

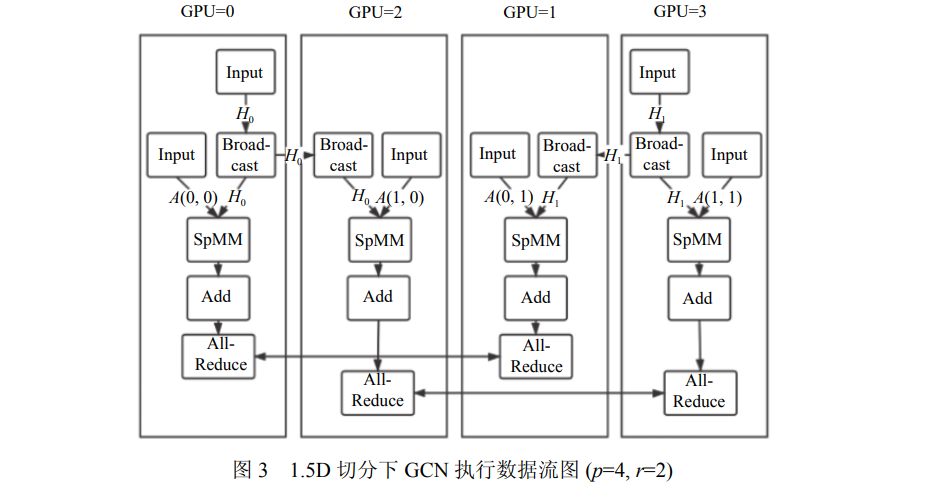
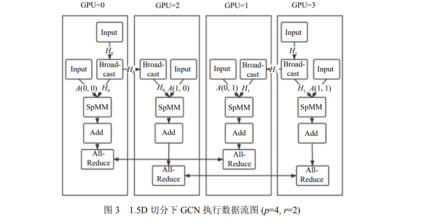
图神经网络由于其强大的表示能力和灵活性最近取得了广泛的关注. 随着图数据规模的增长和显存容量的限制, 基于传统的通用深度学习系统进行图神经网络训练已经难以满足要求, 无法充分发挥GPU设备的性能. 如何高效利用GPU硬件进行图神经网络的训练已经成为了该领域重要的研究问题之一. 传统做法是基于稀疏矩阵乘法, 完成图神经网络中的计算过程, 当面对GPU显存容量限制时, 通过分布式矩阵乘法, 把计算任务分发到每个设备上, 这类方法的主要不足有: (1)稀疏矩阵乘法忽视了图数据本身的稀疏分布特性, 计算效率不高; (2)忽视了GPU本身的计算和访存特性, 无法充分利用GPU硬件. 为了提高训练效率, 现有一些研究通过图采样方法, 减少每轮迭代的计算带价和存储需求, 同时也可以支持灵活的分布式拓展, 但是由于采样随机性和方差, 它们往往会影响训练的模型精度. 为此, 提出了一套面向多GPU的高性能图神经网络训练框架, 为了保证模型精度, 基于全量图进行训练, 探索了不同的多GPU图神经网络切分方案, 研究了GPU上不同的图数据排布对图神经网络计算过程中GPU性能的影响, 并提出了稀疏块感知的GPU访存优化技术. 基于C++和CuDNN实现了该原型系统, 在4个不同的大规模GNN数据集上的实验表明: (1)通过图重排优化, 提高了GPU约40%的缓存命中率, 计算加速比可达2倍; (2)相比于现有系统DGL, 取得了5.8倍的整体加速比.
成为VIP会员查看完整内容
相关内容

相关VIP内容
相关资讯
相关论文