
专题解读| 大语言模型长文本训练技术解析
1. 长文本训练的技术背景
1.1 为什么需要长文本训练?
Transformer已经成为大型语言模型(Large language models, LLMs)的主导架构,这是由于它们在理解复杂文本和生成可控响应方面的卓越能力。因此,基于Transformer的LLMs被应用于许多现实世界场景,如代码生成、对话机器人、图像生成或视觉理解。 在这些任务中,基于Transformer的模型面临着处理具有巨大上下文长度的数据的挑战,尤其是在涉及代码和图像数据的场景中。然而,作为基于Transformer的LLMs的核心组件,注意力模块在序列长度方面表现出二次时间和内存复杂度,随着序列长度的增加,在计算时间和内存开销方面都面临挑战。最近的一些工作如Llama[1] 和Gemini[2]已经将预训练阶段的序列长度扩展到32k甚至128k,具有完整的上下文窗口大小,而其他工作,如Mistral[3],则提出使用滑动窗口注意力(Sliding Window Attention, SWA), 这是一种通过设置固定窗口大小来控制每个token的注意力范围的方法,以减少预训练阶段注意力计算的二次复杂度。然而,SWA是一种有损方法,可能会降低Transformer有效处理长文本的能力。这种观察正是为什么像Llama 2和Gemini这样的工作愿意容忍精确注意力计算的二次复杂度,以在长序列场景中实现更好的性能。
1.2 长文本训练的挑战与机遇
由于Transformer中,Attention存在 的计算复杂度,长文本训练会带来显著的计算和存储压力。在传统的Attention计算步骤中,存在一个完整的(NxN)的注意力矩阵,其中N为序列长度,这意味着当序列长度增加时,注意力矩阵的内存占用会呈二次增长,这使得以往的LLM的训练长度很少超过8192个token。而Online-Softmax[4]的出现,使得长文本的Attention计算成为可能,Online-Softmax通过分块计算Attention, 从而将注意力矩阵的内存占用从降低到,其中T为分块数量。FlashAttention[5]则基于Online-Softmax的算法,提供了高效的CUDA实现,借鉴了GPU矩阵乘法中Tiling的概念,重点优化了Attention计算的访存模式,并利用了CUDA编程中Shared Memory的特性,从而实现了高效的长文本Attention计算。
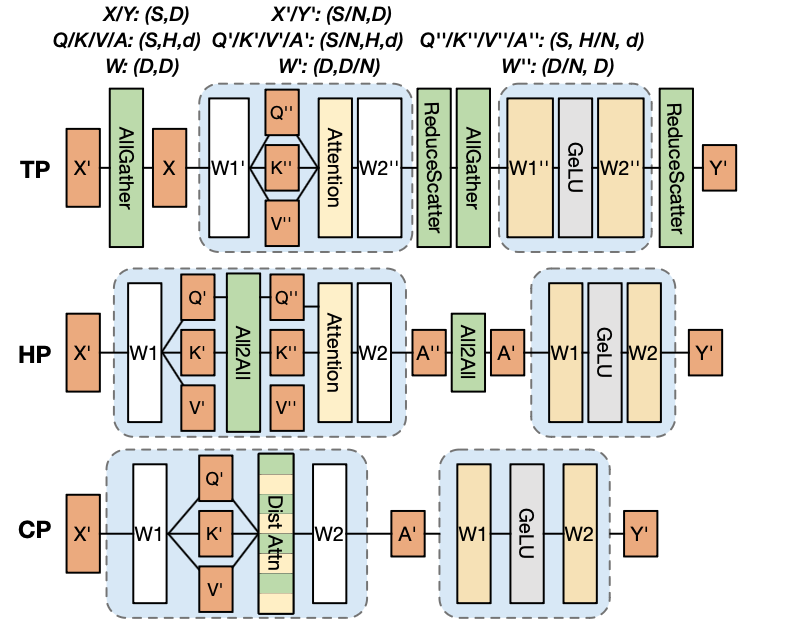
图1 基于分块优化的长文本Attention机制
2. 分布式长文本训练技术
尽管FlashAttention使得长文本训练成为可能,但是在实际应用中,32k token 对于许多LLM任务来说还是过短,为了进一步扩展长度,使用多张GPU协同完成一整段长序列的训练已经成为常态,目前常见的分布式长文本训练技术主要有三种:张量并行[6]、注意力头并行[7]和上下文并行[8]。
2.1 张量并行
张量并行通过在设备间分割两个连续的矩阵乘法来并行化计算。这种方式可以减少内存开销,因为每个设备只需存储部分权重和激活值。然而,它会产生大量通信开销,用于汇总矩阵乘法的结果,并且由于通信和计算之间存在强依赖关系,因此在通信和计算重叠能力方面比其他方法更差。 具体地,以Transformer举例,张量并行将以两种方式对线性层权重矩阵进行切分:行切分和列切分,分别对应于输入和输出的维度。首先每个设备上只有一个子序列的输入,在计算Attention的Q,K,V 全连接层映射时,对输入进行一个All-Gather操作,使得每个设备得到完整的输入,随后和做了行切分的Q, K, V线性层权重进行矩阵乘,而在Attetnion的输出层, 则对应需要进行一个ReduceScatter对结果进行累加。对于前馈网络部分,和Attention类似,第一全连接层的输入也需要进行All-Gather操作,而第二全连接层的输出则需要进行ReduceScatter操作。
2.2 注意力头并行
注意力头并行提出了另一种处理上下文并行化注意力计算阶段的方法。其执行全对全通信(all-to-all) 以在设备间交换查询、键和值隐藏状态。这确保每个设备保留完整序列长度的查询、键和值隐藏状态,但在注意力头维度上进行分区。注意力头并行在计算Attention之前,通过全对全通信(all-to-all)来交换查询、键和值隐藏状态,以确保每个设备都有完整的查询、键和值隐藏状态,但在注意力头维度上进行分区。这种方法可以减少与上下文并行和张量并行化相比的通信量,但与张量并行化一样,由于通信和计算之间也存在强依赖关系,因此在通信和计算重叠能力方面表现较差。
2.3 上下文并行
上下文并行直接将输入分割成多个子序列,每个设备负责计算其对应的子序列。在注意力计算阶段,上下文并行化采用RingAttention[9]来通信键值隐藏状态,并利用在线softmax重缩放来确保正确性。RingAttention通过在多个设备上交换键值隐藏状态来实现环状通信,以确保每个设备都可以和完整的K, V向量进行Attention计算。并且,KV向量的通信和局部注意力计算的过程是可以异步,通过这种方式,可以有效的重叠计算和通信。此外,当上下文并行的通信组扩展到多个节点,RingAttention还可以通过多个环来实现更高效的通信。
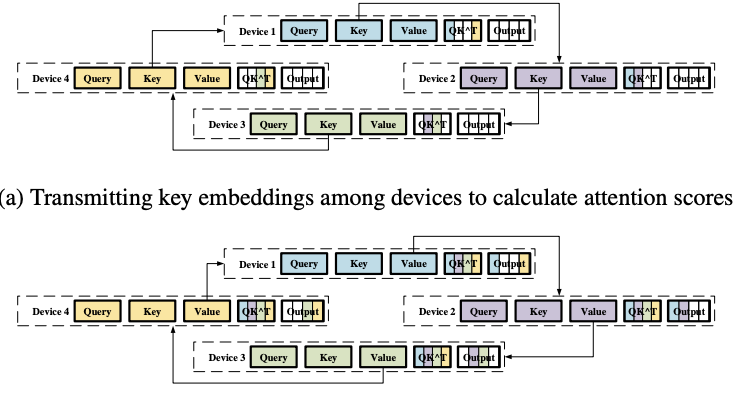
图2 RingAttention多环通信 具体地,最近的工作LoongTrain[10]提出了DoubleRing的通信模式,通过将原本RingAttention的全局通信环根据通信拓扑拆分成多个,环之间通过数据交换从而确保原本的全局通信环的通信结果。这样做的主要优势在于,现在的高性能计算集群,GPU往往和网卡连在一个PCIe Switch上以确保GPU之间的跨网络通信不再需要经过CPU,而是直接通过PCIe Switch进行数据交换,即所谓的GPUDirect技术。当一台机器上有多个GPU时,也就对应拥有多张网卡,DoubleRing的通信模式可以充分利用这些网卡,从而提高通信效率,因为在一整个环的通信过程中,通信的瓶颈在于相邻GPU之间的网络通信,而DoubleRing的通信模式可以将这些通信瓶颈分散到多个环中,并将环间通信和环内通信进行异步, 从而提高通信效率。
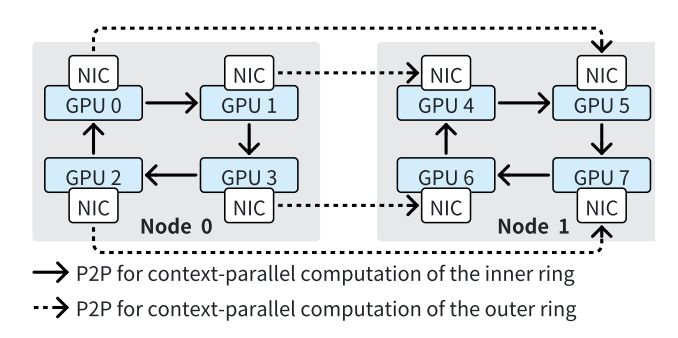
图3 DoubleRing-异步环内/间通信
3. 长文本训练的未来展望
随着序列长度逐渐增长,长文本训练技术将会在未来得到更广泛的应用。未来,我们可以期待更多的长文本训练技术的出现,比如更高效的Attention计算方法、更好的分布式训练策略等,这将使得LLM在更多领域有更好的应用效果。此外,长文本训练也将有助于推动更多领域的发展,比如代码生成、文档生成、知识图谱等,这将使得LLM在更多领域有更好的应用效果。 [1] Touvron, H., Lavril, T., Izacard, G., Martinet, X., Lachaux, M. A., Lacroix, T., ... & Lample, G. (2023). Llama: Open and efficient foundation language models. arXiv preprint arXiv:2302.13971. [2] Team, G., Anil, R., Borgeaud, S., Wu, Y., Alayrac, J. B., Yu, J., ... & Ahn, J. (2023). Gemini: a family of highly capable multimodal models. arXiv preprint arXiv:2312.11805. [3] Jiang, A. Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D. S., Casas, D. D. L., ... & Sayed, W. E. (2023). Mistral 7B. arXiv preprint arXiv:2310.06825. [4] Rabe, M. N., & Staats, C. (2021). Self-attention does not need memory. arXiv preprint arXiv:2112.05682. [5] Dao, T., Fu, D., Ermon, S., Rudra, A., & Ré, C. (2022). Flashattention: Fast and memory-efficient exact attention with io-awareness. Advances in Neural Information Processing Systems, 35, 16344- [6] Narayanan, D., Shoeybi, M., Casper, J., LeGresley, P., Patwary, M., Korthikanti, V., ... & Zaharia, M. (2021, November). Efficient large-scale language model training on gpu clusters using megatron-lm. In Proceedings of the International Conference for High Performance Computing, Networking, Storage and Analysis (pp. 1-15). [7] Jacobs, S. A., Tanaka, M., Zhang, C., Zhang, M., Song, S. L., Rajbhandari, S., & He, Y. (2023). Deepspeed ulysses: System optimizations for enabling training of extreme long sequence transformer models. arXiv preprint arXiv:2309.14509. [8] https://github.com/zhuzilin/ring-flash-attention.git [9] Li, S., Xue, F., Baranwal, C., Li, Y., & You, Y. (2021). Sequence parallelism: Long sequence training from system perspective. arXiv preprint arXiv:2105.13120. [10] Gu, D., Sun, P., Hu, Q., Huang, T., Chen, X., Xiong, Y., ... & Liu, X. (2024). Loongtrain: Efficient training of long-sequence llms with head-context parallelism. arXiv preprint arXiv:2406.18485.
