一文教你如何处理不平衡数据集(附代码)

大数据文摘授权转载自数据派THU
分类是机器学习最常见的问题之一,处理它的最佳方法是从分析和探索数据集开始,即从探索式数据分析(Exploratory Data Analysis, EDA)开始。除了生成尽可能多的数据见解和信息,它还用于查找数据集中可能存在的任何问题。在分析用于分类的数据集时,类别不平衡是常见问题之一。
什么是数据不平衡(类别不平衡)?
数据不平衡通常反映了数据集中类别的不均匀分布。例如,在信用卡欺诈检测数据集中,大多数信用卡交易类型都不是欺诈,仅有很少一部分类型是欺诈交易,如此以来,非欺诈交易和欺诈交易之间的比率达到50:1。本文中,我将使用来自Kaggle的信用卡欺诈交易数据数据集,你可以从这里下载。
相关链接:
https://www.kaggle.com/mlg-ulb/creditcardfraud
首先,我们先绘制类分布图,查看不平衡情况。

如你所见,非欺诈交易类型数据数量远远超过欺诈交易类型。如果我们在不解决这个类别不平衡问题的情况下训练了一个二分类模型,那么这个模型完全是有偏差的,稍后我还会向你演示它影响特征相关性的过程并解释其中的原因。
现在,我们来介绍一些解决类别不平衡问题的技巧,你可以在这里找到完整代码的notebook。
相关链接:
https://github.com/wmlba/innovate2019/blob/master/Credit_Card_Fraud_Detection.ipynb
重采样(过采样和欠采样)
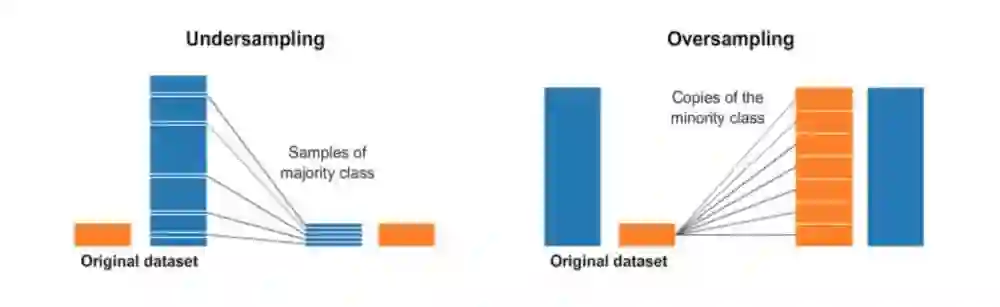
这听起来很直接。欠采样就是一个随机删除一部分多数类(数量多的类型)数据的过程,这样可以使多数类数据数量可以和少数类(数量少的类型)相匹配。一个简单实现代码如下:
# Shuffle the Dataset.shuffled_df = credit_df.sample(frac=1,random_state=4)# Put all the fraud class in a separate dataset.fraud_df = shuffled_df.loc[shuffled_df['Class'] == 1]#Randomly select 492 observations from the non-fraud (majority class)non_fraud_df=shuffled_df.loc[shuffled_df['Class']== 0].sample(n=492,random_state=42)# Concatenate both dataframes againnormalized_df = pd.concat([fraud_df, non_fraud_df])#plot the dataset after the undersamplingplt.figure(figsize=(8, 8))sns.countplot('Class', data=normalized_df)plt.title('Balanced Classes')plt.show()
对多数类进行欠采样
对数据集进行欠采样之后,我重新画出了类型分布图(如下),可见两个类型的数量相等。

平衡数据集(欠采样)
第二种重采样技术叫过采样,这个过程比欠采样复杂一点。它是一个生成合成数据的过程,试图学习少数类样本特征随机地生成新的少数类样本数据。对于典型的分类问题,有许多方法对数据集进行过采样,最常见的技术是SMOTE(Synthetic Minority Over-sampling Technique,合成少数类过采样技术)。简单地说,就是在少数类数据点的特征空间里,根据随机选择的一个K最近邻样本随机地合成新样本。
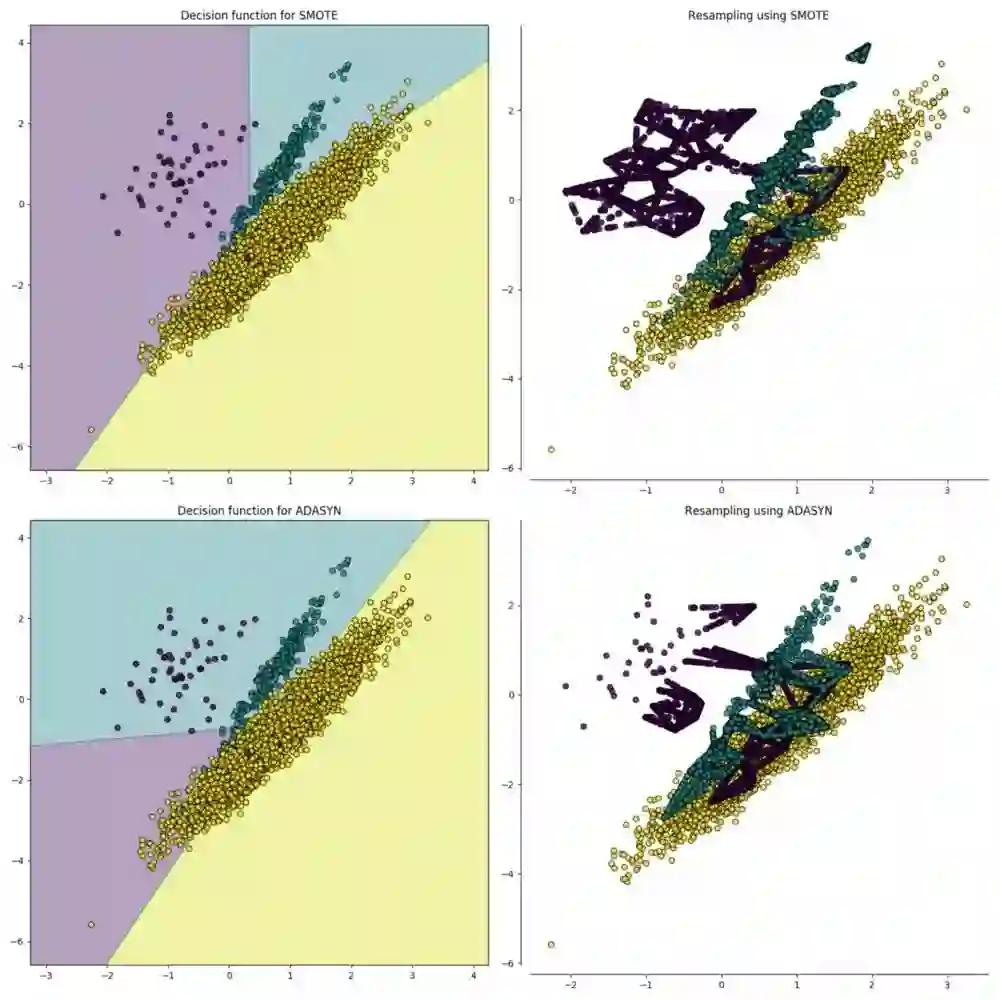
相关链接:
https://imbalanced-learn.readthedocs.io/en/stable/over_sampling.html
为了用python编码,我调用了imbalanced-learn 库(或imblearn),实现SMOTE的代码如下:
imbalanced-learnhttps://imbalanced-learn.readthedocs.io/en/stable/index.htmlfrom imblearn.over_sampling import SMOTE# Resample the minority class. You can change the strategy to 'auto' if you are not sure.sm = SMOTE(sampling_strategy='minority', random_state=7)# Fit the model to generate the data.oversampled_trainX,oversampled_trainY=sm.fit_sample(credit_df.drop('Class', axis=1), credit_df['Class'])oversampled_train=pd.concat([pd.DataFrame(oversampled_trainY), pd.DataFrame(oversampled_trainX)], axis=1)oversampled_train.columns = normalized_df.columns
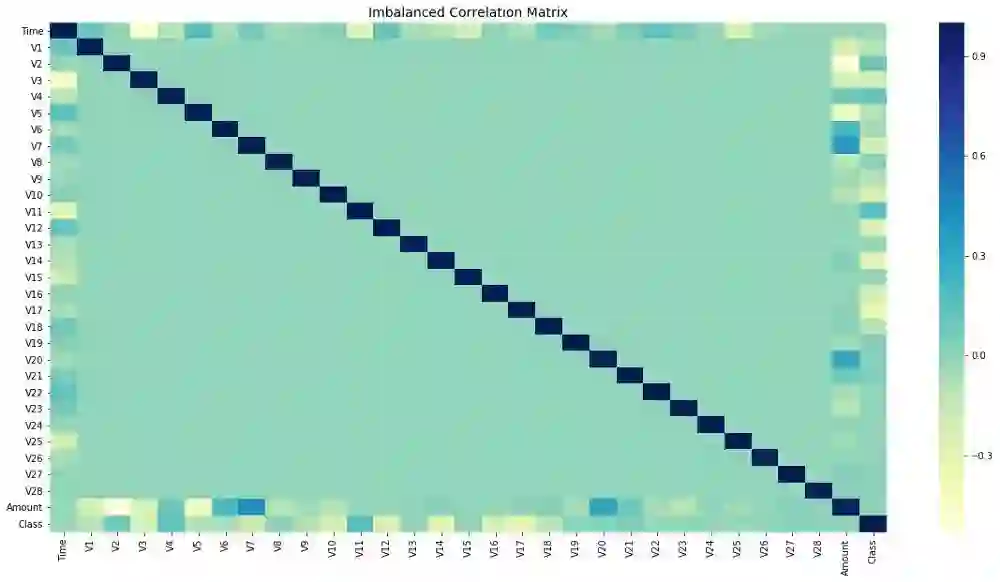
还记得我说过不平衡的数据会影响特征相关性吗?让我向您展示处理不平衡类问题前后的特征相关性。
重采样之前:
下面的代码用来绘制所有特征之间的相关矩阵:
# Sample figsize in inchesfig, ax = plt.subplots(figsize=(20,10))# Imbalanced DataFrame Correlationcorr = credit_df.corr()sns.heatmap(corr, cmap='YlGnBu', annot_kws={'size':30}, ax=ax)ax.set_title("Imbalanced Correlation Matrix", fontsize=14)plt.show()
重采样之后:
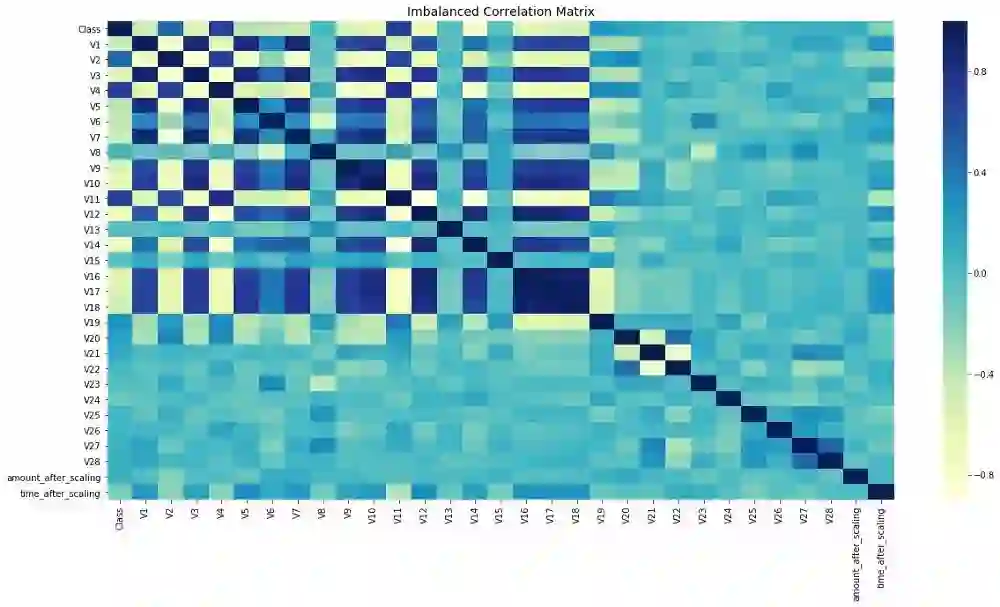
请注意,现在特征相关性更明显了。在解决不平衡问题之前,大多数特征并没有显示出相关性,这肯定会影响模型的性能。除了会关系到整个模型的性能,特征性相关性还会影响ML模型的性能,因此修复类别不平衡问题非常重要。
相关链接:
https://towardsdatascience.com/why-feature-correlation-matters-a-lot-847e8ba439c4
集成方法(采样器集成)
在机器学习中,集成方法会使用多种学习算法和技术,以获得比单独使用其中一个算法更好的性能(是的,就像一个民主投票系统)。当使用集合分类器时,bagging方法变得流行起来,它通过构建多个分类器在随机选择的不同数据集上进行训练。在scikit-learn库中,有一个名叫“Bagging Classifier”的集成分类器,然而这个分类器不能训练不平衡数据集。当训练不平衡数据集时,这个分类器将会偏向多数类,从而创建一个有偏差的模型。
为了解决这个问题,我们可以使用imblearn库中的BalancedBaggingClassifier。它允许在训练集成分类器中每个子分类器之前对每个子数据集进行重采样。
BalancedBaggingClassifierhttps://mp.weixin.qq.com/cgi-bin/appmsg?t=media/appmsg_edit&action=edit&type=10&isMul=1&isNew=1&lang=zh_CN&token=89565677#imblearn.ensemble.BalancedBaggingClassifier
因此,BalancedBaggingClassifier除了需要和Scikit Learn BaggingClassifier相同的参数以外,还需要2个参数sampling_strategy和replacement来控制随机采样器的执行。下面是具体的执行代码:
from imblearn.ensemble import BalancedBaggingClassifierfrom sklearn.tree import DecisionTreeClassifier#Create an object of the classifier.bbc = BalancedBaggingClassifier(base_estimator=DecisionTreeClassifier(),sampling_strategy='auto',replacement=False,random_state=0)y_train = credit_df['Class']X_train = credit_df.drop(['Class'], axis=1, inplace=False)#Train the classifier.y_train)preds = bbc.predict(X_train)
使用集合采样器训练不平衡数据集
这样,您就可以训练一个分类器来处理类别不平衡问题,而不必在训练前手动进行欠采样或过采样。
总之,每个人都应该知道,建立在不平衡数据集上的ML模型会难以准确预测稀有点和少数点,整体性能会受到限制。因此,识别和解决这些点的不平衡对生成模型的质量和性能是至关重要的。
原文链接:
https://www.kdnuggets.com/2019/05/fix-unbalanced-dataset.html
实习/全职编辑记者招聘ing
加入我们,亲身体验一家专业科技媒体采写的每个细节,在最有前景的行业,和一群遍布全球最优秀的人一起成长。坐标北京·清华东门,在大数据文摘主页对话页回复“招聘”了解详情。简历请直接发送至zz@bigdatadigest.cn