当前的深度学习研究以基准评价为主。如果一种方法在专门的测试集上有良好的经验表现,那么它就被认为是有利的。这种心态无缝地反映在持续学习的重现领域,在这里研究的是持续到达的基准数据集。核心挑战是如何保护之前获得的表示,以免由于迭代参数更新而出现灾难性地遗忘的情况。然而,各个方法的比较是与现实应用程序隔离的,通常通过监视累积的测试集性能来判断。封闭世界的假设仍然占主导地位。假设在部署过程中,一个模型保证会遇到来自与用于训练的相同分布的数据。这带来了一个巨大的挑战,因为众所周知,神经网络会对未知的实例提供过于自信的错误预测,并在数据损坏的情况下崩溃。在这个工作我们认为值得注意的教训来自开放数据集识别,识别的统计偏差以外的数据观测数据集,和相邻的主动学习领域,数据增量查询等预期的性能收益最大化,这些常常在深度学习的时代被忽略。基于这些遗忘的教训,我们提出了一个统一的观点,以搭建持续学习,主动学习和开放集识别在深度神经网络的桥梁。我们的结果表明,这不仅有利于每个个体范式,而且突出了在一个共同框架中的自然协同作用。我们从经验上证明了在减轻灾难性遗忘、主动学习中查询数据、选择任务顺序等方面的改进,同时在以前提出的方法失败的地方展示了强大的开放世界应用。
https://www.zhuanzhi.ai/paper/e5bee7a1e93a93ef9139966643317e1c

概述:
随着实用机器学习系统的不断成熟,社区发现了对持续学习[1]、[2]的兴趣。与广泛练习的孤立学习不同,在孤立学习中,系统的算法训练阶段被限制在一个基于先前收集的i.i.d数据集的单一阶段,持续学习需要利用随着时间的推移而到来的数据的学习过程。尽管这种范式已经在许多机器学习系统中找到了各种应用,回顾一下最近关于终身机器学习[3]的书,深度学习的出现似乎已经将当前研究的焦点转向了一种称为“灾难性推理”或“灾难性遗忘”的现象[4],[5],正如最近的评论[6],[7],[8],[9]和对深度持续学习[8],[10],[11]的实证调查所表明的那样。后者是机器学习模型的一个特殊效应,机器学习模型贪婪地根据给定的数据群更新参数,比如神经网络迭代地更新其权值,使用随机梯度估计。当包括导致数据分布发生任何变化的不断到达的数据时,学习到的表示集被单向引导,以接近系统当前公开的数据实例上的任何任务的解决方案。自然的结果是取代以前学到的表征,导致突然忘记以前获得的信息。
尽管目前的研究主要集中在通过专门机制的设计来缓解持续深度学习中的这种遗忘,但我们认为,一种非常不同形式的灾难性遗忘的风险正在增长,即忘记从过去的文献中吸取教训的危险。尽管在连续的训练中保留神经网络表示的努力值得称赞,但除了只捕获灾难性遗忘[12]的度量之外,我们还高度关注了实际的需求和权衡,例如包括内存占用、计算成本、数据存储成本、任务序列长度和训练迭代次数等。如果在部署[14]、[15]、[16]期间遇到看不见的未知数据或小故障,那么大多数当前系统会立即崩溃,这几乎可以被视为误导。封闭世界的假设似乎无所不在,即认为模型始终只会遇到与训练过程中遇到的数据分布相同的数据,这在真实的开放世界中是非常不现实的,因为在开放世界中,数据可以根据不同的程度变化,而这些变化是不现实的,无法捕获到训练集中,或者用户能够几乎任意地向系统输入预测信息。尽管当神经网络遇到不可见的、未知的数据实例时,不可避免地会产生完全没有意义的预测,这是众所周知的事实,已经被暴露了几十年了,但是当前的努力是为了通过不断学习来规避这一挑战。选择例外尝试解决识别不可见的和未知的示例、拒绝荒谬的预测或将它们放在一边供以后使用的任务,通常总结在开放集识别的伞下。然而,大多数现有的深度连续学习系统仍然是黑盒,不幸的是,对于未知数据的错误预测、数据集的异常值或常见的图像损坏[16],这些系统并没有表现出理想的鲁棒性。
除了目前的基准测试实践仍然局限于封闭的世界之外,另一个不幸的趋势是对创建的持续学习数据集的本质缺乏理解。持续生成模型(如[17]的作者的工作,[18],[19],[20],[21],[22]),以及类增量持续学习的大部分工作(如[12]中给出的工作,[23],[24],[25],[26],[27],[28])一般调查sequentialized版本的经过时间考验的视觉分类基准如MNIST [29], CIFAR[30]或ImageNet[31],单独的类只是分成分离集和序列所示。为了在基准中保持可比性,关于任务排序的影响或任务之间重叠的影响的问题通常会被忽略。值得注意的是,从邻近领域的主动机器学习(半监督学习的一种特殊形式)中吸取的经验教训,似乎并没有整合到现代的连续学习实践中。在主动学习中,目标是学会在让系统自己查询接下来要包含哪些数据的挑战下,逐步地找到与任务解决方案最接近的方法。因此,它可以被视为缓解灾难性遗忘的对抗剂。当前的持续学习忙于维护在每个步骤中获得的信息,而不是无休止地积累所有的数据,而主动学习则关注于识别合适的数据以纳入增量训练系统的补充问题。尽管在主动学习方面的早期开创性工作已经迅速识别出了通过使用启发式[32]、[33]、[34]所面临的强大应用的挑战和陷阱,但后者在深度学习[35]、[36]、[37]、[38]的时代再次占据主导地位,这些挑战将再次面临。
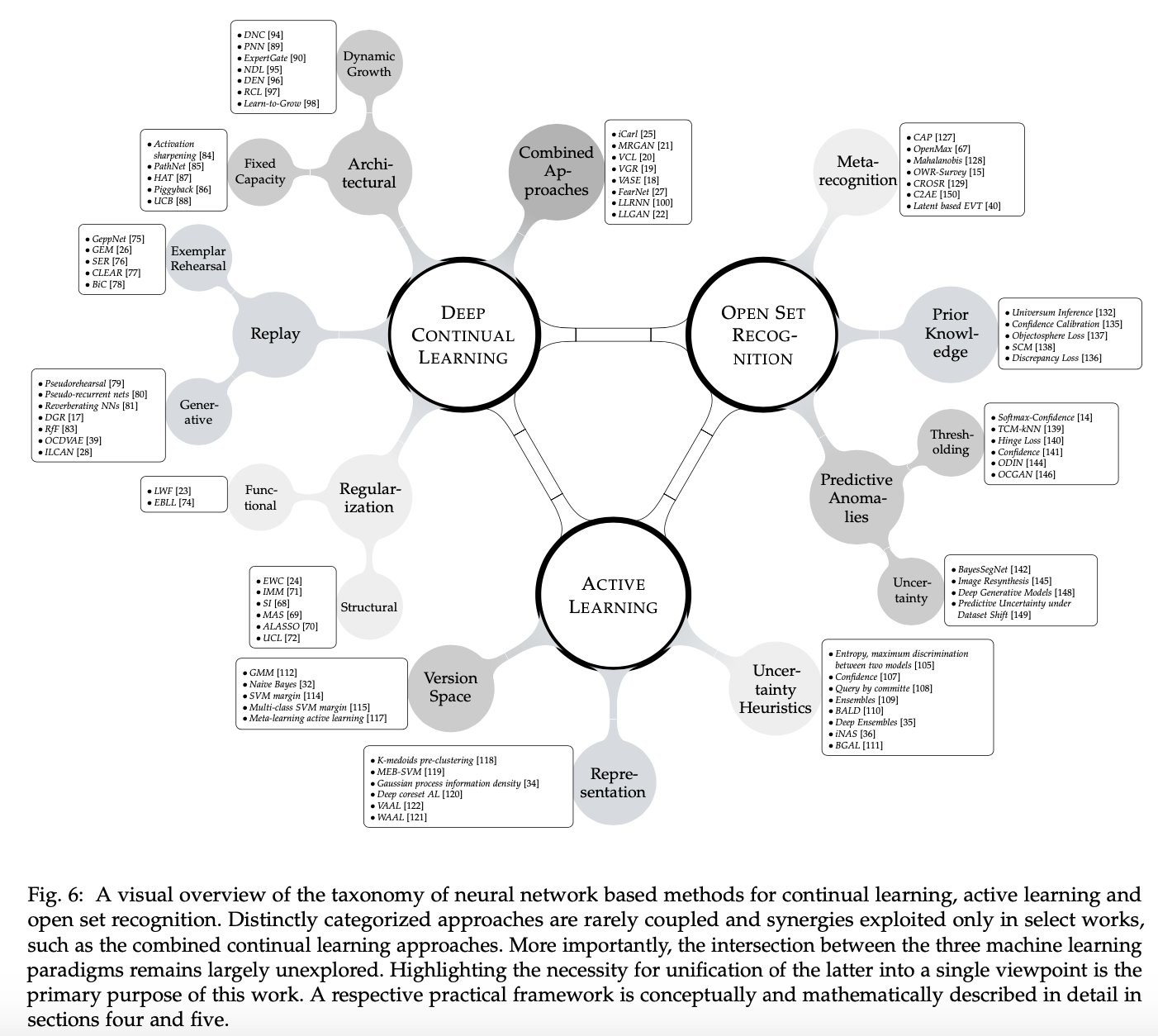
在这项工作中,我们第一次努力建立一个原则性和巩固的深度持续学习、主动学习和在开放的世界中学习的观点。我们首先单独回顾每一个主题,然后继续找出在现代深度学习中似乎较少受到关注的以前学到的教训。我们将继续争论,这些看似独立的主题不仅从另一个角度受益,而且应该结合起来看待。在这个意义上,我们建议将当前的持续学习实践扩展到一个更广泛的视角,将持续学习作为一个总括性术语,自然地包含并建立在先前的主动学习和开放集识别工作之上。本文的主要目的并不是引入新的技术或提倡一种特定的方法作为通用的解决方案,而是对最近提出的神经网络[39]和[40]中基于变分贝叶斯推理的方法进行了改进和扩展,以说明一种走向全面框架的可能选择。重要的是,它作为论证的基础,努力阐明生成建模作为深度学习系统关键组成部分的必要性。我们强调了在这篇论文中发展的观点的重要性,通过实证证明,概述了未来研究的含义和有前景的方向。