
在监督模式下训练的深度模型在各种任务上都取得了显著的成功。在标记样本有限的情况下,自监督学习(self-supervised learning, SSL)成为利用大量未标记样本的新范式。SSL在自然语言和图像学习任务中已经取得了很好的效果。最近,利用图神经网络(GNNs)将这种成功扩展到图数据的趋势。
在本综述论文中,我们提供了使用SSL训练GNN的不同方法的统一回顾。具体来说,我们将SSL方法分为对比模型和预测模型。
在这两类中,我们都为方法提供了一个统一的框架,以及这些方法在框架下的每个组件中的不同之处。我们对GNNs SSL方法的统一处理揭示了各种方法的异同,为开发新的方法和算法奠定了基础。我们还总结了不同的SSL设置和每个设置中使用的相应数据集。为了促进方法开发和实证比较,我们为GNNs中的SSL开发了一个标准化测试床,包括通用基线方法、数据集和评估指标的实现。
https://www.zhuanzhi.ai/paper/794d1d27363c4987efd37c67ec710a18
引言
深度模型以一些数据作为输入,并训练输出期望的预测。训练深度模型的一种常用方法是使用有监督的模式,在这种模式中有足够的输入数据和标签对。
然而,由于需要大量的标签,监督训练在许多现实场景中变得不适用,标签是昂贵的,有限的,甚至是不可用的。
在这种情况下,自监督学习(SSL)支持在未标记数据上训练深度模型,消除了对过多注释标签的需要。当没有标记数据可用时,SSL可以作为一种从未标记数据本身学习表示的方法。当可用的标记数据数量有限时,来自未标记数据的SSL可以用作预训练过程,在此过程之后,标记数据被用来为下游任务微调预训练的深度模型,或者作为辅助训练任务,有助于任务的执行。
最近,SSL在数据恢复任务中表现出了良好的性能,如图像超分辨率[1]、图像去噪[2,3,4]和单细胞分析[5]。它在语言序列[6,7,8]、图像[9,10,11,12]、带有序列模型的图[13,14]等不同数据类型的表示学习方面也取得了显著进展。这些方法的核心思想是定义前置训练任务,以捕获和利用输入数据的不同维度之间的依赖关系,如空间维度、时间维度或通道维度,具有鲁棒性和平滑性。Doersch等人以图像域为例,Noroozi和Favaro[16],以及[17]等人设计了不同的前置任务来训练卷积神经网络(CNNs)从一幅图像中捕捉不同作物之间的关系。Chen等人的[10]和Grill等人的[18]训练CNN捕捉图像的不同增强之间的依赖关系。
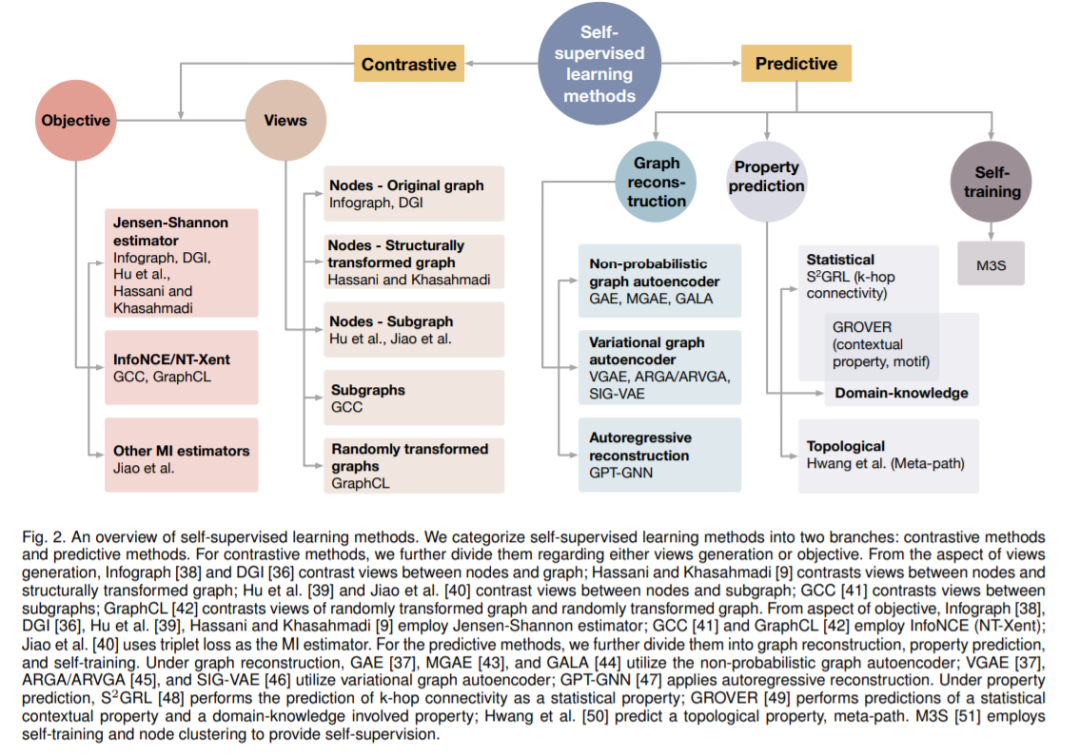
根据训练任务的设计,SSL方法可以分为两类;即对比模型和预测模型。这两个类别之间的主要区别是对比模型需要数据-数据对来进行训练,而预测模型需要数据-标签对,其中标签是自生成的,如图1所示。对比模型通常利用自监督来学习数据表示或对下游任务进行预训练。有了这些数据-数据对,对比模型就能区分出正面对和负面对。另一方面,预测模型是在监督的方式下训练的,其中标签是根据输入数据的某些属性或选择数据的某些部分生成的。预测模型通常由一个编码器和一个或多个预测头组成。当应用于表示学习或预训练方法时,预测模型的预测头在下游任务中被删除。
在图数据分析中,SSL可能非常重要,它可以利用大量未标记的图,如分子图[19,20]。随着图神经网络的快速发展[21,22,23,24,25,26,27],图神经网络的基本组成[28,29,30,31,32,33]等相关领域[34,35]得到了深入的研究,并取得了长足的进展。相比之下,在GNNs上应用SSL仍然是一个新兴领域。由于数据结构的相似性,很多GNN的SSL方法都受到了图像领域方法的启发,如DGI[36]和图自动编码器[37]。然而,由于图结构数据的唯一性,在GNN上应用SSL时存在几个关键的挑战。为了获得良好的图表示并进行有效的预训练,自监督模型可以从图的节点属性和结构拓扑中获取必要的信息。对于对比模型来说,由于自监督学习的GPU内存问题并不是图形的主要关注点,关键的挑战在于如何获得良好的图形视图以及针对不同模型和数据集的图形编码器的选择。对于预测模型,至关重要的是应该生成什么标签,以便了解非平凡的表示,以捕获节点属性和图结构中的信息。
为了促进方法论的发展和促进实证比较,我们回顾GNN的SSL方法,并为对比和预测方法提供了统一的观点。我们对这一问题的统一处理,可以揭示现有方法的异同,启发新的方法。我们还提供了一个标准化的测试,作为一个方便和灵活的开源平台,用于进行实证比较。我们将本次综述论文总结如下:
-
我们提供关于图神经网络SSL方法的彻底和最新的回顾。据我们所知,我们的综述查首次回顾了关于图数据的SSL。
-
我们将GNN现有的对比学习方法与一般框架统一起来。具体来说,我们从互信息的角度统一对比目标。从这个新的观点来看,不同的对比学习方式可以看作是进行三种转换来获得观点。我们回顾了理论和实证研究,并提供见解来指导框架中每个组成部分的选择。
-
我们将SSL方法与自生成标签进行分类和统一,作为预测学习方法,并通过不同的标签获取方式来阐明它们之间的联系和区别。
-
我们总结了常用的SSL任务设置以及不同设置下常用的各类数据集,为未来方法的发展奠定了基础。
-
我们开发了一个用于在GNN上应用SSL的标准化测试平台,包括通用基准方法和基准的实现,为未来的方法提供了方便和灵活的定制。


