
如何使用大模型来进行检索优化?看这篇综述就够了

作为信息获取的主要手段,如搜索引擎等信息检索(IR)系统已经融入了我们的日常生活。这些系统还作为对话、问答和推荐系统的组件。
信息检索的轨迹从其基于术语的方法的起源动态地发展到与先进的神经模型的整合。虽然神经模型擅长捕捉复杂的上下文信号和语义细微差别,从而重塑信息检索的格局,但它们仍然面临如数据稀缺、可解释性以及生成上下文可能的但可能不准确的回应等挑战。
这种演变需要结合传统方法(如基于术语的稀疏检索方法与快速响应)和现代神经结构(如具有强大语言理解能力的语言模型)。与此同时,大型语言模型(LLMs),如ChatGPT和GPT-4,由于其出色的语言理解、生成、概括和推理能力,已经革命性地改变了自然语言处理。
因此,最近的研究已经寻求利用LLMs来改进IR系统。鉴于这一研究轨迹的快速发展,有必要整合现有的方法并通过全面的概述提供细致的见解。
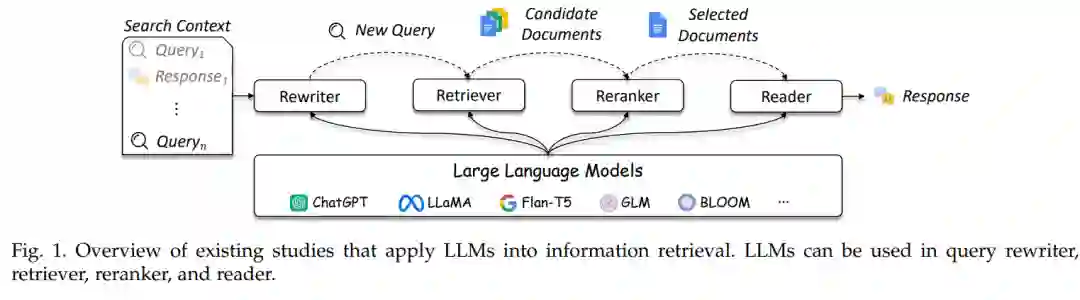
在这项综述中,我们深入探讨了LLMs和IR系统的融合,包括查询重写器、检索器、重新排序器和读取器等关键方面。此外,我们还探讨了这个不断扩展领域内的有前景的方向。
https://www.zhuanzhi.ai/paper/cfc9d30dab451b42c356f809ecf111a6
大模型驱动的信息检索
信息访问是人类日常基本需求之一。为了满足快速获取所需信息的需求,开发了各种信息检索(IR)系统[1–4]。显著的例子包括Google、Bing和Baidu等搜索引擎,它们在互联网上作为IR系统,擅长根据用户查询检索相关的网页,并为用户提供便捷、高效地访问互联网上的信息。值得注意的是,信息检索超出了网页检索的范围。在对话系统(聊天机器人)[1, 5-8]中,如微软的小冰[2]、苹果Siri1和Google助手2,IR系统在检索与用户输入语言相应的适当回应中起到了关键作用,从而产生自然流畅的人机对话。同样,在问答系统[3, 9]中,为了有效地解答用户的问题,IR系统被用来选择相关的线索。在图像搜索引擎[4]中,IR系统擅长返回与用户输入查询相符的图片。鉴于信息的指数级增长,研究和产业对开发有效的IR系统越来越感兴趣。
IR系统的核心功能是检索,其目的是确定用户发出的查询与待检索的内容之间的相关性,包括文本、图像、音乐等各种类型的信息。在本综述的范围内,我们仅专注于审查那些文本检索系统,其中查询与文档的相关性通常由它们的匹配得分来衡量。3考虑到IR系统操作大量的知识库,检索算法的效率变得至关重要。为了提高用户体验,检索性能从上游(查询重构)和下游(重新排序和阅读)的角度得到了增强。作为一个上游技术,查询重构旨在优化用户的查询,使其更有效地检索到相关的文档[10, 11]。随着会话式搜索的日益受欢迎,这种技术受到了越来越多的关注。在下游方面,重新排序方法被开发出来,以进一步调整文档的排名[12-14]。与检索阶段相比,重新排序仅在检索器已经检索到的有限集合的相关文档上执行。在这种情况下,重点放在实现更高的性能而不是保持更高的效率,允许在重新排序过程中应用更复杂的方法。此外,重新排序可以满足其他特定的需求,如个性化[15-18]和多样化[19-22]。在检索和重新排序阶段之后,加入了一个阅读组件,用于总结检索到的文档并为用户提供简洁的文档[23, 24]。虽然传统的IR系统通常要求用户自己收集和整理相关信息;但是,阅读组件是New Bing等新IR系统的一个不可分割的部分,简化了用户的浏览体验,节省了宝贵的时间。
信息检索(IR)的轨迹经历了动态的演变,从其基于术语的方法的起源转变为与神经模型的整合。最初,IR基于基于术语的方法[25]和布尔逻辑,专注于为文档检索进行关键词匹配。随着向量空间模型[26]的引入,这一范式逐渐发生了变化,释放出捕获术语之间细微的语义关系的潜力。这种进展随着统计语言模型[27, 28]继续发展,通过上下文和概率考虑来改进相关性估计。在这一阶段,有影响力的BM25算法[29]起到了重要作用,通过考虑术语频率和文档长度的变化,彻底改变了相关性排名。IR历程中的最新篇章是由神经模型的崛起[3, 30-32]标志的。这些模型擅长捕获复杂的上下文提示和语义细节,重塑了IR的格局。然而,这些神经模型仍然面临如数据稀缺、可解释性以及可能生成合理但不准确回应等挑战。因此,IR的演变仍然是一个平衡传统优势(如BM25算法的高效率)与现代神经结构所带来的显著能力(如语义理解)的旅程。
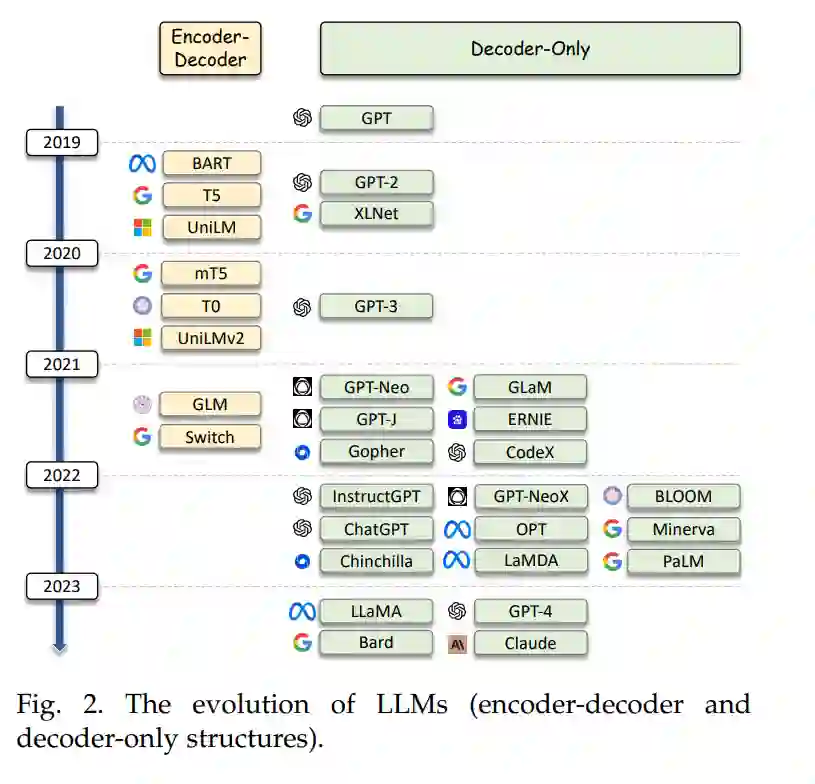
近年来,大型语言模型(LLMs)已在各种研究领域,如自然语言处理(NLP)[33-35]、推荐系统[36-39]、金融[40],甚至分子发现[41]中崭露头角,成为变革的力量。这些前沿的LLMs主要基于Transformer架构,并在各种文本源上进行广泛的预训练,包括网页、研究文章、书籍和代码。随着它们的规模继续扩展(包括模型大小和数据量),LLMs在其能力上展现出了显著的进步。一方面,LLMs在语言理解和生成方面展现出了前所未有的熟练程度,从而产生更像人类的响应,并更好地与人类的意图对齐。另一方面,更大的LLMs在处理复杂任务[42]时展示了令人印象深刻的突发能力,如泛化和推理技能。值得注意的是,LLMs可以有效地应用其学到的知识和推理能力,只需几个针对特定任务的示范或适当的指导即可解决新任务[43, 44]。此外,如基于上下文的学习这样的先进技术,已经大大增强了LLMs的泛化性能,无需对特定的下游任务进行微调[34]。这一突破尤为宝贵,因为它减少了大量的微调需求,同时获得了显著的任务性能。通过使用如“思维链”这样的提示策略,LLMs可以生成带有逐步推理的输出,导航复杂的决策过程[45]。无疑,利用LLMs的强大力量可以提高IR系统的性能。通过整合这些复杂的语言模型,IR系统可以为用户提供更准确的回应,从根本上重塑信息访问和检索的格局。
已经进行了初步的尝试,以利用LLMs在开发新型IR系统中的潜力。值得注意的是,就实际应用而言,New Bing旨在通过从不同的网页中提取信息,并将其压缩成简洁的摘要作为用户生成查询的响应,从而改进用户使用搜索引擎的体验。在研究界,LLMs已在IR系统的特定模块(如检索器)中证明了其用途,从而增强了这些系统的整体性能。由于LLM增强型IR系统的迅速发展,全面审查它们的最新进展和挑战至关重要。我们的综述提供了对LLMs和IR系统交叉点的深入探索,涵盖了关键视角,如查询重写器、检索器、重新排名器和读取器(如图1所示)。这项分析加深了我们对LLMs在推进IR领域中的潜力和局限性的理解。为了这次综述,我们创建了一个Github仓库,收集了有关LLM4IR的相关论文和资源。我们将继续使用新的论文更新仓库。此综述也将根据此领域的发展定期进行更新。我们注意到有几篇关于PLMs、LLMs及其应用(例如AIGC或推荐系统)的综述[46–52]。在这些中,我们强烈推荐LLMs的综述[52],它为LLMs的许多重要方面提供了系统而全面的参考。与它们相比,我们专注于为IR系统开发和应用LLMs的技术和方法。此外,我们注意到有一篇观点论文讨论了IR在遇到LLMs时的机会[53]。这将是关于未来方向的本次综述的极好补充。
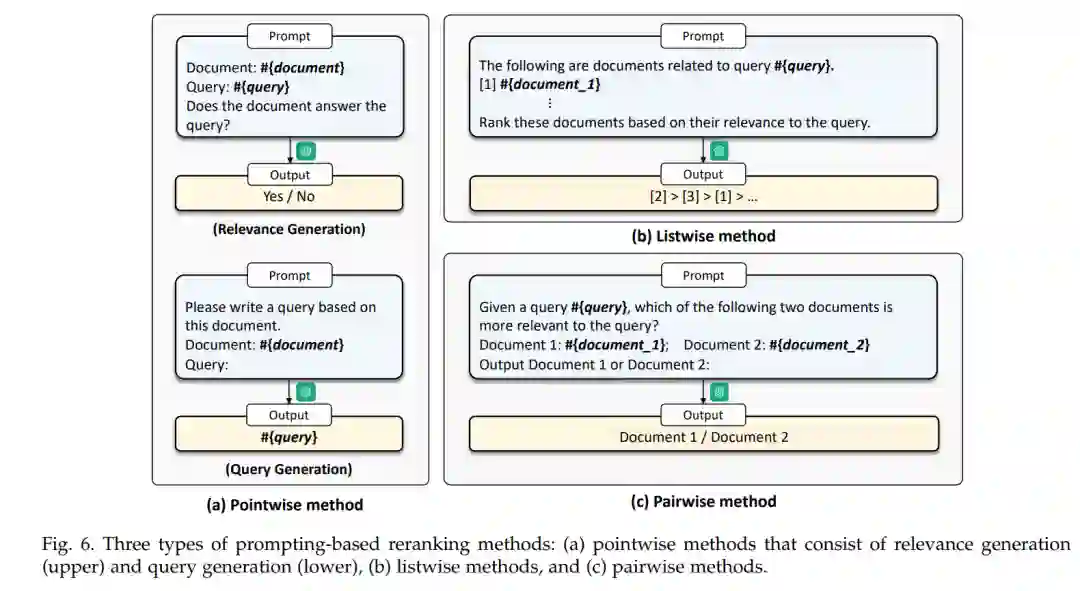
此综述的其余部分组织如下:第2部分介绍IR和LLMs的背景。第3、4、5、6部分分别从查询重写器、检索器、重新排名器和读取器的四个视角审查了最近的进展,这是IR系统的四个关键组件。然后,第7部分讨论了未来研究中的一些可能方向。最后,我们在第8部分总结了主要发现,结束这次综述。
结论
在这项综述中,我们对LLMs在IR的多个维度上的变革影响进行了深入的探索。我们根据它们的功能将现有方法组织成不同的类别:查询重写、检索、重新排序和读取模块。在查询重写领域,LLMs已经展示了其在理解模糊或多面的查询方面的有效性,增强了意图识别的准确性。在检索的背景下,LLMs通过使查询和文档之间的匹配更加细致,同时考虑上下文,提高了检索的准确性。在重新排序领域,LLM增强的模型在重新排序结果时考虑了更多的语言细节。在IR系统中加入读取模块代表了向生成综合性回应而不仅仅是文档列表的重要一步。LLMs的整合到IR系统带来了用户与信息和知识互动方式的根本变化。从查询重写到检索,重新排序和读取模块,LLMs已经通过高级语言理解、语义表示和上下文敏感处理丰富了IR过程的每一个方面。随着这一领域的不断进展,LLMs在IR中的旅程预示着一个更加个性化、精确和以用户为中心的搜索体验的未来。这项综述着重于审查最近的将LLMs应用于不同信息检索组件的研究。除此之外,LLMs的出现带来了一个更大的问题:在LLMs的时代,传统的IR框架是否还有必要?例如,传统的IR旨在返回与发出的查询相关的文档的排名列表。然而,生成语言模型的发展引入了一个新的范例:直接生成对输入问题的答案。此外,根据最近的一篇观点论文[53],IR可能会演变为多种系统的基本服务。例如,在一个多代理模拟系统[162]中,IR组件可以用于记忆回忆。这意味着未来的IR将会有许多新的挑战。


