【干货】用BRET进行多标签文本分类(附代码)
【导读】在本文中,我们将重点介绍BERT在多标签文本分类问题中的应用。
作者|Kaushal Trivedi
过去的一年里,深度神经网络开创了自然语言处理的激动人心的时代。 使用预训练模型的领域的研究已经导致许多NLP任务的最新结果的巨大飞跃,例如文本分类,自然语言推理和问答。一些关键的里程碑是ELMo,ULMFiT和OpenAI Transformer。 这些方法都允许我们在大型数据库(例如所有维基百科文章)上预先训练无监督语言模型,然后在下游任务上微调这些预先训练的模型。也许这一领域今年最激动人心的事件是BERT的发布,这是一种基于多语言Transformer的模型,它在各种NLP任务中取得了最先进的成果。 BERT是一种基于Transformer架构的双向模型,它以更快的基于注意的方法取代了RNN(LSTM和GRU)的顺序特性。 该模型还预训练了两个无监督的任务,掩模语言建模和下一个句子预测。 这允许我们使用预先训练的BERT模型,通过对下游特定任务(例如情绪分类,意图检测,问答等)进行微调。
我们将使用Kaggle的垃圾评论分类挑战来衡量BERT在多标签文本分类中的表现。
我们从哪里开始?
Google Research最近公开了BERT的张量流实现,并发布了以下预先训练的模型:
BERT-Base, Uncased: 12层, 768个隐层, 12-heads, 110M 个参数BERT-Large, Uncased: 24层, 1024个隐层, 16-heads, 340M 个参数BERT-Base, Cased: 12层, 768个隐层, 12-heads , 110M 个参数BERT-Large, Cased: 24层, 1024个隐层, 16-heads, 340M 个参数BERT-Base, Multilingual Cased (New, recommended): 104 种语言, 12层, 768个隐层, 12-heads, 110M 个参数BERT-Base, Chinese: Chinese Simplified and Traditional, 12层, 768个隐层, 12-heads, 110M 个参数
我们将使用较小的Bert-Base,无框架模型来完成此任务。 Bert-Base模型有12个层,所有文本都将由分词器转换为小写。
我们将使用HuggingFace的优秀PyTorch BERT端口,可在https://github.com/huggingface/pytorch-pretrained-BERT获得。 我们已经使用HuggingFace的repo中提供的脚本将预先训练的TensorFlow检查点转换为PyTorch权重。
我们的实现很大程度上受到BERT原始实现中提供的run_classifier示例的启发。
数据准备
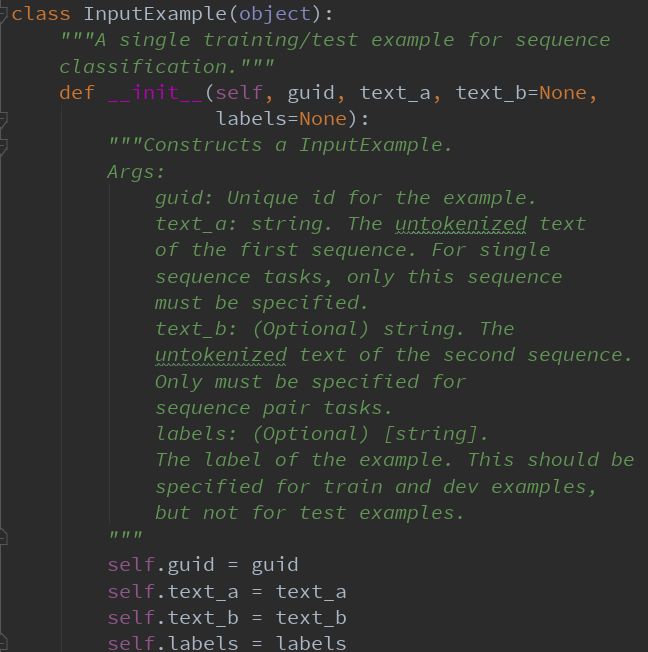
我们在类InputExample 准备数据:
text_a: 评论内容
text_b:未用到
labels: 训练数据对应为标签,测试数据为空
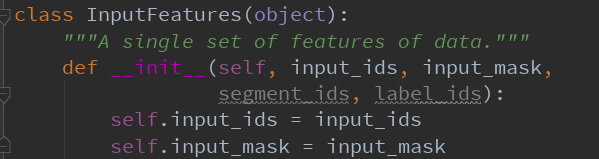
分词
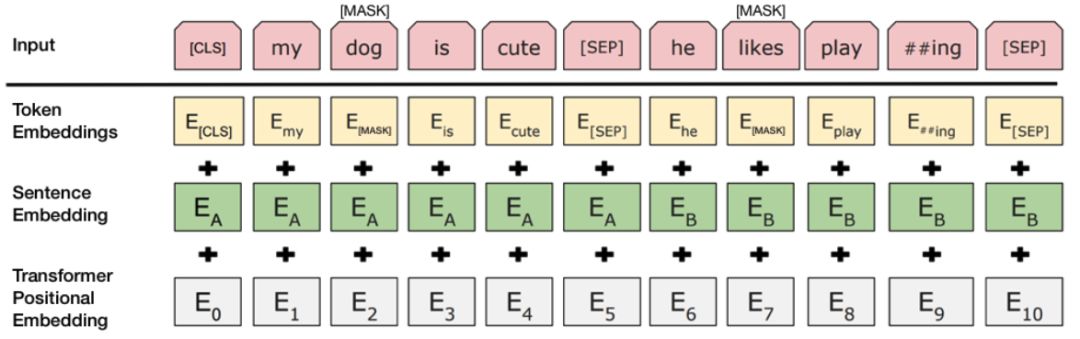
BERT-Base,无监督模型使用30,522个单词的词汇。 分词过程涉及将输入文本拆分为词汇表中可用的标记列表。 为了处理词汇表中不可用的单词,BERT使用一种称为基于BPE的WordPiece标记化技术。 在这种方法中,词汇表之外的词逐渐被分成子词,然后该词由一组子词表示。 由于子词是词汇表的一部分,我们已经学习了表示这些子词的上下文,并且该词的上下文仅仅是子词的上下文的组合。 有关此方法的更多详细信息,请参阅使用子字词单位的稀有单词的神经机器翻译模型。
https://arxiv.org/pdf/1508.07909。
模型结构
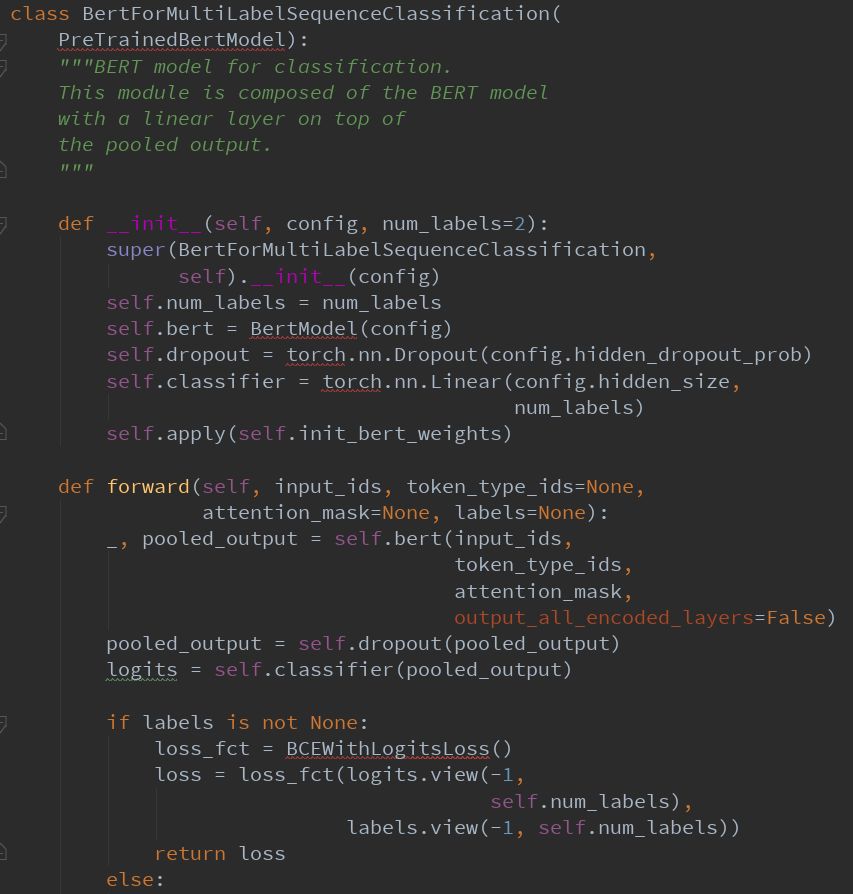

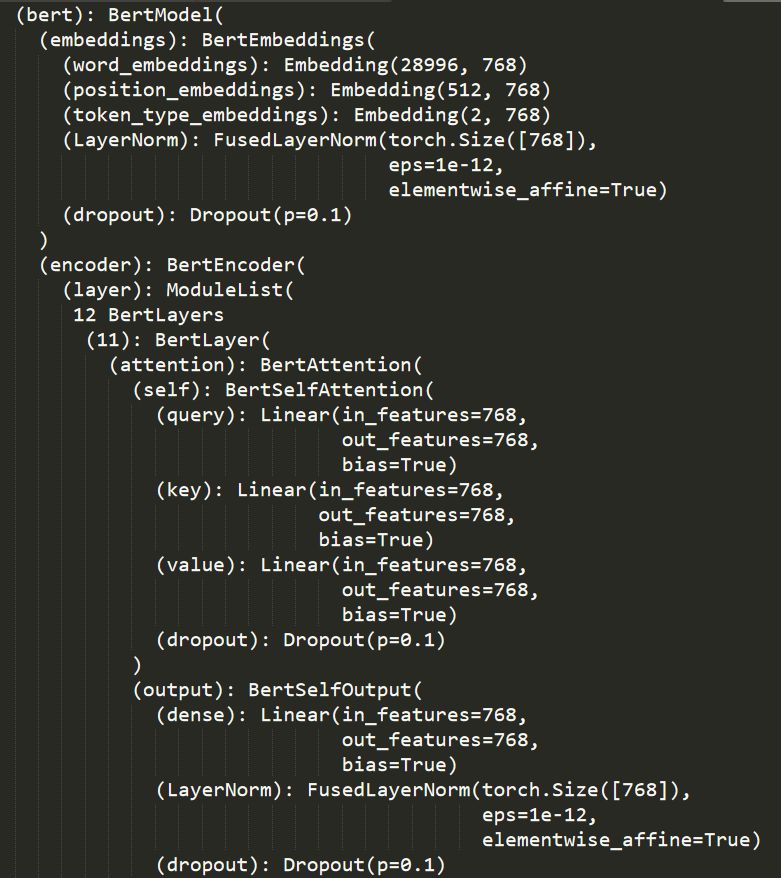
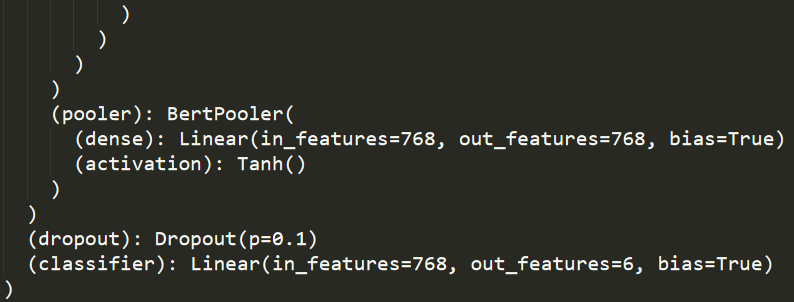
训练
训练循环与run_classifier.py中原始BERT实现中提供的循环相同。 我们训练了4个时期的模型,批量大小为32,序列长度为512,即预训练模型的最大可能性。 根据原始论文的建议,学习率保持在3e-5。
我们有机会使用多个GPU。 所以我们将Pytorch模型包装在DataParallel模块中。 这使我们能够在所有可用的GPU上传播我们的培训工作。
由于某种原因我们没有使用半精度FP16技术,具有logits loss函数的二进制crosss熵不支持FP16处理。 这并不会影响最终结果,只需要更长的时间训练。
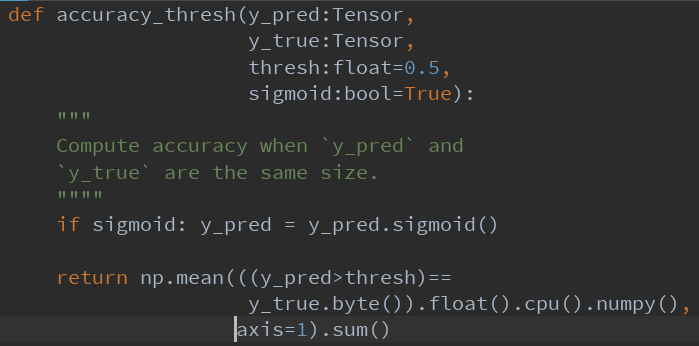
评估指标
我们调整了精度度量函数以包括阈值,默认设置为0.5。
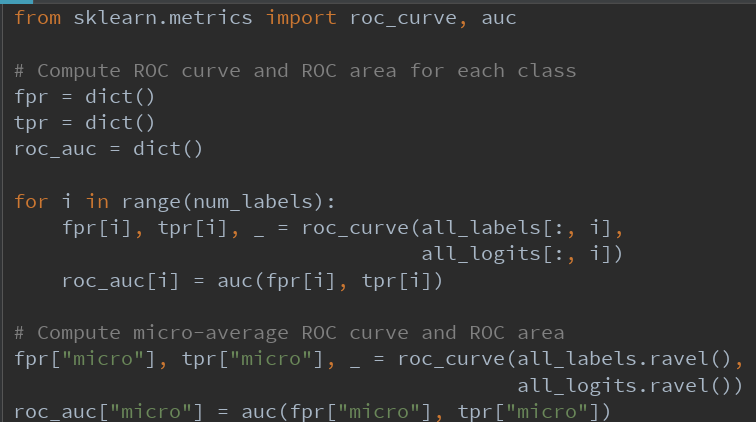
对于多标签分类,更重要的指标是ROC-AUC曲线。 这也是Kaggle比赛的评估指标。 我们分别计算每个标签的ROC-AUC。 我们还在个别标签的roc-auc分数上使用微观平均。
我们进行了一些实验,只有一些变化,但更多的实验得到了类似的结果。 结果如下:
训练损失:0.022,验证损失:0.018,验证准确度:99.31%
各个标签的ROC-AUC分数:
toxic: 0.9988
severe-toxic: 0.9935
obscene: 0.9988
threat: 0.9989
insult: 0.9975
identity_hate: 0.9988
Micro ROC-AUC: 0.9987
【代码实例教程下载】
请关注专知公众号(点击上方蓝色专知关注)
后台回复“BERT” 就可以获取《用BRET进行多标签分类》的代码下载链接~
原文链接:
https://medium.com/huggingface/multi-label-text-classification-using-bert-the-mighty-transformer-69714fa3fb3d
-END-
专 · 知
专知《深度学习:算法到实战》课程全部完成!470+位同学在学习,现在报名,限时优惠!网易云课堂人工智能畅销榜首位!

请加专知小助手微信(扫一扫如下二维码添加),咨询《深度学习:算法到实战》参团限时优惠报名~

欢迎微信扫一扫加入专知人工智能知识星球群,获取专业知识教程视频资料和与专家交流咨询!

请PC登录www.zhuanzhi.ai或者点击阅读原文,注册登录专知,获取更多AI知识资料!

点击“阅读原文”,了解报名专知《深度学习:算法到实战》课程




