2 定义和从专业模型到通用助手的过渡
根据自然语言处理(NLP)中的模型发展历史和分类,我们将图1.2中的多模态基础模型分为两类。• 特定目的的预训练视觉模型涵盖了大多数现有的多模态基础模型,包括视觉理解模型(例如,CLIP(Radford等,2021),SimCLR(Chen等,2020a),BEiT(Bao等,2022),SAM(Kirillov等,2023))和视觉生成模型(例如,Stable Diffusion(Rombach等,2021;sta,2022)),因为它们具有针对特定视觉问题的强大可迁移能力。• 通用助手指的是能够遵循人类意图以完成野外各种计算机视觉任务的AI代理。通用助手的含义有两层面:(i)具有统一架构的通用型,可以完成不同类型问题的任务;以及(ii)容易遵循人类指令,而不是替代人类。为此,已经积极探讨了一些研究课题,包括统一视觉建模(Lu等,2022a;Zhang等,2022b;Zou等,2023a),与大型语言模型(LLMs)的训练和链接(Liu等,2023c;Zhu等,2023a;Wu等,2023a;Yang*等,2023)。
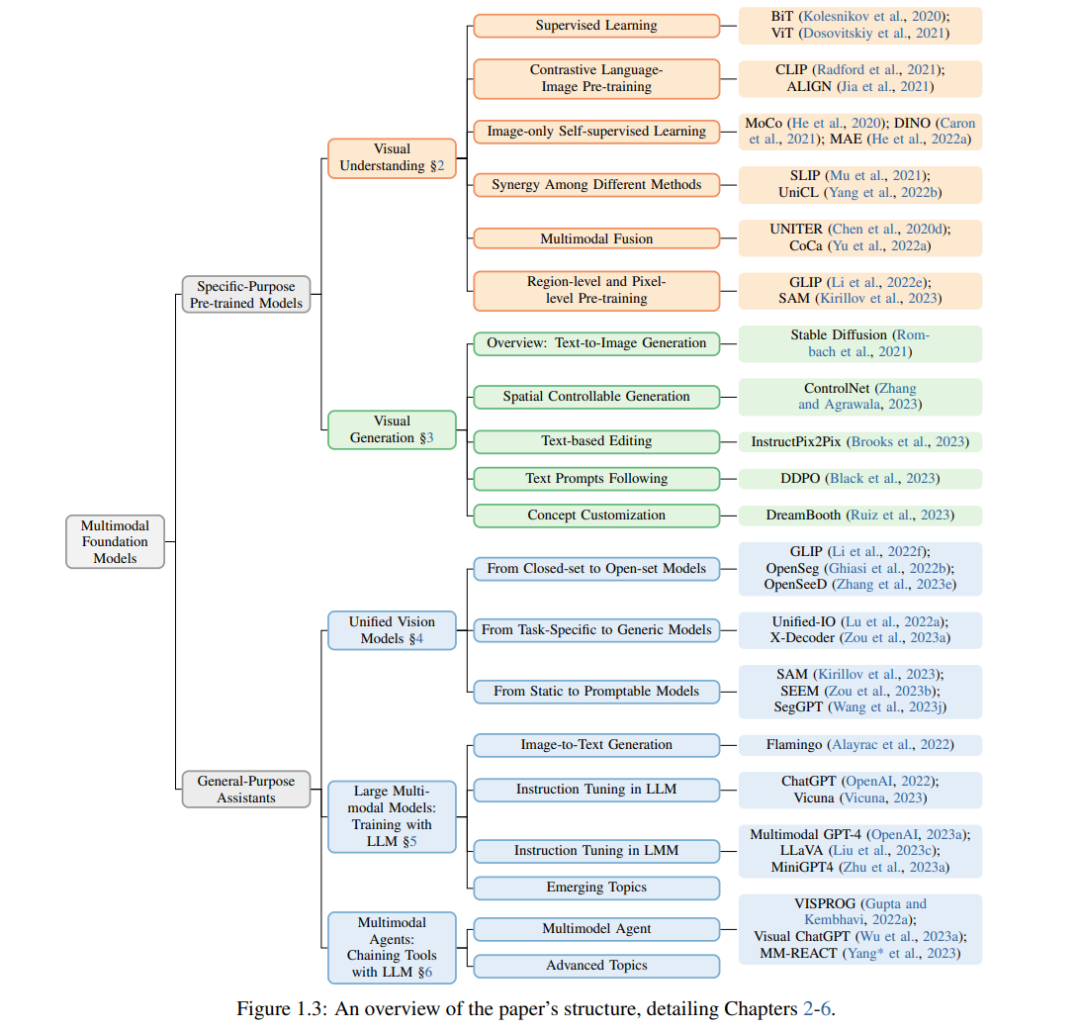
• 第1章介绍了多模态基础模型研究的领域,并展示了从专家模型到通用助手的研究历史转变。• 第2章介绍了不同消耗视觉数据的方式,重点关注如何学习一个强大的图像骨干。• 第3章描述了如何生成与人类意图一致的视觉数据。• 第4章描述了如何设计统一的视觉模型,具有交互式和可提示的界面,特别是在没有使用LLMs的情况下。• 第5章描述了如何以端到端的方式训练LLM,以处理视觉输入进行理解和推理。• 第6章描述了如何将多模态工具与LLM链接,以实现新的功能。• 第7章总结了本文并讨论了研究趋势。
第2至6章是本综述论文的核心章节。这些章节的结构概述如图1.2所示。我们首先讨论了两种特定任务的典型多模态基础模型,包括第2章中的视觉理解和第3章中的视觉生成。由于多模态基础模型最初是基于图像骨干/表示学习用于理解任务的,因此我们首先对图像骨干学习方法的过渡进行了全面回顾,从早期的监督方法发展到最近的语言-图像对比方法,并将讨论扩展到从图像级别到区域级别和像素级别的图像表示(第2章)。最近,生成型AI越来越受欢迎,视觉生成基础模型已经得到了发展。在第3章中,我们讨论了大规模预训练的文本到图像模型,以及社区如何利用生成基础模型开发新技术,使它们更好地与人类意图一致。受到自然语言处理领域最新进展的启发,LLMs在日常生活中为各种语言任务提供通用助手,计算机视觉社区一直在期望并尝试构建通用的视觉助手。我们讨论了构建通用助手的三种不同方法。受到LLMs的精神启发,第4章着重于统一不同的视觉理解和生成模型,而无需在建模中明确纳入LLMs。相比之下,第5章和第6章侧重于采用LLMs构建通用视觉助手,通过在建模中明确增加LLMs来实现。具体来说,第5章描述了端到端训练方法,第6章专注于无需训练的方法,将各种视觉模型链接到LLMs。