
大模型如何做知识更新?这篇文章全面综述

尽管大型语言模型(LLMs)在解决各种任务上表现出色,但它们在部署后很快就可能会过时。在当前时代,保持它们的最新状态是一个迫切的关注点。本文提供了对最近在不从头开始重新训练的情况下,将LLMs与不断变化的世界知识对齐的进展的全面回顾。我们系统地对研究工作进行分类,并提供深入的比较和讨论。我们还讨论了现存的挑战,并强调了未来的研究方向,以促进这一领域的研究。
https://www.zhuanzhi.ai/paper/895473a03ca23c3b2ff748c92eae7551
大型语言模型(LLMs)(Brown 等人,2020;Ouyang 等人,2022;Chowdhery 等人,2022;Zhang 等人,2022;OpenAI, 2023b;Touvron 等人,2023;Anil 等人,2023)经过在各种来源(例如,维基百科,书籍,Github)的大量语料库上的训练,在其参数中隐式地存储了大量的世界知识(Petroni 等人,2019;Roberts 等人,2020;Jiang 等人,2020),使它们能够作为多功能的基础模型,直接通过情境学习(Liu 等人,2023b;OpenAI, 2023b;Bubeck 等人,2023;Kamalloo 等人,2023)来执行各种自然语言处理(NLP)任务,或进一步为特定领域的用途进行微调(Singhal 等人,2022;Google, 2023;Liu 和 Low, 2023)。
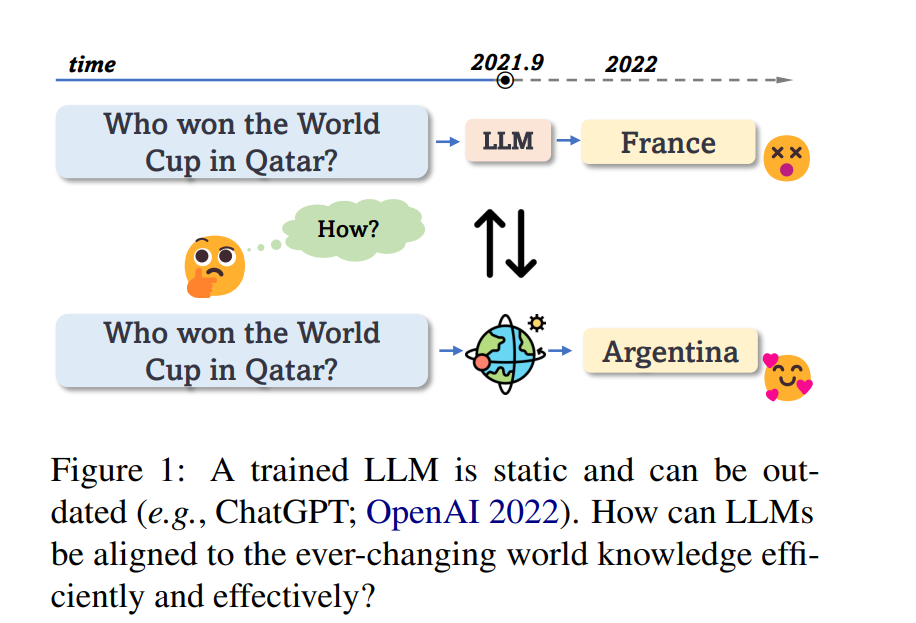
尽管它们的表现令人印象深刻,但LLMs在部署后是静态的,没有更新自己或适应变化环境的机制(Kasai 等人,2022;Bubeck 等人,2023)。然而,我们的世界是动态的并且不断发展。如图1所示,经过训练的LLMs的静态特性使存储的知识迅速过时,这经常导致幻觉,使它们对知识密集型任务不可靠(Lazaridou 等人,2022;Luu 等人,2022;Ji 等人,2023;Si 等人,2023)。在LLMs的时代,确保它们与不断变化的世界知识保持一致,并在部署后保持其最新状态是一个迫切的问题,因为许多用户和下游应用依赖它们。不幸的是,由于禁止性的成本(Patterson 等人,2021),仅仅使用最新信息重新训练LLMs是不可行的。 从直觉上讲,要更新LLM,可以通过修改其参数用新的知识替换模型中隐式存储的过时知识,或使用从世界上明确检索的新信息覆盖过时的模型输出。文献中已经提出了大量的工作,隐式或显式地刷新部署的LLMs;但是,这些方法在各种任务中散布,并没有被系统地回顾和分析。
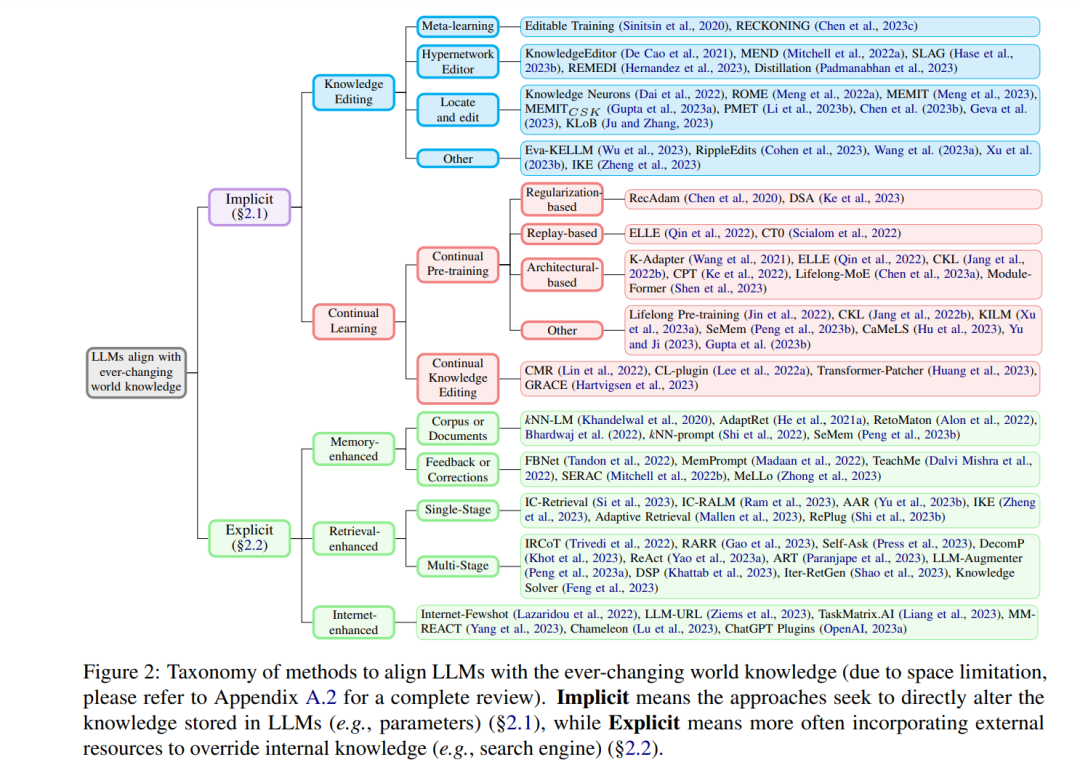
在这篇综述中,我们调查了与不断变化的世界知识对齐已部署的LLMs的最新引人注目的进展。我们系统地对研究工作进行分类,并在每个类别中突出代表性的方法(§2),并为洞察提供深入的比较和讨论(§3)。最后,我们讨论了促进这一领域研究的潜在未来方向(§4)。 **方法分类 **
根据方法是否倾向于直接改变LLMs中隐式存储的知识,或利用外部资源来覆盖过时的知识,我们粗略地将它们分类为隐式方法(§2.1)或显式方法(§2.2)。图2提供了每个类别中代表性作品的摘要(详细综述请见附录中的图6)。方法的详细描述可以在附录A.1中找到。
**隐式地使LLMs与世界知识对齐 **
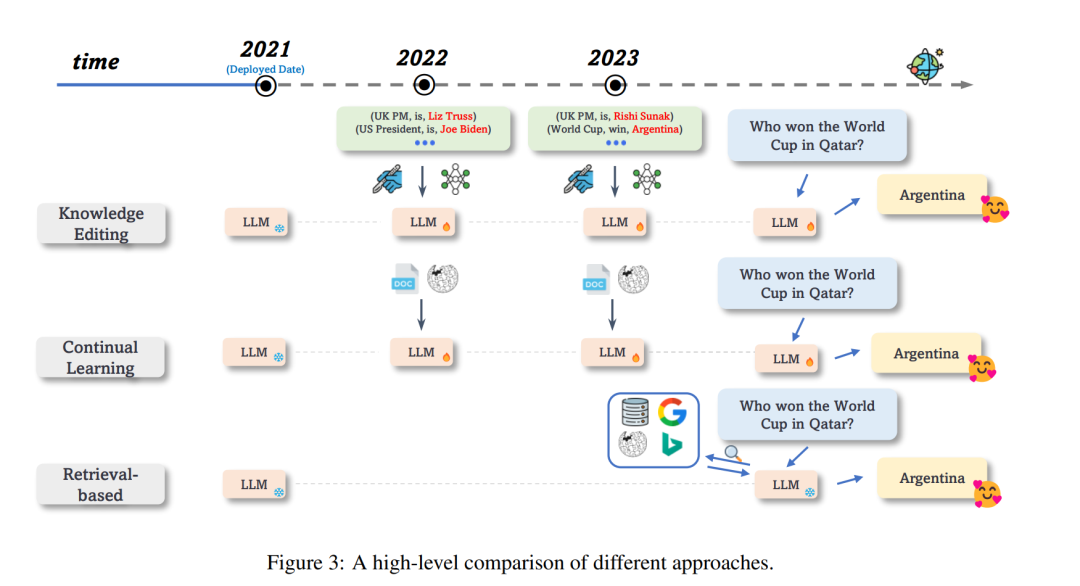
先前的研究已经表明,经过在大量语料库上预训练后,LLMs可以在其大量参数中隐式记忆知识 (Petroni 等人, 2019; Roberts 等人, 2020; Jiang 等人, 2020; Singhal 等人, 2022)。为了保持LLMs的最新状态并与当前的世界知识对齐,直接的方法是改变模型自身的行为以生成期望的输出。天真地说,可以定期从头开始重新训练模型或使用最新的语料库对模型进行微调以与当前的世界知识对齐。但是,重新训练是昂贵且对环境不友好的 (Patterson 等人, 2021),特别是在具有数十亿参数的LLMs的时代。无约束的微调可能会产生"蝴蝶效应"并影响模型中的其他知识或技能 (Kirkpatrick 等人, 2017; Li 等人, 2022; AlKhamissi 等人, 2022)。为了应对这个问题,这一系列工作旨在设计更好的策略,以更可控和高效的方式修改LLMs的内部状态,这可以分为知识编辑 (§2.1.1) 和连续学习 (§2.1.2)。
**显式地使LLMs与世界知识对齐 **
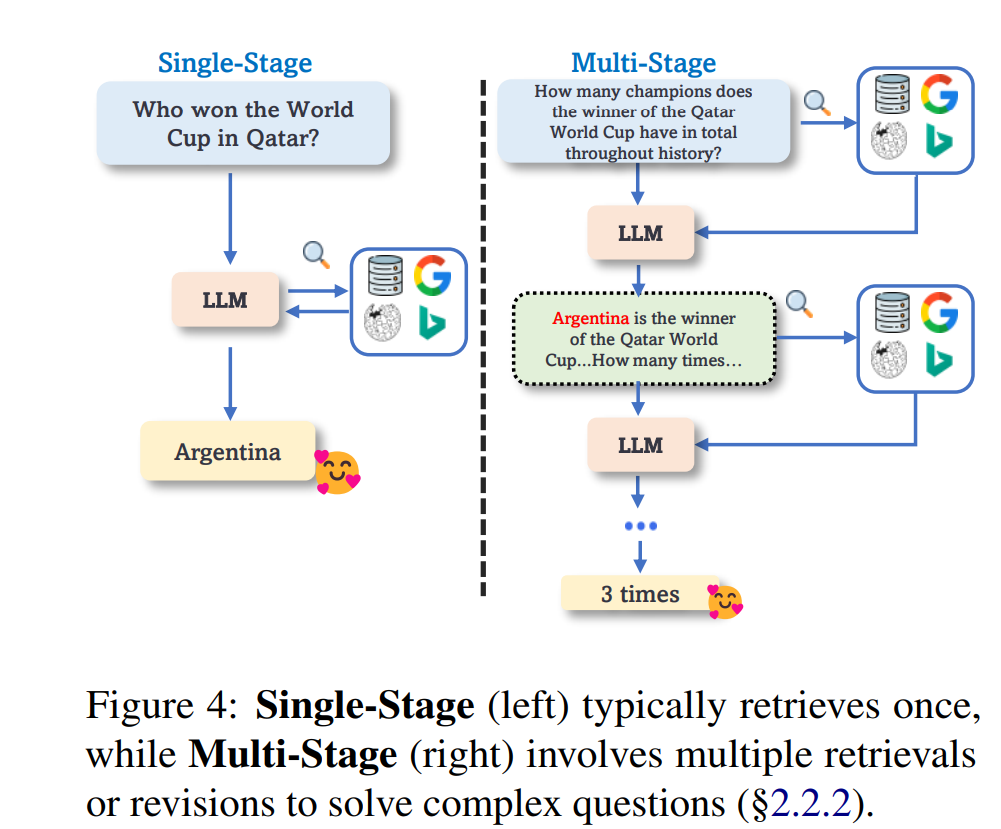
尽管改变LLMs中隐式存储的知识已被证明是有效的 (Jang等人, 2022b; Meng等人, 2023),但由于神经网络的复杂性,这是否会影响模型的一般能力仍不清楚。相比之下,显式地通过从各种来源检索的最新信息来增强LLMs可以有效地使模型适应新的世界知识,而不影响原始的LLMs (Mialon等人, 2023)。然而,之前的检索增强方法 (Karpukhin等人, 2020; Guu等人, 2020; Lewis等人, 2020; Izacard等人, 2022; Borgeaud等人, 2022; Jiang等人, 2022; Kaur等人, 2022) 通常以端到端的方式联合训练检索器和语言模型,这使得它难以应用于已部署的LLM(例如,GPT-3)。最近,研究者们关注于为固定的LLM配备外部记忆 (增强记忆;§2.2.1)、现成的检索器 (增强检索;§2.2.2) 或互联网 (增强互联网;§2.2.3) 来解决这个问题。
**挑战和未来方向 **
鲁棒高效的知识编辑
KE提供了细粒度的知识更新,在某些场景中是可取的。尽管有前景,但KE仍处于初级阶段。1 各种知识。更新LLMs参数中存储的内部知识是具有挑战性的,现有的努力只探讨了更新关系知识,而忽略了其他知识 (Meng等人, 2023);2 编辑数据集。当前的KE方法假设已存在编辑过的知识对,这些对必须提前进行注释。实际上,LLMs如何知道哪些知识已经过时,因此需要更新 (Zhang和Choi, 2023; Yin等人, 2023)?3 记忆机制。Hase等人 (2023a) 认为,通过因果追踪定位特定知识可能不可靠,需要更好地理解LLMs的内部记忆 (Tirumala等人, 2022; Carlini等人, 2023);4 通用化。最近的研究 (Onoe等人, 2023; Zhong等人, 2023) 发现,现有的KE方法在编辑知识的传播上表现不佳,这意味着LLM不能基于新获得的知识进行进一步的推理;5 有效性和效率。尽管已经进行了早期的努力 (Hernandez等人, 2023; Huang等人, 2023; Hartvigsen等人, 2023),但有效、高效、持续地更新LLMs的知识的方法尚有待深入探索。
**LLMs的高效持续学习 **一个持续预训练的LLM可以更新其内部知识并适应变化的世界,但保持下游任务所需的一般知识而不遗忘是具有挑战性的 (Ke和Liu, 2023)。此外,现有的方法仅限于小规模的LM,使得LLMs的CL很少被研究。尽管参数有效的调整 (Ding等人, 2022) 可能是有益的,但通过CL使LLM与动态世界对齐仍然没有被充分探索。
**解决知识冲突 **用新知识替代旧知识可能会导致知识冲突,无论使用隐式或显式方法。对于隐式方法,这些副作用只在特定设置中进行评估,不知道LLMs的一般技能如何受到影响 (Brown等人, 2023)。对于基于检索的方法,从世界上检索的知识可能与LLMs内部记忆的知识矛盾,LLMs有时倾向于在生成期间更多地依赖其内部知识,而不是提供的上下文 (例如在Fig.5中的一个例子; Neeman等人 2022; Li等人 2022; Chen等人 2022)。虽然已经进行了初步尝试 (Mallen等人, 2023; Zhou等人, 2023; Xie等人, 2023),但它们仍然受到限制。
**鲁棒高效的检索 **与外部资源互动可能会在生成期间引起中断,显著增加推理开销,特别是对于涉及多次检索或修订的多阶段方法。可能的补救措施是有效的内存管理 (Peng等人, 2023b; Kang等人, 2023; Cheng等人, 2023) 或选择性检索,只在必要时咨询外部资源 (Mallen等人, 2023)。另一方面,检索到的上下文可能是无关的和嘈杂的,这可能会分散LLMs的注意力 (Shi等人, 2023a; Luo等人, 2023),或者太长,超出了输入限制,并带来高昂的成本 (Shi等人, 2023b)。
**全面的评估和基准测试 **尽管不同类别的方法可以在不重新训练的情况下将训练过的LLMs与变化的世界对齐,但它们的有效性主要在特定设置的合成数据集上进行评估,这可能不是很全面 (Jang等人, 2022a,b; Hoelscher-Obermaier等人, 2023)。此外,尽管已经进行了努力来评估KE (Wu等人, 2023; Cohen等人, 2023; Ju和Zhang, 2023),但没有对不同类别的方法进行定量比较(即,比较KE vs. CL vs. 基于检索的方法),这阻碍了它们在不同场景中的应用。最后,现有的基准测试对于度量动态世界来说太静态了,这呼吁进行实时评估基准测试 (Liška等人, 2022; Kasai等人, 2022)。
**结论 **
在本文中,我们系统地回顾了在不重新训练的情况下使LLMs与不断变化的世界知识保持一致的最新进展。我们总结了现有的方法,并根据它们是倾向于直接改变LLMs中隐式存储的知识,还是利用外部资源来覆盖过时的知识进行分类。我们全面比较了不同类别的方法,并指出了这一领域研究的挑战和未来方向。
