

今天给大家介绍 Meta(Facebook) AI Research 团队 2022 年发表在 ICLR 上的论文 “TOWARDS TRAINING BILLION PARAMETER GRAPH NEURAL NETWORKS FOR ATOMIC SIMULATIONS”。本文针对原子模拟领域,提出了一种图并行框架,可以分布式的在多 GPU 上训练十亿级参数量的超大图神经网络模型。在标准数据集 OC20 上最高实现了 21% 的性能提升。
Part1摘要
用于原子模拟建模的图神经网络(GNNs)的最新进展有可能彻底改变催化剂的发现,这是朝着应对气候变化所需的能源突破取得进展的关键一步。然而,被证明对这项任务最有效的GNN是内存密集型的,因为它们在图中模拟高阶相互作用,例如三重或四重原子之间的相互作用,因此很难拓展这些模型。在本文中,我们提出了一种图并行方案,这是一种将输入图分布在多个 GPU 上的方法,使我们能够训练具有数亿或数十亿参数的超大 GNN。我们通过将最近提出的 DimeNet++ 和 GemNet 模型的参数数量增加一个数量级以上,对我们的方法进行了实证评估。在大规模开放式 Catalyst 2020(OC20)数据集上,我们提出的图并行在 S2EF 任务的 MAE指标相对提高了15%,在 IS2RS 任务的 AFbT 指标相对提高了21%,实现了新的 SOTA。
Part2前言
图神经网络(GNNs)已成为原子系统建模的标准体系结构,从蛋白质结构预测到催化剂发现和药物设计,有着广泛的应用。这些模型对图结构输入进行操作,其中图的节点表示原子,边表示键或原子邻居。尽管它们取得了广泛的成功,并且拥有大量的分子数据集,但训练大规模的GNN(具有数十亿个参数)是一个重要但尚未得到充分探索的领域。计算机视觉、自然语言处理和语音识别领域类似大型模型的成功表明,扩大 GNN 的规模可以显著提高性能。 以前大多数扩展 GNN 的方法都专注于将小模型(具有数百万个参数)扩展到大图,产生了邻域采样等方法。但这些方法不适用于包含数百万个较小图的原子模拟数据集。我们的重点是针对由许多中等大小的图组成的数据集,扩展到非常大的模型的问题。
Part3方法
Battaglia et al.(2018)介绍了一种称为图网络(GN)的框架,该框架为许多流行的图神经网络(GNN)提供了一般抽象,这些网络在图的边和节点表示上运行。本文以他们的工作为基础,定义了扩展图网络(EGN)框架,以包括也在高阶项上运行的 GNN,如三元组或四元组节点。 在 GN 框架中,图被定义为一个三元组 , 其中 表示关于整个图的全局属性。GNN 包含一系列 GNblocks,这些 GNblocks 对输入图进行迭代操作,更新各种表示。在 Extended Graph Network (EGN) 框架中,图被定义为一个四元组 , 表示高阶相互作用项的集合。 作为一个具体的例子,考虑在这个框架中用图表示的原子系统,节点表示原子,边表示原子邻居。节点属性 和边属性 可以分别表示原子的原子数和原子之间的距离。更高阶的相互作用可以表示原子的三元组,即成对的相邻边,其中 表示键角,键角是共享一个公共节点的边之间的角度。最后,全局属性 可以表示系统的能量。

在 EGN 框架中,GNN 包含一系列的 EGN 块,迭代的更新图中的表示,如上图所示,从最高阶的关系项开始更新,逐步到最低阶,直到完成整个图的更新,一次迭代完成。(上图中,最高阶为三元关系,边为二元关系,节点为一元关系)。 即使在中等大小的图上训练大型 EGN 也具有挑战性,因为存储和更新每个三元组、边和节点的表示需要大量内存占用。在许多应用中,边的数量比节点的数量大一到两个数量级,而三元组的数量比边的数量大一到两个数量级。因此,存储和更新三元组表示通常是 GPU 内存和计算方面的瓶颈。许多最新的研究使用低维表示来克服这一问题。但会损失性能。
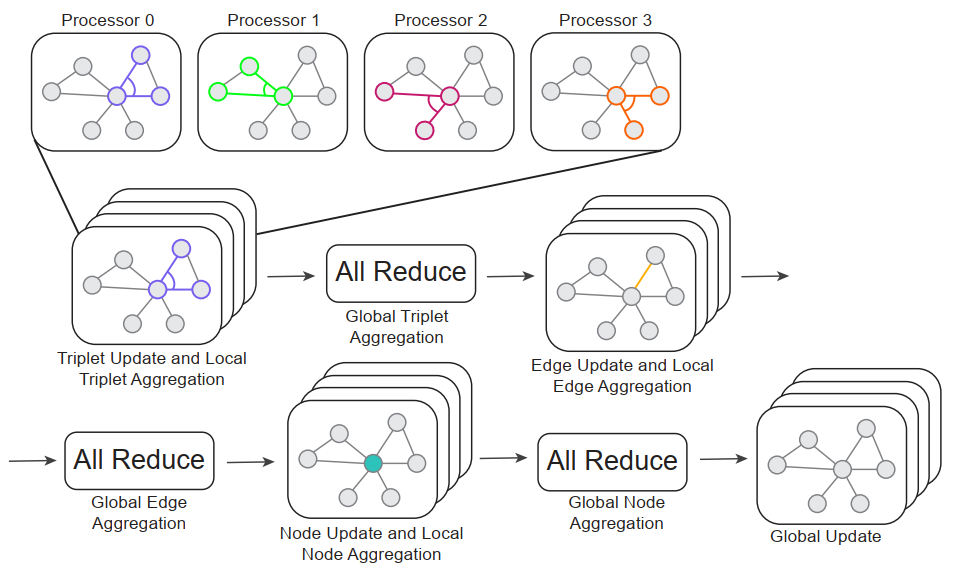
本文使用分布式 EGN 块的实现。假设我们有 P 个处理单元。每个单元负责计算对三元组、边和节点子集的更新。在计算开始时,我们将图拆分为子集。在前向传递时,P 个处理单元并行的更新三元组的子集,并进行局部聚集。然后进行 reduce 操作实现全局聚集。剩下的低阶关系聚集是相似的,整个过程如上图所示。 基于这一分布式的框架,本文给出了两个使用 GNN 预测原子系统能量和力的具体示例,将分子建模为一个图,其节点表示原子,其边表示原子的邻居。GNN 将这样的图作为输入,并预测整个系统的能量以及每个原子上的三维力矢量。
Part4结果
本文使用 OC20 数据集,其包含超过 1.3 亿个原子结构,用于训练模型,预测结构松弛期间的力和能量。我们报告了三项任务的结果:
- 1)Structure to Energy and Forces (S2EF),包括预测给定结构的能量和力;
- 2)Initial Structure to Relaxed Energy(IS2RE),预测给定初始结构的弛豫能量;
- 3)Initial Structure to Relaxed Structure(IS2RS),使用预测的力执行结构松弛。 三项任务的实验结果如下:

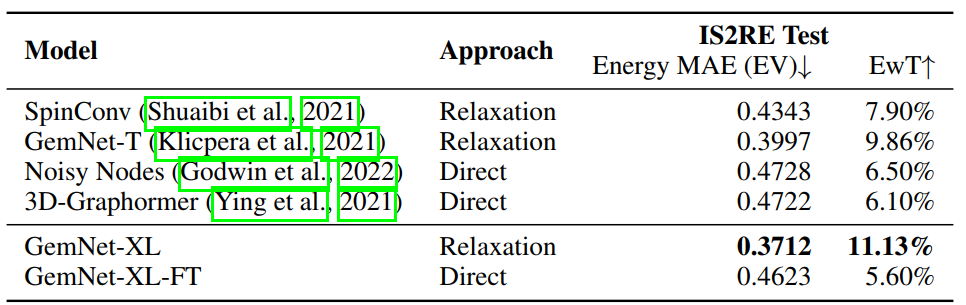

未来,作者希望将图并行 (graph parallelism)和模型并行 (例如 GPipe)的方法相结合,来训练更大的模型,以产生更好的性能。 参考文献

