基于自编码器的表征学习:如何攻克半监督和无监督学习?
选自NeurIPS 2018
作者:Michael Tschannen等
机器之心编译
参与:Panda
苏黎世联邦理工学院和谷歌大脑团队研究者的 NeurIPS 2018 会议贝叶斯深度学习(Bayesian Deep Learning)研讨会论文《Recent Advances in Autoencoder-Based Representation Learning》系统性地介绍了基于自编码器的表征学习的最新进展。
为了将人工智能应用于从世界收集的大量无标注数据,一大关键难题是要能仅用少量监督或无监督的学习方法来学习有用的表征。尽管在数据上学习到的表征的有用性显然很大程度上取决于其所针对的最终任务,但仍可想见有些表征的性质可同时用于很多真实世界任务。在一篇有关表征学习的开创性论文中,Bengio et al. [1] 提出了这样一组元先验(meta-prior)。这些元先验来自对世界的一般性假设,比如解释性元素的层次化组织形式或解离性(disentanglement)、半监督学习的可能性、数据在低维流形上的汇集、可聚类性、时间和空间一致性。
近段时间,研究者们已提出了多种基于自编码思想的(无监督)表征学习算法;这种思想的目标是学习从高维观察到低维表征空间的映射,使得可通过低维的表征(近似地)重建出原来的观察。尽管这些方法有各不相同的目标和设计选择,但我们认为这篇论文介绍的所有方法本质上都隐式或显式地围绕着来自 Bengio et al. [1] 的一个元先验。
鉴于上游表征学习任务本质上的无监督性,表征学习步骤中强制执行的元先验的特性能决定所得到的表征对真实世界最终任务的有用程度。因此,为了强制执行给定的元先验,需要理解哪种模型和哪种通用技术针对哪种元先验是有用的。在这篇论文中,我们提供了一种统一视角,其中包含大多数已提出的模型并给出了它们与 Bengio et al. [1] 中提出的元先验的关系。我们在表 1 中总结了近期在元先验方面的研究工作。
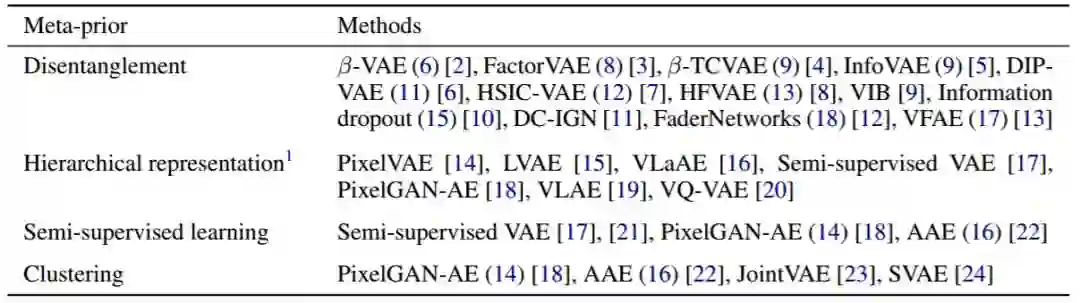
表 1:根据 [1] 中的用于表征学习的元先验分组的方法。尽管很多方法都直接或间接地解决了多个元先验,但我们仅考虑了每种方法中最显著的目标。注意,本质上所有方法都会强制使用低维和流形结构等元先验。
Bengio et al. [1] 的元先验。元先验有关于这个世界的非常通用的前提条件,因此也被认为可用于范围广泛的下游任务。我们简要地总结了我们审阅过的方法所针对的最重要的元先验。
解离性:假设数据是基于互相独立的因素(这些因素内部也存在一定的变化范围)生成的,比如目标图像中的目标方向和光照条件,作为一个元先验,解离性更倾向于用表征中不同的独立变量表示这些因素。这样应该就能得到数据的简洁的抽象表示,从而可用于各种下游任务并有望提升样本效率。
解释性因素的层次化组织形式:这一元先验背后的直观知识是这个世界可以被描述为越来越抽象概念的层次结构。比如自然图像可以在不同层次的粒度上根据图中的目标进行抽象的描述。给定目标,可由目标的属性给出更具体的描述。
半监督学习:半监督学习思想是在监督学习任务和无监督学习任务之间共享表征,这通常会带来协同效应:尽管有标注数据点的数量通常过小,不足以学习得到优良的预测器(也没有优良的表征),但与无监督目标一起联合训练能让监督任务学习到可泛化的表征,同时监督任务还能引导表征学习过程。
聚类结构:很多真实世界数据集都有多类结构(比如具有不同目标类别的图像),这些结构可能具有各不相同的与类别有关的因素(这些因素内部也存在一定的变化范围)。这种结构可由隐含混合模型学习得到,其中每种混合组分都对应一种类别,并且其分布也能建模该类别之中的因素的变化情况。这能自然地得到具有聚类结构的表征。
平滑度(smoothness)与时间空间的一致性等非常通用的概念并不特定于无监督学习,并且可在大多数实际设置中使用(比如有助于预测器平滑度的权重衰减,以及用于获取图像数据中空间一致性的卷积层。我们将在第 7 节讨论大多数方法使用的隐式监督。
用于强制执行元先验的机制。我们识别出了以下三种强制执行元先验的机制:
编码分布的正则化(第 3 节)。
编码和解码分布或模型族的选择(第 4 节)。
灵活的表征的先验分布的选择(第 5 节)。
比如,编码分布的正则化通常被用于促进使用解离后的表征。另外,以一种层次化的方式分解编码和解码分布让我们可以将层次结构施加到表征上。最终,可使用一种更加灵活的先验(比如一种混合分布)来促进可聚类能力。
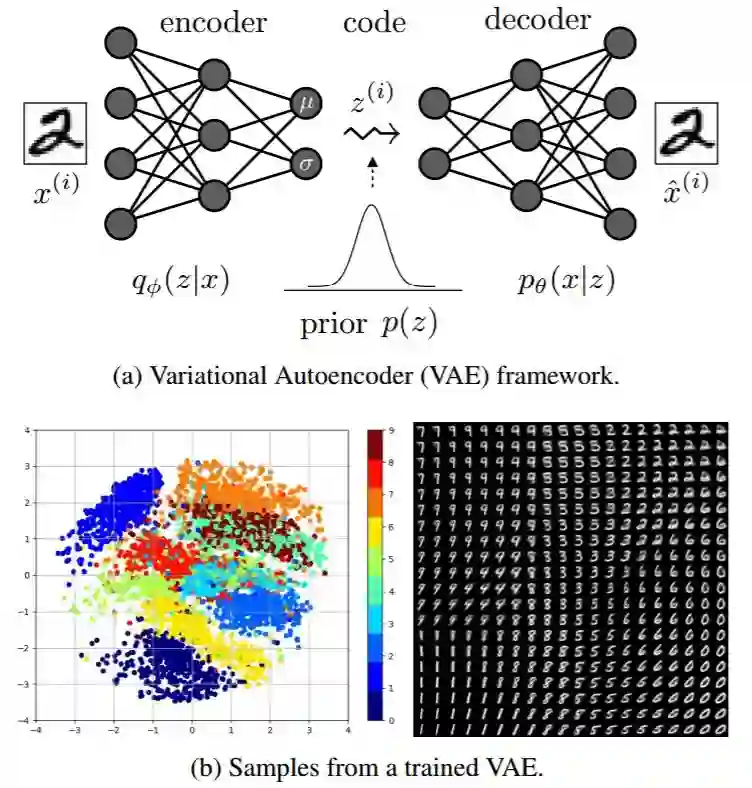
图 1:图(a)说明了编码器、解码器和先验分布在隐含(表征/代码)空间上指定的变分自编码器(VAE)框架。编码器是将输入映射到表征空间(推理),而解码器则是根据表征重建原输入。编码器应该满足该隐含空间上的某些结构(比如应该是解离的)。图(b)展示了在 MNIST 数据集上训练后的具有二维隐含空间的自编码器。左图中的每个点都对应于一个数字的表征(原来有 784 个维度),右图是重建出的数字。
可以看到,这个案例中的隐含表征是有聚类的(多种风格的同一数字在 L2 距离上很接近,而在每一组中,位置都对应于数字的旋转)。
在开始我们的概述之前,我们在第 2 节给出了理解变分自编码器(VAE)[25, 26] 所需的主要概念、本论文中考虑过的大多数基础方法以及用于估计概率分布之间的散度的多种技术。然后我们会在第 3 节详细讨论基于正则化的方法,在第 4 节介绍依赖结构化的编码和解码分布的方法,在第 5 节介绍使用结构化先验分布的方法。我们在第 6 节通过概述跨领域表征学习 [27-29] 等相关方法而进行了总结。最后,我们在第 7 节通过 Alemi et al. [30] 的数据率-失真(rate-distortion)框架评判了无监督表征学习并探讨了其意义。
论文:基于自编码器的表征学习近期进展(Recent Advances in Autoencoder-Based Representation Learning)

论文地址:https://arxiv.org/abs/1812.05069
摘要:在很少或没有监督的情况下学习有用的表征是人工智能领域的一大关键挑战。我们以基于自编码器的模型为核心,对表征学习的最新进展进行了深度概述。为了组织这些结果,我们使用了据信对下游任务有用的元先验,比如特征的解离性和层次结构。具体而言,我们揭示了三种强制实现这些属性的主要机制:(1)正则化(近似的或聚合的)后验分布,(2)分解编码和解码分布,(3)引入一个结构化的先验分布。尽管已有一些有希望的结果,但隐式或显式的监督仍然是一个关键推动因素,所有现有方法都使用了较强的归纳偏置且有建模方面的假设前提。最后,我们还通过数据率-失真理论对基于自编码器的表征学习进行了分析,并确定了下游任务相关先验知识可用量与该表征在该任务中的有用程度之间的明确权衡。
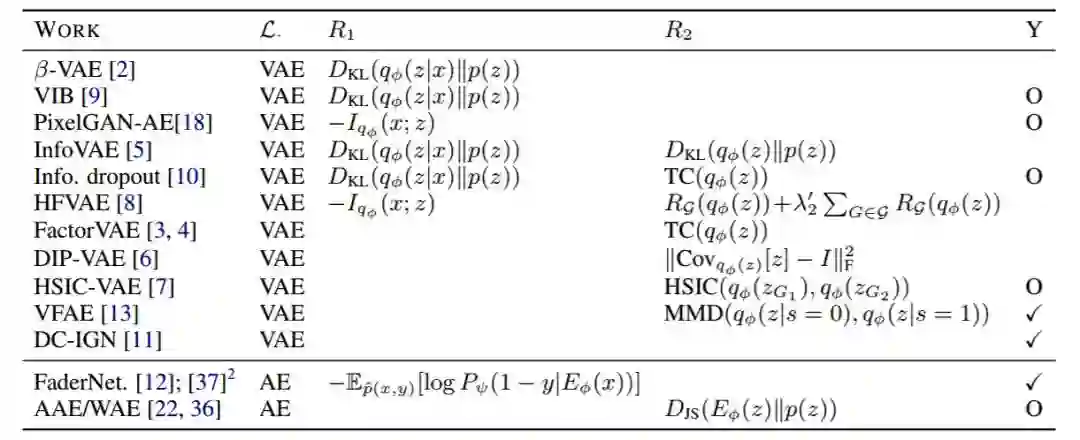
表 2:选择了不同正则化方法 和 的研究概述。[5] 中的学习目标是指定的。大多数方法都使用了多变量标准正态分布作为先验(更多详情见附录表 3)。最后一列「Y」表示是否使用了监督:√ 表示需要标签,O 表示标签是可选择使用的(从而实现监督或半监督学习)。注意某些正则化算法经过了简化。

图 3:不同正则化算法的示意图概述。大多数方法都侧重于正则化聚合的后验,而在测量先验的分歧的方法各有不同。表 2 提供了更多细节,深度讨论见第 3 节。
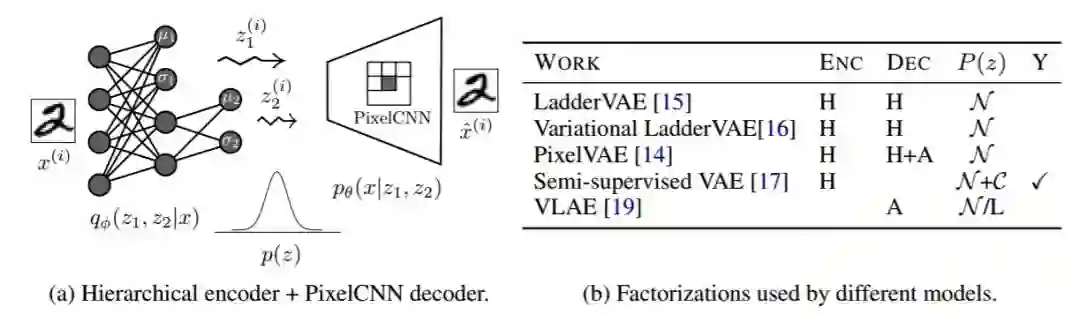
图 5:图(a)展示了一个带有层次编码分布和 PixelCNN 解码分布的 VAE 示例,图(b)给出了不同模型所用的分解方法概况。我们表示编码(ENC)和解码(DEC)分布的结构的方式为:H 表示层次,A 表示自回归,(默认)是全连接或卷积的前馈式神经网络。我们表示后验部分的方式为:N 表示多变量标准正态分布,C 表示类别式,M 表示混合分布,G 表示图模型,L 表示学习得到的先验。最后一列「Y」表示是否使用了监督。
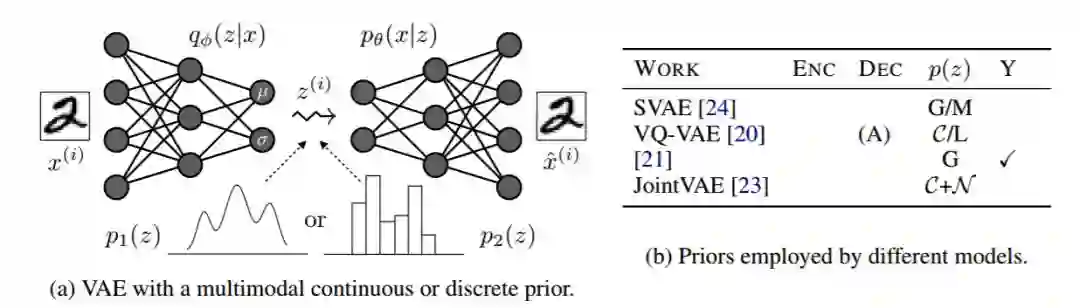
图 6:图(a)展示了一个带有多模态连续或离散先验(每个先验都会产生一个不同的模型)的 VAE 示例。图(b)给出了不同模型使用的先验的概况。
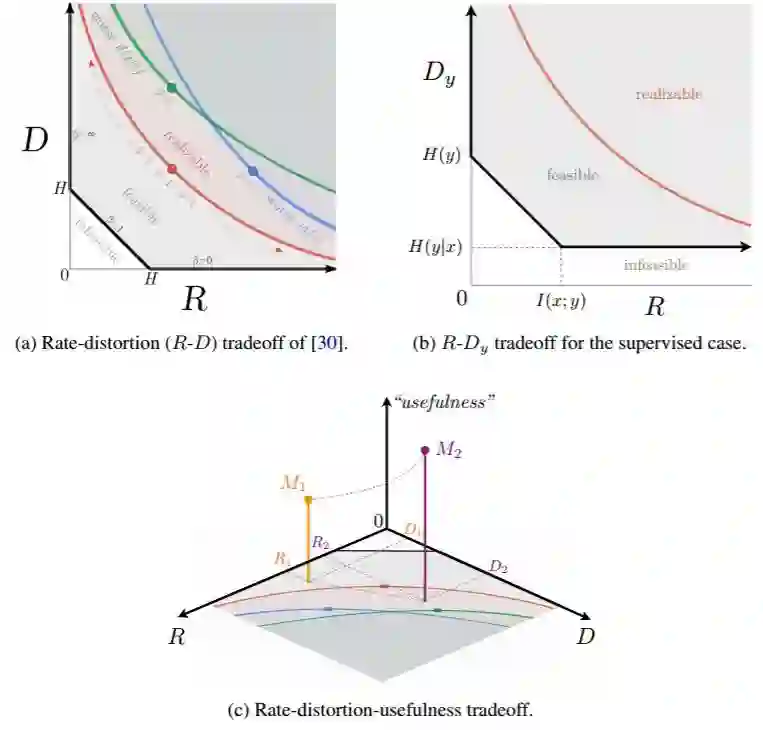
图 7:图(a)展示了 [30] 的数据率-失真权衡,其中 D 对应 (β-)VAE 目标中的重建项,R 对应 KL 项。图(b)展示了 [10,9] 中的监督式案例的一个相似的权衡。如图(c)所示,不能反映所学到的表征对未知下游任务的有用程度。

本文为机器之心编译,转载请联系本公众号获得授权。
✄------------------------------------------------
加入机器之心(全职记者 / 实习生):hr@jiqizhixin.com
投稿或寻求报道:content@jiqizhixin.com
广告 & 商务合作:bd@jiqizhixin.com


