
****导读本文分享主题为大语言模型分布式训练的相关技术及量化分析,并以GPT-175B 为例,介绍相关技术的最佳实践。
今天的介绍围绕以下四点展开:
- Transformer 大语言模型的 SOTA 训练技术
- 以 GPT-175B为例,最新训练技术量化分析
- 大模型性能调优过程的显存开销、通信开销和计算开销分析
- 总结思考分享嘉宾|颜子杰 NVIDIA 计算专家编辑整理|Tony Wang内容校对|李瑶出品社区|DataFun
**01****Transformer **大语言模型的 SOTA 训练技术
1. 大语言模型的发展背景与挑战首先和大家分享下大语言模型的发展背景。过去的几年内,无论从数据量的维度还是从模型规模的维度,语言模型规模都扩大了非常多的数量级。随着数据量和模型规模的扩大,也面临着一些挑战。

其中涉及的挑战主要可以分为两部分。首先是计算方面,这里给了一个来自于Megatron 论文的公式去计算一个模型训练时需要的计算 FLOPS,我们可以简单推算一下,GPT-3 175B 模型使用现在比较合理的 1.5T Tokens 数据量训练,大概需要 128 个 DGX A100 节点(*仅供技术交流使用),共计 1024 张 A100 卡(*仅供技术交流使用),在效率比较高的条件下连续训练 120 天。而且这还是一个非常理想的估计值。因为在实际训练时候不可避免地会遇到一些例如 Checkpoint、Save 与 Load 的时间、节点崩溃及重启时间,或者我们需要取 Debug loss 曲线不正常的时间,因此实际的训练时间会远超过这个理想估计时间。

其次是运行大语言模型对显存开销的挑战。例如对 GPT-3 175B 模型训练时的显存开销主要可以分为两部分,第一部分是这个模型的状态所占的显存,包括模型参数量、梯度和优化器所占的显存。其中,主要的显存开销是优化器状态部分,也就是我们用 Adam 优化器会涉及到的 Momentum 和 Variance 等。另一部分是 Activation 所占的显存,后面会具体地推算这个 Activation 实际会占多大显存,以及用了我们的一些优化手段后, Activation 会占多少显存。但无论如何,这两个部分显存加起来后会是一个巨大的显存占用量,我们需要对模型进行合理的切分,把它分布到不同的 GPU 上之后才能将模型运行起来。

今天我们也就围绕上述的这两点挑战展开,一个是我们如何把模型运行起来,也就是解决显存开销的挑战;另一个是我们如何把模型运行得足够快,也就是如何选择合理的并行手段和优化手段。 

**2. **大语言模型的 SOTA 训练技术
****接下来介绍下本次分享的大语言模型训练技术的总体概览。下图中标记绿色的是去年或今年新出来的一些技术,而标记蓝色的是比较经典的技术。并行部分的介绍包括 Pipeline 并行、Tensor 并行和 Megatron v3 版本新出的 Sequence 并行。Expert 并行是针对 MOE 模型的一种并行,本文中不做展开。第二个部分是显存优化,包括之前常听到的 ZeRO,在 Megatron 和 NeMO 中已经实现了 ZeRO-1,即 Distributed Optimizer;和Checkpoint Activations,其中 Selective Activation Checkpoint 是目前 Megatron 中用的比较多的,也是比较高效的一个 Checkpoint 技术;其他的包括我们比较常用的,例如混合精度训练,Kernel Fusion 和 Flash Attention 等,以及在最新的 Megatron 和 NeMO 上更新的 Pipeline 通信和 Tensor 通信等。

02****
以 GPT-175B 为例,最新训练技术量化分析
1. GPT-3 ****模型分布式训练技术:模型并行首先简单地介绍下一些经典的并行化技术。例如,Tensor 模型并行(TP)和Pipeline 模型并行(PP)。其中,TP 是对模型的每个层做了一个层内的拆分。目前 TP 只用于 Linear 层,当 Linear 层的 Shape 比较大时,使用 TP 是能达到很好的 GPU 利用率的。但 TP 也有一个缺点,即对每个 Linear 层做拆分,因此它的通信粒度是非常细的。这就意味着,在不做优化的条件下,TP 每计算一次层的拆分,就需要有一次通信来做它的 Activation 合并操作,虽然 TP 单次通信量较小,但是它通信频率频次都很高,对带宽的要求也很高。PP 是流水线并行,也就是一个层间的拆分,把不同的层放到不同的 GPU 上。PP 的切分粒度比 TP 更粗,因此 PP 的通信量远小于 TP 的通信量,但是 PP 也存在一些缺点。一个完整的 Pipeline 运行起来需要将一个很大的 workload 切分成很小的多个 Workload,也就是需要将一个比较大 Batch size 切分成很多个小 Batch 才能保持流水线并行的高吞吐。并且如果在流水线拆分时候不同的 GPU 上的 Workload 不均匀会导致整个流水线的效率非常低。

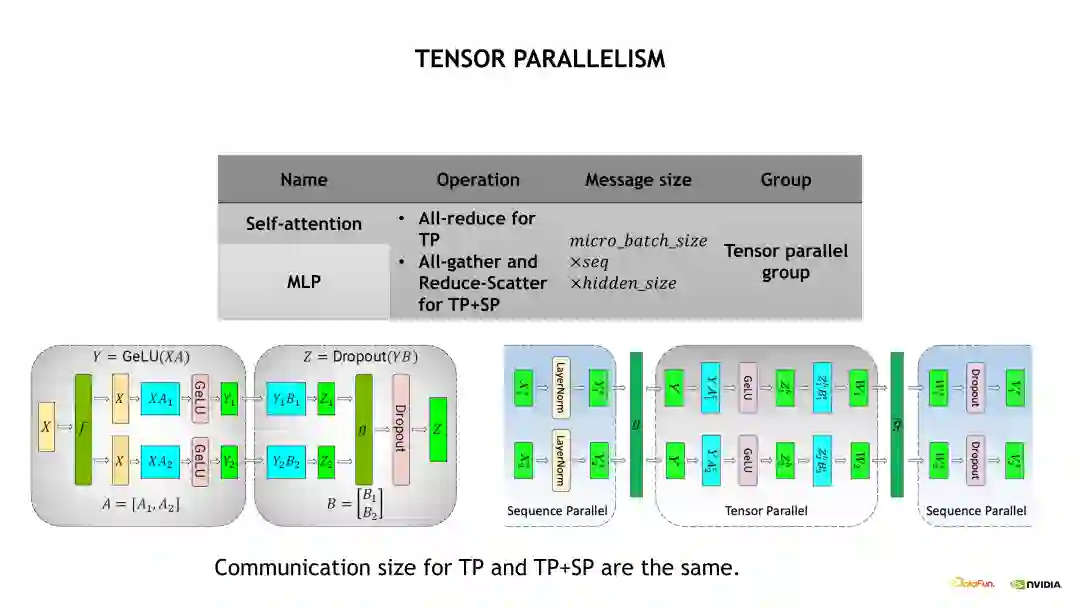
下图是一个 TP 的示意图。MLP 基于 TP 做了拆分,由两个 FFN 组成。在做 TP 拆分时做了一次优化,也就是对第一个 Linear 层做列拆分,对第二个 Linear 层做行拆分,因此在每次 Forward 或 Backward 时只需要一次通信就能完成两个 Linear 层的 TP 拆分。但在未做优化时,需要两次通信完成 TP 拆分。具体而言,也就是在 Forward 计算时,会在 g 操作处做一次 All-reduce 操作,实现 Activations 的一次平均;相应地,在 Backward 计算时会在f 操作处做一次 All-reduce 操作,实现梯度的平均。
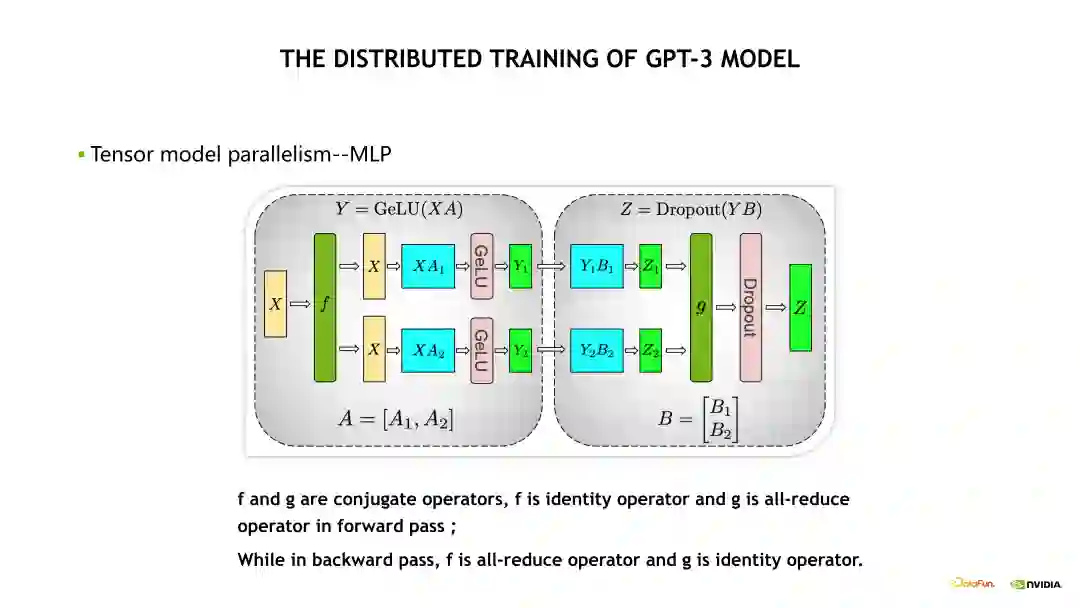
另一个是对 Self-Attention 的 TP 拆分,如下面的示意图,包括 Multi-head Attention 和 Linear 层两个部分,对Multi-head Attention 的 TP 拆分是基于不同的 head 实现的,将不同的 head 放到不同的 GPU 上。同时,对 Linear 层做了行拆分。与 MLP 的两个 Linear 层 TP 拆分类似,在 Forward 计算时在 g 操作处做一次 All-reduce,以及在 Backward 计算时在 f 操作处做一次 All-reduce。

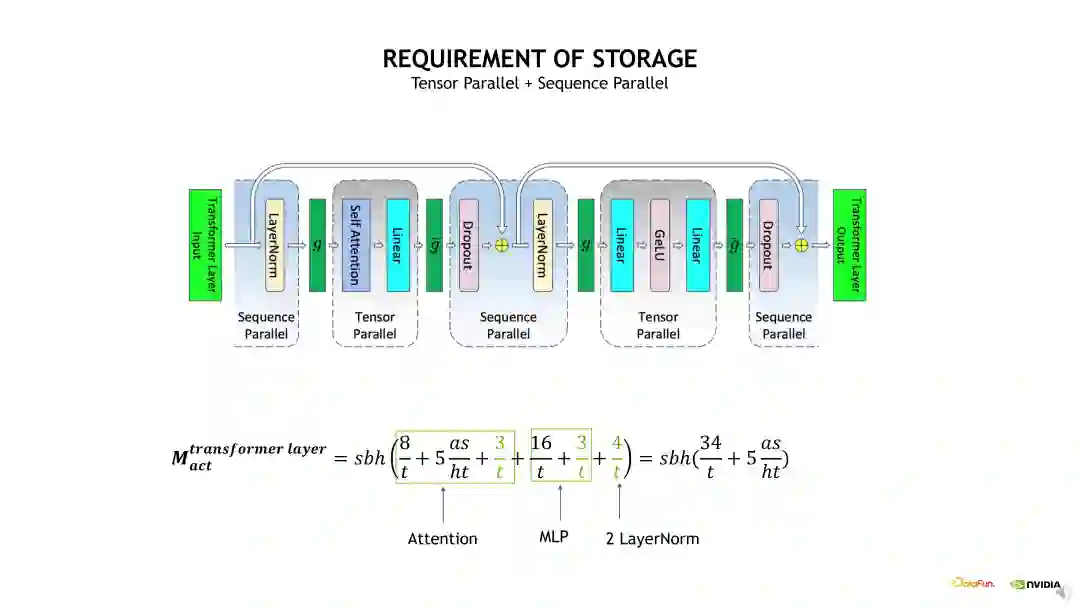
接下来介绍的是 Sequence Parallelism,即序列并行,是对 TP 的优化补充。例如,TP 拆分只会对 MLP 和 Self-Attention 的 Linear 层做并行化拆分,但是对其他的层,例如 Dropout 和 Layernorm 等没有做并行化拆分,因为在一个 TP group 内,Layernorm 层的输入是相同的,所以它的计算是完全相同的,也即在每 8 张 GPU 上的计算是完全相同的,因此这个部分的计算是冗余的。但是我们可以在它的 input 做 Sequence 维度上的拆分,经过拆分后,在不同的 GPU 上它的 Layernorm 层的输入是经过拆分的,包括 Activation 相当于也被拆分过了,所以不会有冗余的计算,从而能减少显存的占用。如下 Sequence Parallelism 示意图,具体实现 Sequence Parallelism 时,我们实际上是在 Layernorm 层做 Sequence Parallelism 拆分,然后在 Linear 层,又转换成 TP 拆分,在 g 操作处将 Activation 进行一次 all-gather 通信。执行 TP 之后,再将 Activation 做一次 Reduce-scatter,之后又转换成 input 在 Sequence 维度被拆分的状态。对于通信量而言,使用 Sequence Parallelism 后,原先的一次 All-reduce 通信变成了一次 All-gather 通信加上一次 Reduce-scatter 通信,表面上通信的次数是变多了一倍,但是由于 all-reduce 的通信量其实是 All-gather 或 Reduce-scatter 的近两倍,所以整体上的通信量差不多是一致的。也就是我们在 Sequence Parallelism 优化后,通信量上并没有改变,但是我们能收获更少的计算量以及更少的 Activation 显存占用。
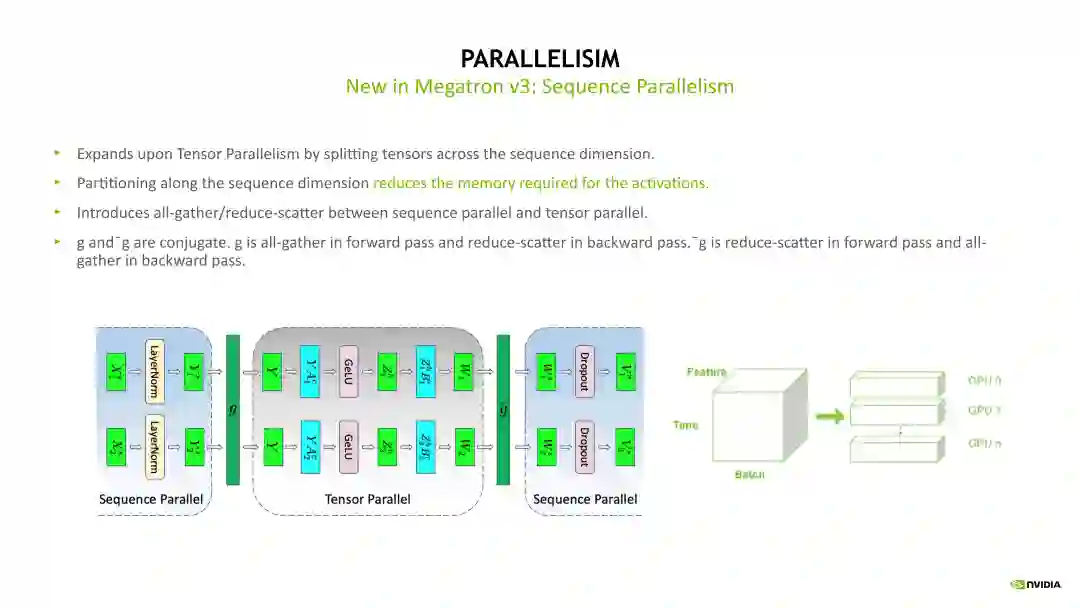
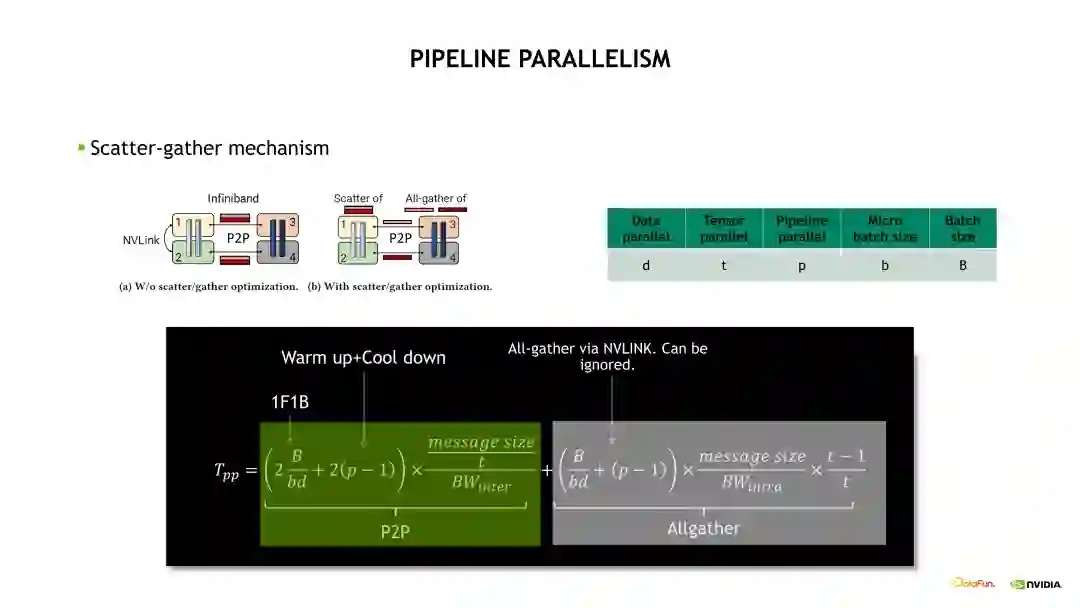
下面介绍一个 4 GPU 的流水线并行的例子。首先我们需要将第一个蓝色的,即第一个 mini batch 的 Forward 计算在 Device 1 运算起来,计算完毕后传到 Device 2,然后一致传到最后一个 Device,这个流水线就逐渐繁忙起来。当最后一个 Device 计算完 Forward 后,开始计算 Backward,之后可以将这个 Backward 往前传。这样的计算模式被称为 One Forward One Backward(1F1B)状态。最后会由最后一个 Device 将最后一个 mini batch 的 Backward 往前传。所以如果只看最后一个 Device 的话,整个流水线是会先空几个格,然后一直繁忙,然后在最后再空几个格。在 1F1B 计算状态,前面的几个空格被称为 Warm up 阶段,最后的几个空格阶段被称为 Cool down 阶段。如果我们只看最后一个 Device,整个流水线的空闲时间被称为 Bubble 时间,也就是它的 Warm up 时间加上 Cool down 时间。如何将流水线的空闲时间减少呢?根据示意图给出的公式,需要看 Bubble 时间除以理论时间得到的比例。我们需要尽量减小这个比例,例如可以尽量增大 mini batch 数量,也即需要拆分出来更多的 mini batch。但是并不是拆分更多的 min batch 就一定有收益。如果 mini batch 特别小,那么 GPU 计算的 Overhead 会比较大,单次的计算时间会增加,因此需要有一定的 Trade-off。所以我们对 PP 进行了优化,采用交错流水线并行策略。
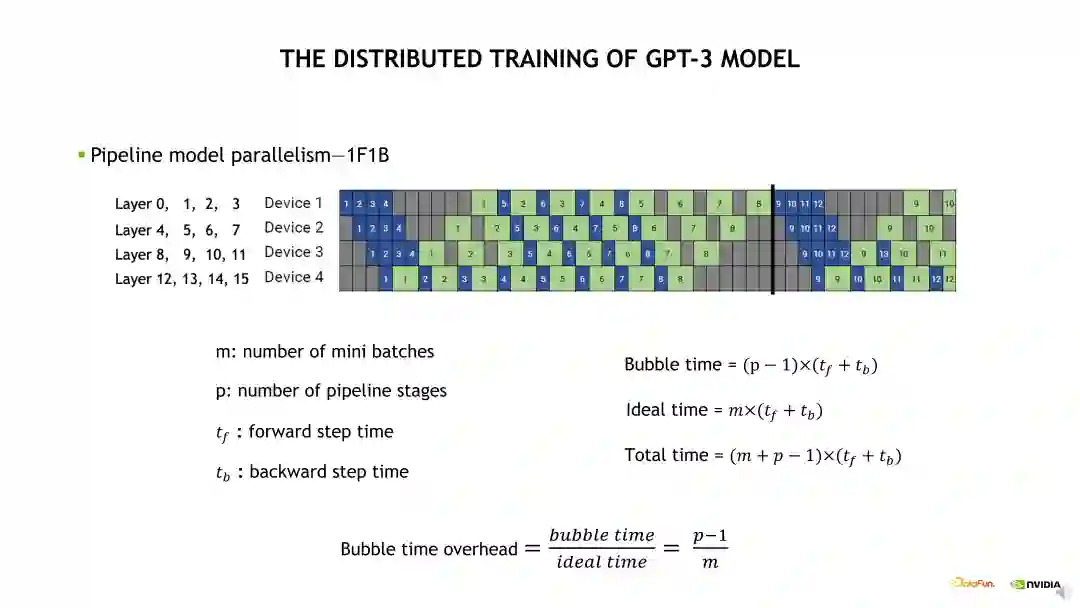
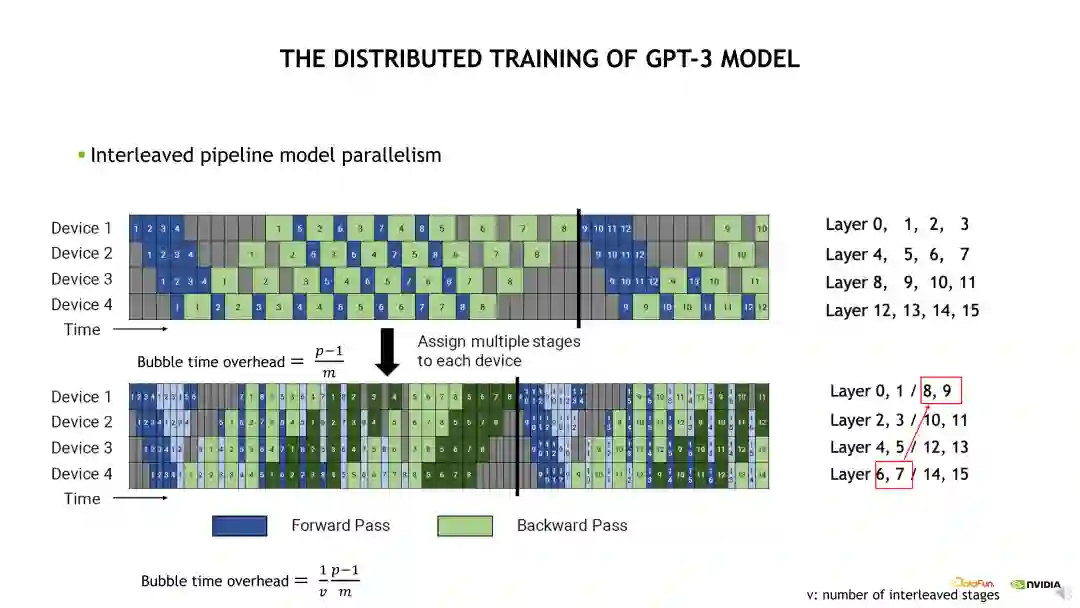
交错流水线并行如下边的示意图。与默认流水线并行的区别在于,默认的流水线并行是对模型层进行了一个连续的拆分,交错流水线并行是对模型层进行一个跳跃式的拆分。例如 Device 1 需要计算 Layer 0 至 3。根据前面介绍的 1F1B 计算状态,Device 4 需要在前面有一个 Warm up 时间才能进入计算状态。如何减少这个 Warm up 时间呢?其中一个方法是拆分更小的 mini batch,另一个方法是让每个 Device 计算更少的层就能获取到第一个 Activation。例如示意图的下半部分,Device 1 需要计算的模型层是 Layer 0、1 和 Layer 8、9。在不考虑通信的条件下,流水线的 bubble 时间就缩小了一半。这个也是 Megatron 和 Nemo 对流水线并行的一个优化。
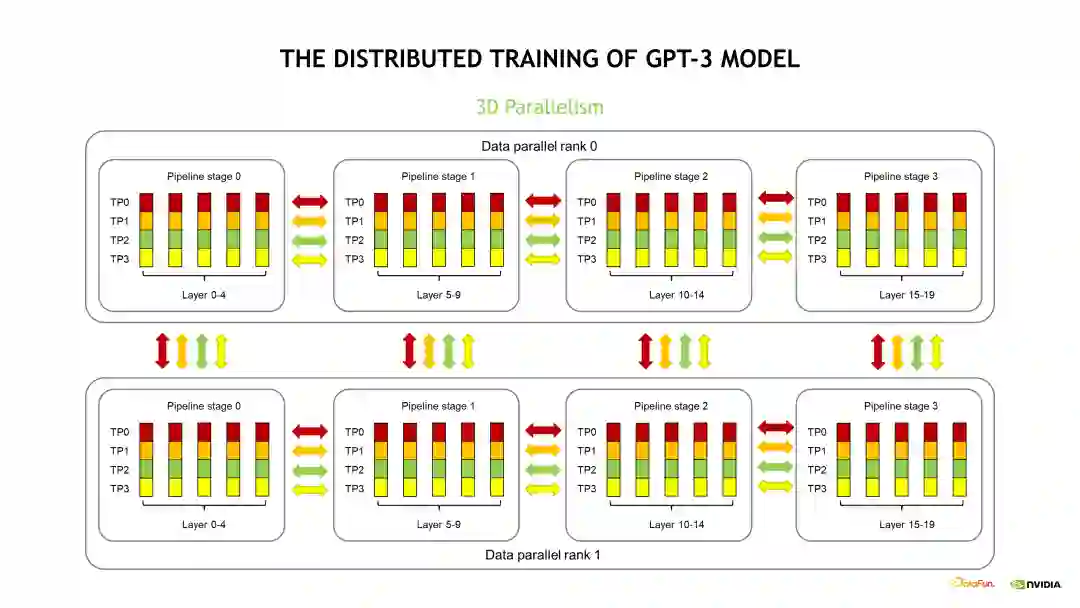
接下来我们将三个并行优化耦合到一起,看下它的通信模式是什么样。下图介绍的是一个 20 层的模型,包括了 DP、PP 和 TP 三个维度的并行优化。首先在 DP 维度,我们设置了两组 DP。由于每组 DP 获取了不同数据,所以产生的梯度是不同的,因此在完成了 Backward 计算后需要对它的梯度做一次更新,在梯度更新前需要执行一次梯度的 All-reduce 操作同步。在每组 DP 内部,20 层的模型被拆分为四个流水线并行阶段 stage,每个 stage 包含了模型的 5 个层。对每个 stage 而言,需要计算完包含的 5 个层,并将对应的 Activation 传到后续的 stage,以此类推,这个是流水线并行的通信模式。在流水线并行的 stage 内部是 TP 拆分,由四个 GPU 维护了这五层模型的计算,也即每个 GPU 只计算了其中的 1/4。这四个 GPU 在计算完第一层后需要做一次 All-reduce,然后才能计算第二层,以此类推,这个是 TP 的通信模式。由于 TP 的通信量是最大的,而且通信频次很高,同时 TP 大O量的通信是必须和计算顺序执行的,没办法做 Overlap 优化。因此,我们通常会将TP 设置成最里面的维度,尽量使用 NVLINK 高速带宽通信。DP 的通信量比 PP 的通信量大很多,所以 DP 优化通常设置成第二个维度,也是可以用 NVLINK 通信。当模型比较大时,我们将TP 设置为 8 后,相应的 DP 通信会跨节点通信。PP 对通信的需求是最小的,且通信的频次比较低,通信量也比较小,所以一般会将 PP 优化设置成最外面的那个维度。下边的示意图存在部分差异是为了方便介绍。通常情况下,集群节点间的通信带宽比较低时,可以尽量在节点间使用流水线并行。
2. GPT-3 模型分布式训练技术:Activations显存优化
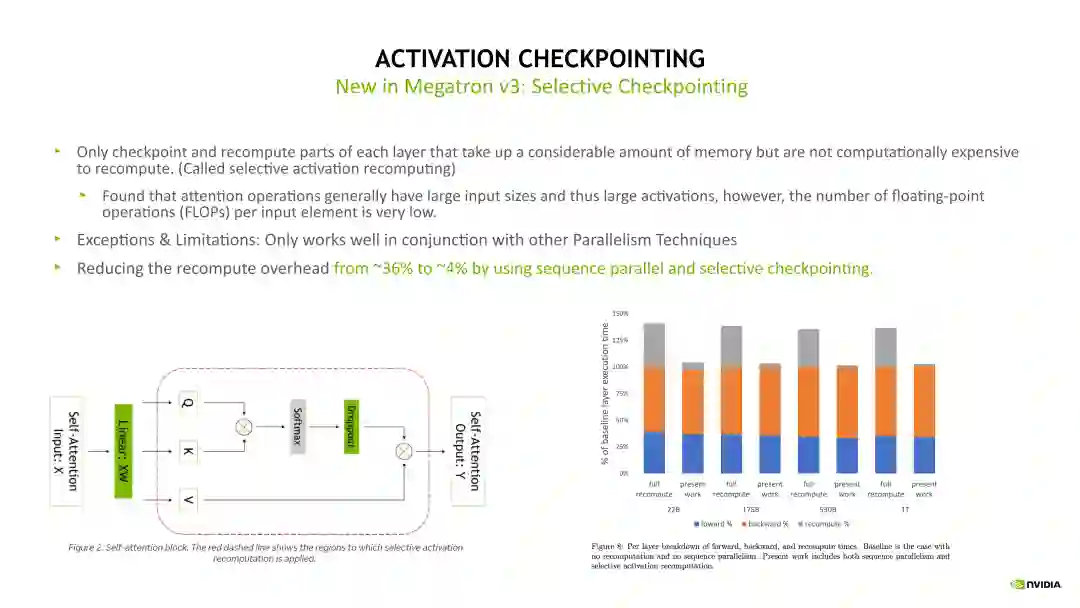
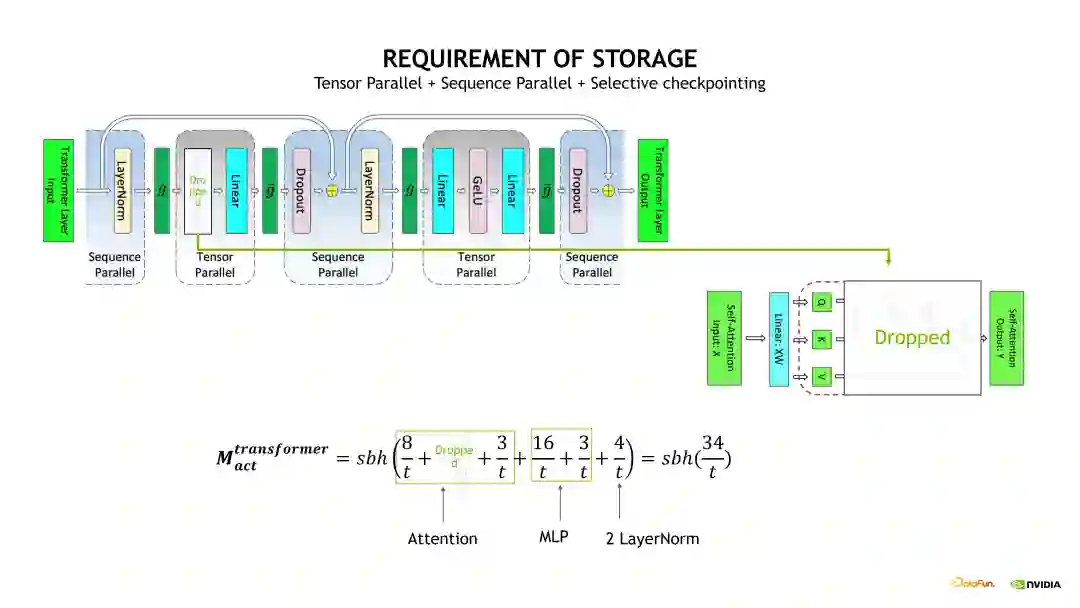
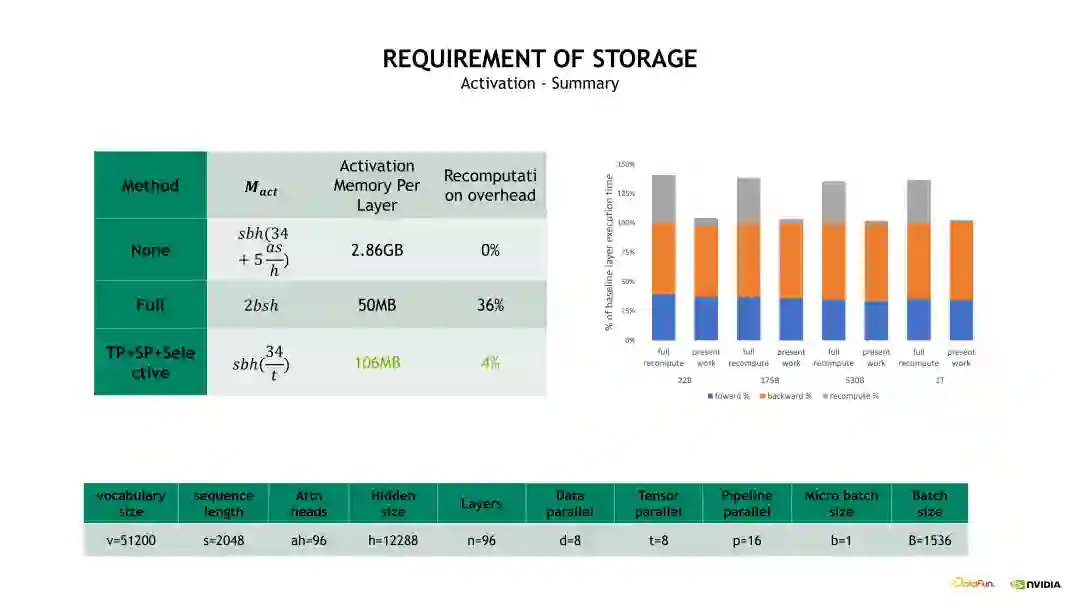
Checkpointing activation 是比较常用的显存优化技术。简单地讲,Checkpointing activation 就是做重新计算。例如在 Forward 计算时得到的 Activation 不再保留,做 Backward 计算时,对这些 Activation 进行重新计算,这样可以极大程度上减少对 GPU 显存的开销。Checkpointing activation 的实现方式有下边示意图列出来的几种。其中一种比较 naïve 的实现是 Full checkpointing,也即对 Transformer 的每个层都进行重新计算。例如在最后一层做 Backward 计算时,需要这个 Transformer layer 在 Backward 计算之前重新执行一次 Forward 计算,当重新计算 Forward 后再开始这个层的 Backward 计算。Full checkpointing 对每个 Transformer layer 都打了一个重算点。所以 Full checkpointing 的好处在于将显存开销降低到 O(n)的复杂度,而不足在于对每个 Transformer layer 都要重新计算一遍,从而带来了近 36% 的额外计算开销。另一个优化 Activation 的方式是 Sequence Parallelism 加上 Selective checkpointing,将这个重算的开销从 36% 降低到 4%。

在前面的介绍中已经说明了 Sequence Parallelism 主要优化了 Dropout 和Layernorm 层。相对于 naïve 方式实现的 checkpointing,Selective checkpointing 会选择一些重算性价比高的OP,对一些计算时间比较小但产生Activation 占用的显存很大的 OP 进行重算。例如下边示例图左边的 Self-attention 模块,通过对比分析后得出,对 Self-attention这块做重算的收益是非常高的,因为它的计算量相对会少一点,但它的一些中间结果输出占用的显存开销非常大。因此我们就可以只对这块做重算。对其他的层,例如 Linear 和 Layernorm 层,可以采用其他的优化方法对 Activation 进行优化。Selective checkpointing 的核心思想是对一些性价比高的 OP 做重算,并与其他的并行优化方法联合使用,达到 1+1>2 的效果。
**3. GPT-3 **模型分布式训练技术:分布式优化器
接下来介绍下 Distributed Optimizer,即 Zero-1。在模型训练时,Optimizer 状态是模型固定占用显存的主要部分。假如模型参数量是m,则 Optimizer 的显存开销是 16 * m 字节。Zero-1 的思想是在不同的 DP rank 上对 Optimizer 状态做拆分,所以 Distributed Optimizer(Zero-1)在每个 DP rank 占用的显存是 16 * m 除以 DP size,明显降低了显存开销,同时也带来了通信模式的改变。例如,我们可以直接对梯度做 Reduce-scatter,之后再对自己的那一部分参数做Optimizer 相关的状态更新,Optimizer 状态更新完毕后再用一个 All-gather 操作收集模型权重。这样由 DP 并行的一个 All-reduce 变成了一个 Reduce-scatter 加上一个 All-gather。根据前面的介绍,这个 All-reduce 的通信量是 Reduce-scatter 或 All-gather 的两倍,所以整体的通信量是没有变化的,但通信的次数变多了。其次,使用比较多的是 Zero-2 和Zero-3,但目前在 Megatron 和 Nemo 上还没有做支持。因为在实际使用过程中,Zero-2 和 Zero-3 需要每次进行额外的 forward 和 backward 计算,并且每次都需要做通信,但是流水线并行会将一个大的 batch 拆分成很多个小的 forward 和 backward,也就会造成大的通信量。所以当同时使用 Zero-2 或 Zero-3 加上流水线并行时,通信量会大幅上升,因此这里不推荐大家同时使用流水线并行和 Zero-2 或 Zero-3,但流水线并行可以和 Zero-1 同时使用。

03
大模型性能调优过程的显存开销、通信开销和计算开销分析
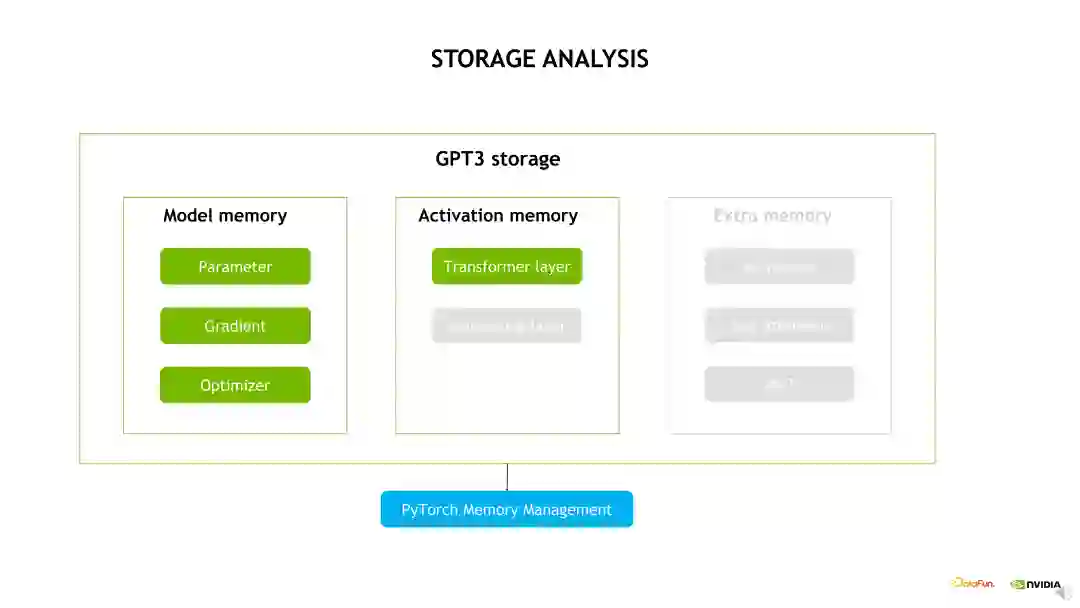
1. ****显存开销分析接下来我们具体对显存开销、通信开销和计算开销做分析。首先是显存开销,以GPT-3 为例子,主要分为三个部分,第一部分是模型占用的显存,即模型状态的显存,包括参数、梯度和 Optimizer 状态;第二部分是 Activation 占用的显存,也就是模型的 OP 产生的中间值,包括模型 Transformer layer 层和 Embedding 层的输出,这里我们简化一下问题,只考虑 Transformer layer;第三部分是可能需要的一些临时 Buffer,这里不做过多的展开,我们主要关注前面两个比较重要的部分。
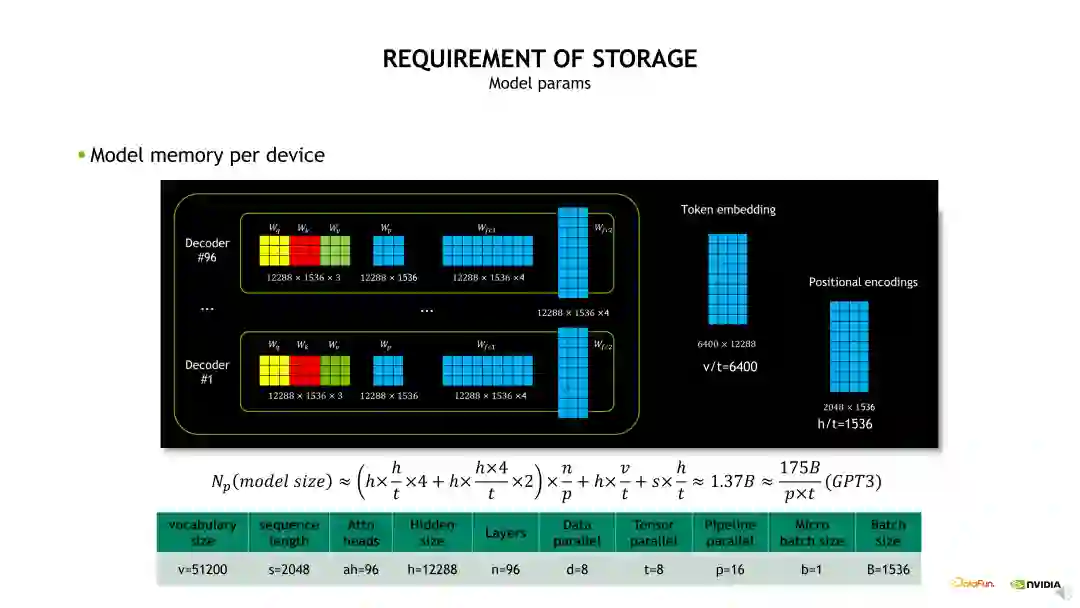
先看下模型参数显存开销,即模型做了 TP 和 PP 拆分后每个 GPU 上会有多大的实际参数。我们先看下 GPT-3 模型的整体构成,模型包含了 96 层 Decoder,在每层 Decoder 内包含一个 QKV 权重、Projection 权重以及两个 FC 的权重,这样的权重会被重复 96 次,另外包含了 Token Embedding 和 Position Encoding 的权重。当进行TP 拆分时,相当于 QKV 权重和 Projection 权重会除以 t,再挤上两层的 FC 权重也除以 t,t 是TP 拆分的数量。然后进行 PP 拆分,也就是原始的 n 层除以 p,p 是 PP 拆分的 stage 数量,再加上 Token Embedding 和 Position Encoding 也做了 TP 维度的拆分。所以当 TP 等 8,PP 等于 16 时,每个 GPU 上需要存储 1.37B 的参数量。
对于 1.37B 参数量实际占用的显存,当我们使用混合精度时,模型的参数和梯度占用的显存都是 2.74GB。由于 Optimizer 状态占用的显存是 16 倍的参数量,所以 Optimizer 占用的显存是 21.9GB,可以看到主要是 Optimizer 状态占用很大比例的显存开销。
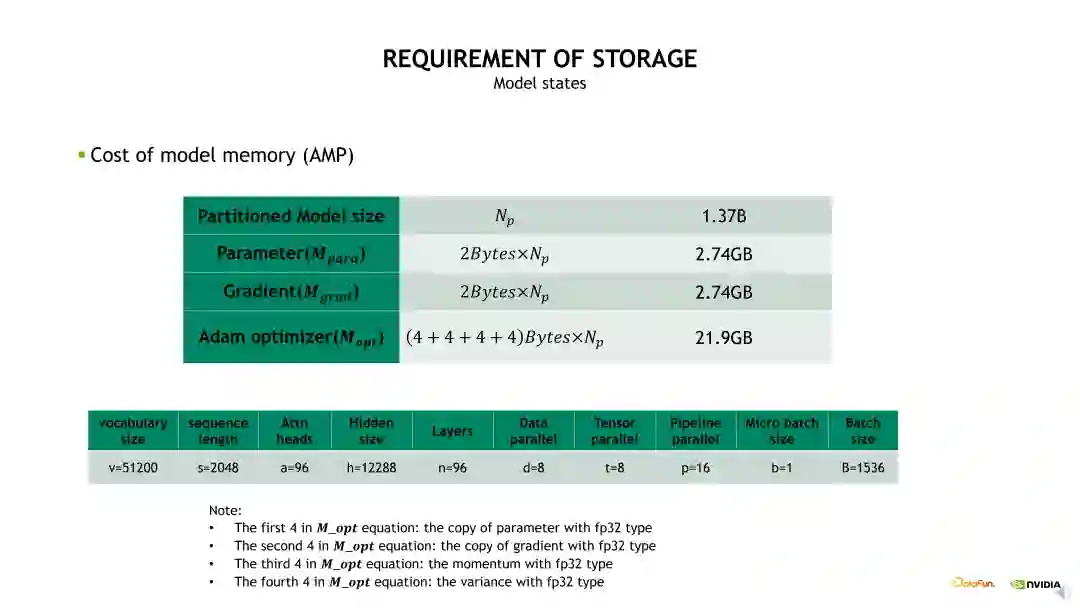
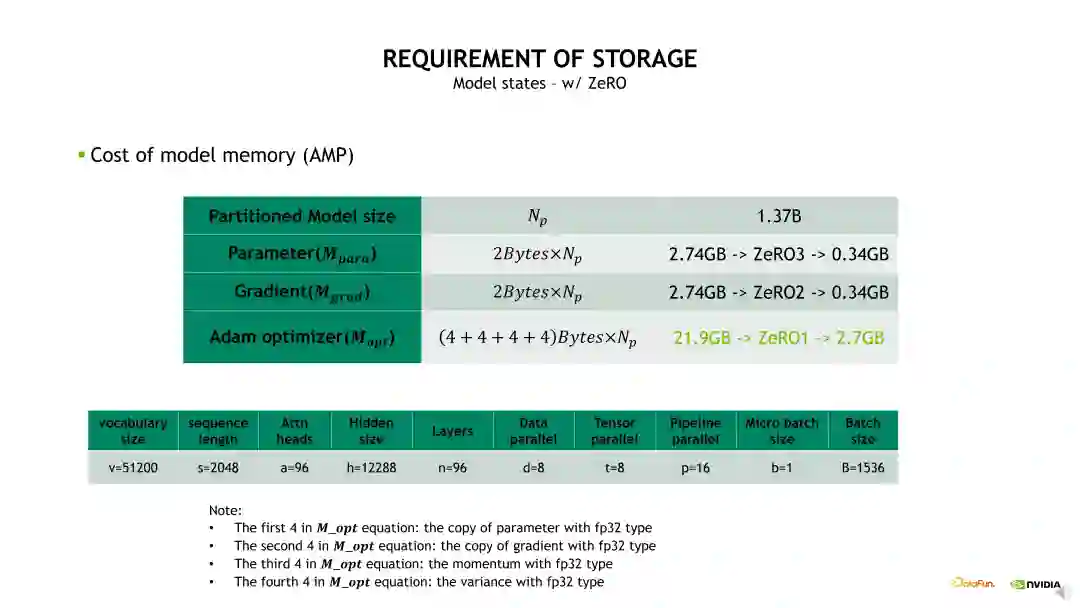
Optimizer 状态的显存开销可以通过前面介绍的 Distributed optimizer 或 Zero 技术进行优化。其中,Zero-1技术可以将 Optimizer 状态做一个 DP 维度的拆分,从而降低显存占用。例如,当DP size 设置为 8 时,Optimizer 状态的显存占用可以从 21.9GB 降低到 2.7GB。若在 Zero-1 基础上再做 Zero-2,可以将梯度也进行 DP 维度的拆分,梯度的显存占用由 2.74GB 降低到 0.34GB。若再做 Zero-3,可以将参数也做相应的拆分,将其显存占用降低为 0.34GB。可以看到,当 DP size 等于8 时,使用 Zero-1 对 Optimizer 状态做拆分就可以带来明显的显存开销降低。相对而言,使用 Zero-2、Zero-3 对梯度和参数做拆分时的显存开销优化不明显,同时会增加非常多的通信 overhead。所以建议如果不是显存特别紧张的条件下,尽量不要用 Zero-3。一方面它带来很大的计算开销和通信开销,另一方面它的优化也会比较难调试。从另一个角度来说,当模型参数被 TP 和 PP 拆分后,每个 GPU 上的参数和梯度自然地被拆分了,所以它占用的显存也比较小,使用 Zero-1 就能达到一个很好的效果。另外,值得注意的是,我们并不推荐使用 PP 后再叠加 ZeRO-2/3,主要原因是一方面它对显存的进一步优化不是很明显;另一方面是它会带来一定的通信冲突,所以建议大家使用 TP 和 PP 后用 Zero-1 就可以了。
接下来介绍 Activation 显存开销。为简化问题,我们只分析单个 Transformer layer 的 Activation 显存占用。具体的计算方法是考虑每个 OP 计算输出的 shape 大小,将各个 OP 输出的 shape 加起来即可得到预计的显存开销大小。如下边示例图中的公式,从计算公式可以发现一个很大的问题,公式包含了一个s 即 Sequence 长度的平方项,当 s 比较大时,这个显存开销会变得非常恐怖,有必要进行优化。
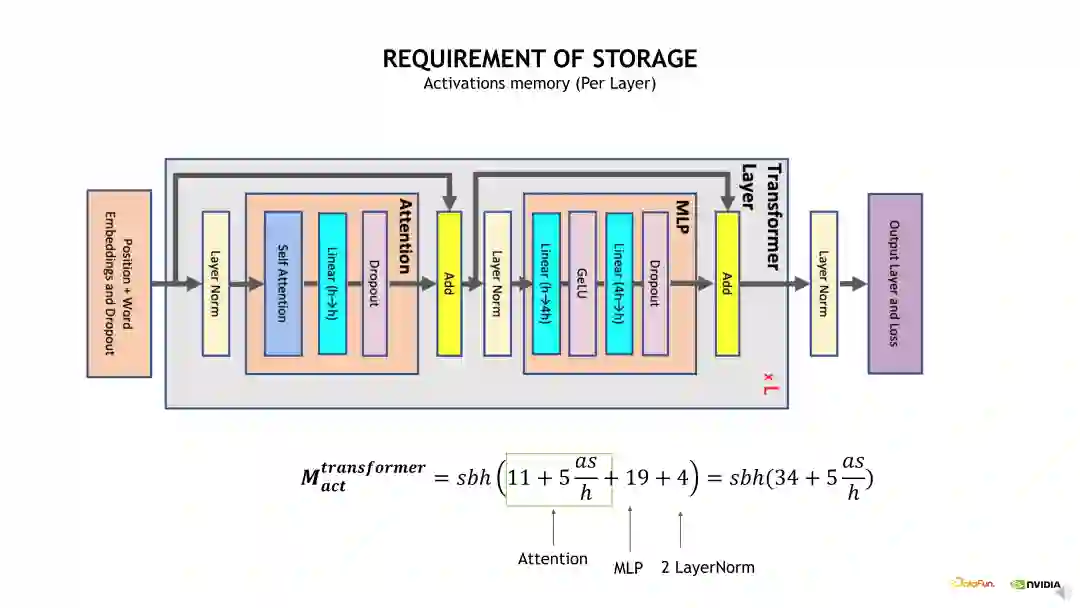
使用前面介绍的 Full checkpointing 优化方法可以有效减少 Activation 显存开销。在 Full checkpointing 中,仅存储每个 Transformer layer 的输出,且中间计算结果在 Backward 时直接重算,从而使得 Activation 显存开销计算变为 2 * b * s * h。

使用 TP 拆分,实际上就是对 Self-attention 和 MLP 进行了 TP 维度的拆分,将相应 QKV 和 FC 计算输出的 shape 除以 t,如果在这个基础上,再加上Sequence Parallelism 的话,会进一步对两个 Layernorm 输出的 shape 除以 t。在这个基础上继续使用 Selective checkpointing 时,就可以将这个 s 的平方给优化掉,因为我们会把这个 Self-attention 的输出 Activation 直接 Drop 掉。

2. ****通信开销分析通信开销也分成 DP、TP 和 PP 三个部分。首先看下 DP 的通信开销,如下图所示,DP 的通信开销等于梯度通信的大小除以总线带宽,再乘以一个 All-reduce 系数,其中总线带宽需要根据实际的消息大小去测试出一个总线带宽的估计。 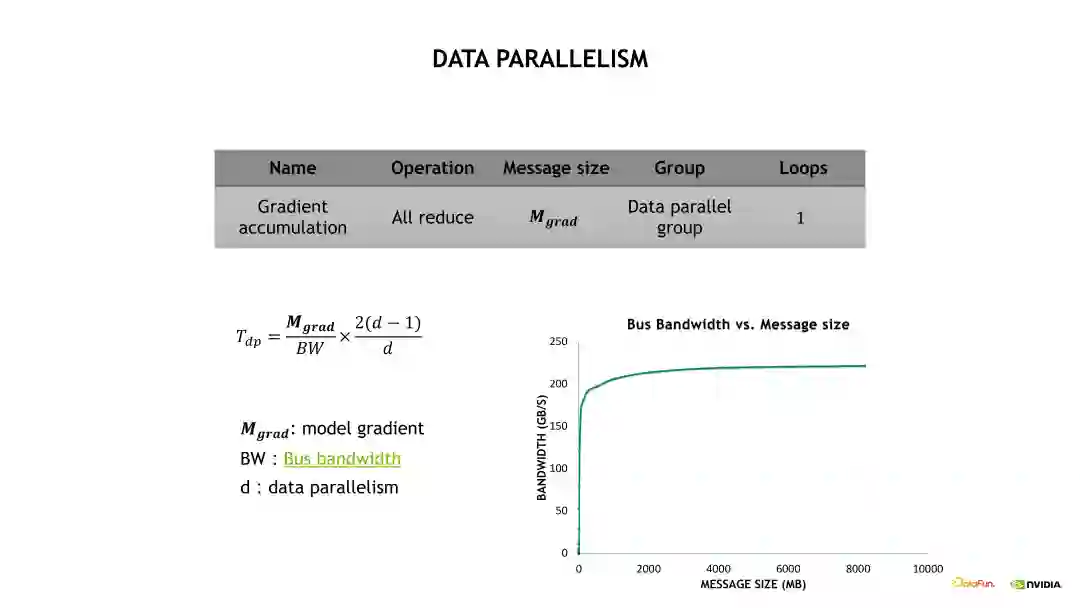
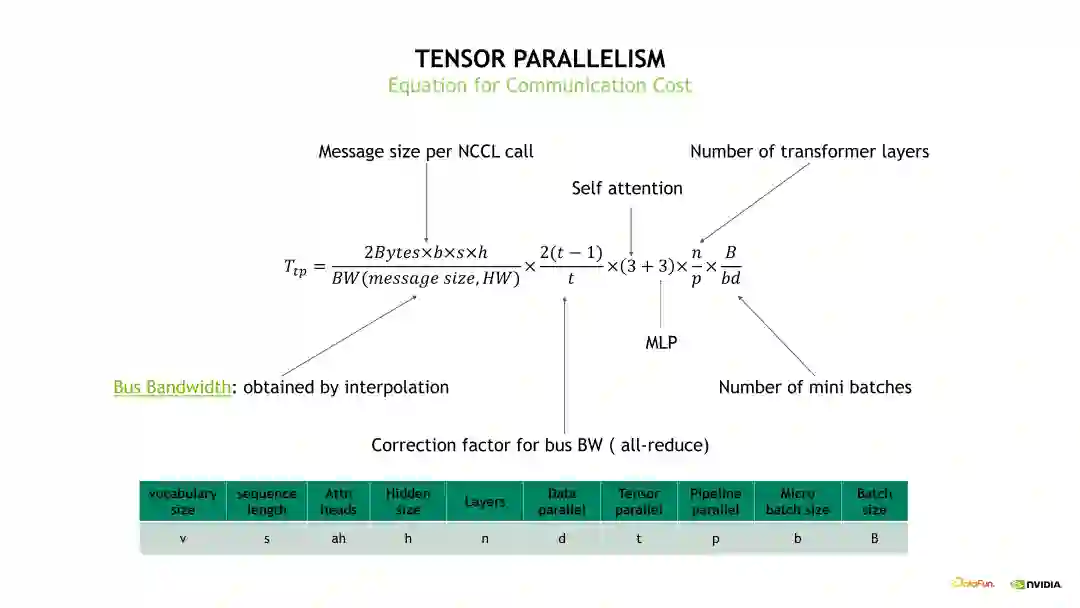
3. ****计算开销分析接下来介绍下计算开销,具体的计算公式推导见下边的示例图公式。示例图左边的是对 Self-attention、FFN 和 Logit 层的计算拆解,主要计算一些 Linear 层的 FLOPS。将这些 FLOPS 加起来就得到单个 Transformer layer 的 FLOPS,然后再乘上 Batch 数量以及层数就能得到整体的模型 FLOPS。通过模型 FLOPS 可以衡量整个训练系统的效率是否足够好。例如针对 GPT-3 175B 而言,如果它的模型 FLOPS 在 A100 (仅供技术交流使用)上小于 150 TFLOPS,说明训练可能是有一点问题的,如果小于 120TFLOPS 说明训练肯定有一些比较严重的异常问题,造成速度下降。 
总结思考最后来进行一下总结。对于 GPT-3 175B 的训练而言,我们该怎么去组合这些优化?首先有些优化项是默认开启的,比如我们通常推荐大家使用混合精度、Flash attention 以及 Megatron 上大量的默认优化 OP。其次是半精度训练选择,比如要选择用 BF16 还是 FP16,对于大模型训练推荐优先考虑 BF16,因为 FP16 会有很多潜在的问题和坑,使用 BF16 会比较稳定,尤其是对 20B 以上的模型,推荐大家只用 BF16。接下来是如何将这些优化进行组合,例如,如果训练运行起来有显存开销问题,可以依次打开这些优化,首先可以尝试使用 Selective activation checkpointing,然后开启 Distributed Optimizer,之后逐渐开启 TP。我们不需要一开始就将 TP 设置成 8,这里有个准则,需要评判 Hidden size 除以 TP 后不能小于 1024,最好要大于 2048,这样会有一个比较好的收益。之后逐渐地去开启 PP。不要一开始就将 PP 设置得很大,然后可以用 Full activation checkpointing。如果不会遇到 OOM,并且 GBS 能开的足够大,那么尽量使用 DP 去扩展即可。 

分享嘉宾 INTRODUCTION
颜子杰

NVIDIA、
计算专家
硕士毕业于中山大学,分布式深度学习方向。毕业后在商汤科技负责视觉大模型系统方向的技术预研、规划、落地以及团队管理。加入 NVIDIA 后负责 LLM 训练系统方面工作,在 LLM 训练框架、MOE 框架、性能分析与优化、显存优化等领域有丰富的经验。

