深度上下文词向量


近年来深度学习在 NLP 领域成绩斐然,无论是情感分类、语言模型、机器翻译或是阅读理解,基于深度学习的方法都取得了快速的进展,将机器理解语言的能力推到了一个新的高度。而在基于深度模型的方法中,词如何表示是第一个要解决的问题。目前比较通行的方式是词表示方法是词向量(word embedding),例如 Google 的 Word2vec 和 Stanford 的 GloVe ,它们提供了词向量的训练方法和在大规模语料上预训练好的词向量。这些预训练的词向量能够学习到大规模无监督语料中蕴含的词的语义和语法信息,在各种主流的深度学习模型中作为对词的基本表示,都取得了非常好的效果。
然而,词向量训练只能学习到上下文无关的,单个词的固定表示。也就是说,同一个词“play”,在表示“玩耍”的上下文中和表示“剧作”的上下文中,它的词向量是一样的,虽然“play”这个词的词向量中可能同时包含了两种不同的意思,但是词所在的上下文信息非常重要,如果能将上下文信息融合进词的表示,对于模型真正理解这个词一定更有帮助。
我们为大家介绍一篇来自AllenAI的文章,是2018年NAACL的最佳论文,它提出了一种基于语言模型的词向量算法ELMo (Embeddings from Language Models)。ELMo能够灵活的将词的上下文信息编码进词向量,在命名实体识别、阅读理解等多个任务上都取得了显著的提升。我们会介绍怎么把ELMo代码应用到自己的tensorflow程序中。
与传统的词向量不同, 对于一个句子中的任意一个词,ELMo不再学习一个词的固定表示,而是学习一个词向量的函数:
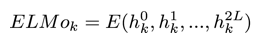
这个函数的每个输入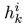
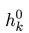
语言模型是用来计算一个句子在自然语言中出现概率的模型。正向的语言模型通过一个句子中的前 k-1 个词来预测第 k 个词出现的概率,从而将整个句子出现的概率建模为:
而反向的语言模型通过给定第 k+1 到第 N 个词来预测第 k 个词的概率,最终句子整体的概率可以表示为:
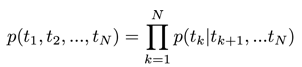
ELMo 在预训练语言模型时使用了双向的 LSTM 来分别建模两个方向上每个词出现的概率,最终优化如下的损失函数:
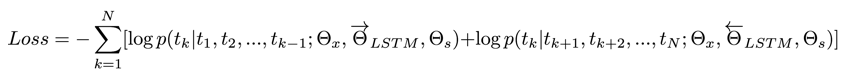
其中 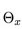
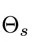
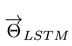
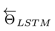
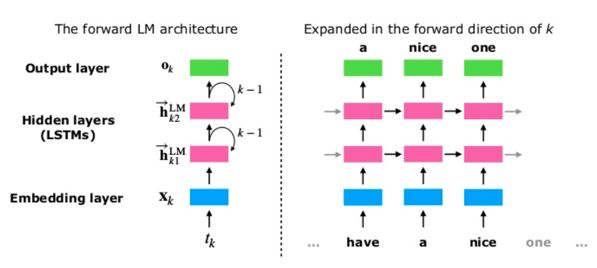
图1. 一个前向的LSTM语言模型示例
语言模型是一个无监督模型,从上面的定义也很容易看出,我们只需要自然语言的句子,而不需要其他的标注信息即可训练语言模型,这使得我们可以使用非常大的语料来进行训练。而 LSTM 以能够出色的解决长距离依赖而闻名,双向 LSTM 能够很好的编码词的上下文信息。基于双向 LSTM 的语言模型通过在大规模的无监督语料上进行充分的预训练,得到的模型预期可以很好的表示词的上下文信息。
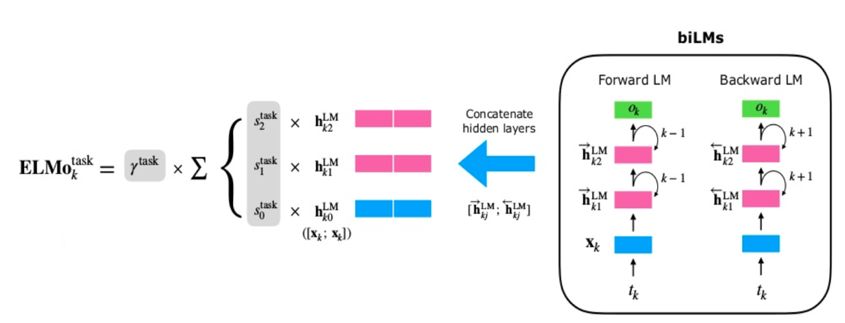
图2.ELMo计算过程
假设预训练的双向语言模型有 2L+1 层(词向量也算一层),那么对于第 k 个词,我们就可以得到一个向量表示的集合:
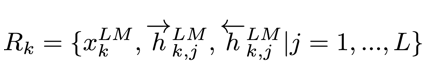
其中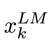
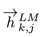
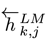
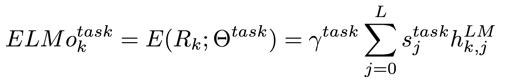
其中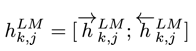
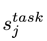
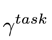
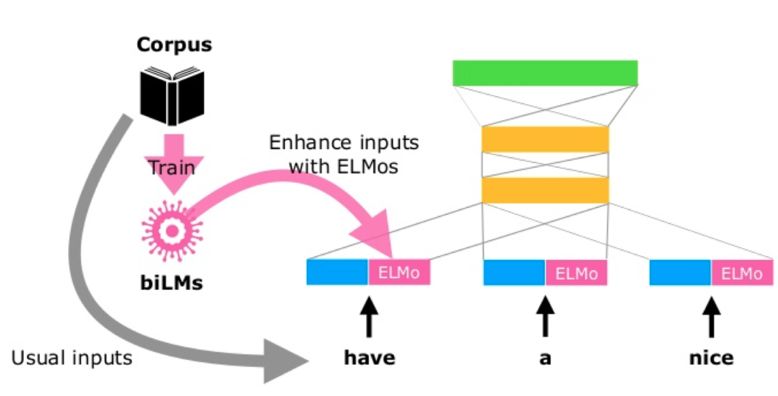
图3.ELMo使用流程
当我们得到了在大规模语聊上预训练好的语言模型后,就可以在监督任务上使用 ELMo了。图3. 展示了 ELMo 训练和使用的整体流程。大部分基于深度学习的 NLP 模型在最底层都会共享一个预训练的词向量,比如 GloVe ,随后会使用一个 RNN 或者 CNN 来对句子做一个编码,这样每个时间步上都可以得到一个包含一定上下文信息的向量表示。ELMo 可以在网络的最底层与原有的词向量拼接,然后将这个增强的词向量输入的模型的其余部分,例如 图3. 所示,ELMo 也可以应用在模型中间的 RNN/CNN 的输出结果上。除了在 ELMo 计算的时候引入额外的参数,模型的其它部分可以保持不变。在实际操作层面,文章通过实验还发现了一些 ELMo 使用的技巧,例如使用 dropout 和 L2 正则化,更详细的信息请参考文章内容。AllenAI 已经将在大规模语料上预训练好的语言模型开放,需要使用的读者可以参考:
https://github.com/allenai/allennlp/blob/master/tutorials/how_to/elmo.md
(Pytorch)。
Tensorflow代码也开源在:
https://github.com/allenai/bilm-tf
本篇文章作者做了很扎实的实验,在 6 个主流的 NLP 任务上使用了 ELMo ,均在当前的 SOTA 效果上得到了进一步提升,目前 ELMo 已经逐渐成为了阅读理解等任务中的标准组件。详细的实验数据见表 1.
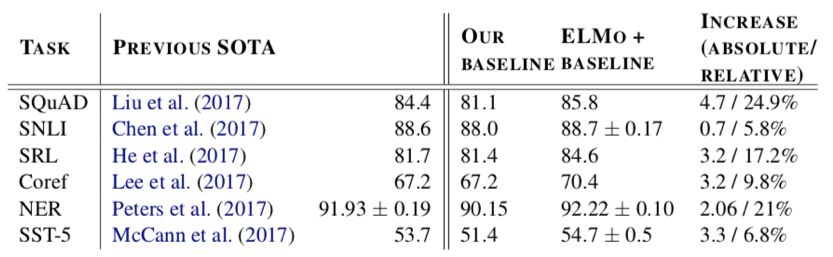

表 2.ELMo 词向量与 GloVe 词向量的对比
如本文开头所述,在不同的上下文中,传统词向量的同一个词的表示是相同的,表 2. 的第一行展示了 “play” 这个词在 GloVe 向量中的最近邻的词,可以看到除了时态的变化之外,大多数都集中在运动相关的概念。而 ELMo 在不同的上下文中,对同一个词有不同的表示,表 2. 的下面两行展示了在不同的上下文中,ELMo 向量相近的 “play” ,可以看到,第二行两句都是运动相关,而第三行两句都是剧目相关。这个例子说明 ELMo 确实可以学到包含更多上下文的词向量。
看过 ELMo 的理论原理,我们来看一下如何把 github 上的代码模块应用到自己的 tensorflow 程序中。首先我们需要:
下载 (tensorflow 版本)
https://github.com/allenai/bilm-tf
预备 tensorflow 1.4 和 python 3.5 或以上的环境 (可以利用 anaconda3 安装虚拟环境)。Python2.7 也是可以的,但需要稍微修改一下 bilm/data.py 。安装 h5py 。
从官方网站 ( https://allennlp.org/elmo ) 下载预训练好的模型 (weights.h5py & options.json),或利用自己的数据从新训练一个模型。
假如你已经写了一个 model.py 的文件,里面有一个深度学习的模型,首先我们在 model.py 的开始,import 需要的模块:

BidirectionalLanguageModel 就是那个双向的语言模型,weight_layers 就是用来合拼 bilm 中不同层的隐向量。下一步就是建立一个 BidirectionalLanguageModel 和 Batcher:
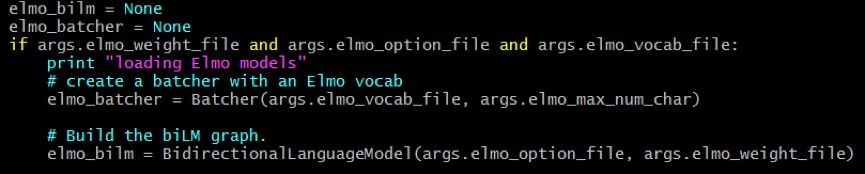
Batcher 主要是用来建立 minibatch, max_num_char 是表示词最长的 character个数,因为ELMo支持character embedding来处理Out-Of-Vocabulary(OOV) 问题,通过 UTF8 编码后,每一个词 token 是以 Byte 序列表示,然后用 CNN 进行编码,所以 elmo_vocab_file 几乎可以是任何你想编码的词。下面是一个 elmo_vocab_file 的例子:

其中 <S>, </S>, <UNK> 都需要在里面的,在训练 ELMo bilm 时,<S> 和 </S> 会自动加在每个句子的头和尾,所以输入的数据是不需要加这些符号的。
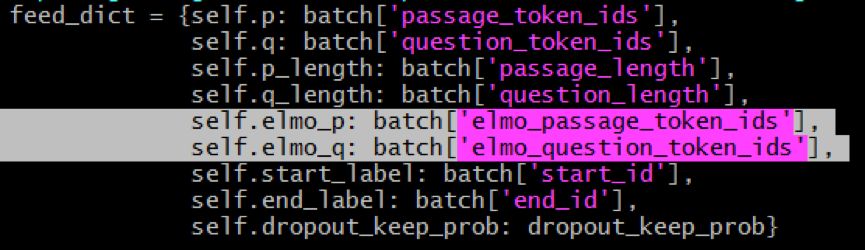
在阅读理解的任务中, question_tokens (q) & passage_tokens (p) 装了B个长度不一的句子 tokens (list维数是2), B 是batch size 。minibatch 是用下面的方法产生 (注意:输入的 tokens 是不需要做 padding ,输出的 token_ids 已做好 padding):

Elmo_passage_token_ids 是一个三维的 list 。然后,我们只需要透过 feed_dict 把 token ids 输入到 computation graph 就行:

然后在 build_graph 时,定义 tensorflow placeholder (Graph 的 tensor 输入) :

ELMo embedding 可以透过下面的函数实现 :
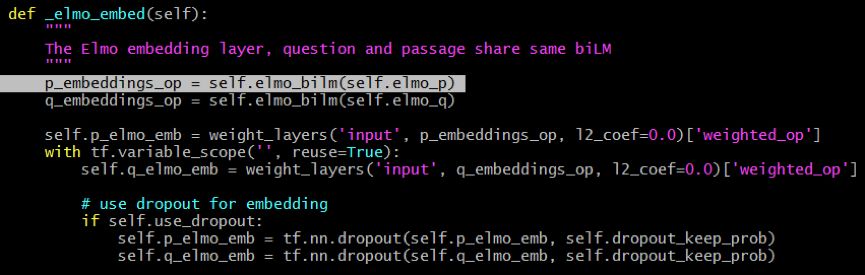
最后,ELMo embedding 可以按情况与词 embedding 合拼使用:
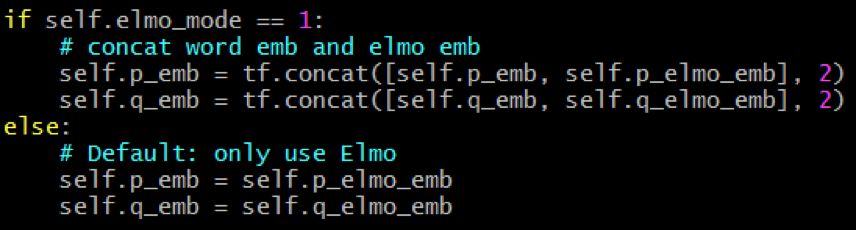
p_emb & q_emb 就连结到下游的 build_graph() 逻辑,一直到 loss 函数和其他相关的变量中。
►►小技巧:
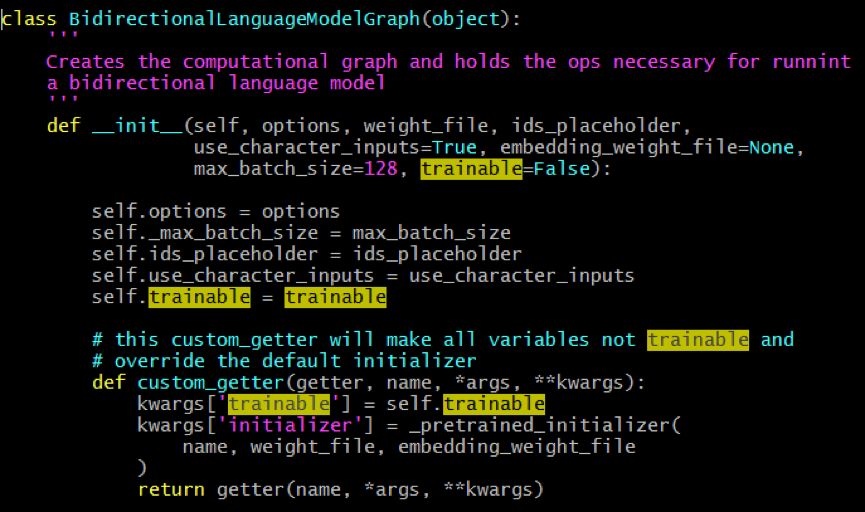
在 ELMo 代码中的,ELMo 中的参数都是预训练好的,所以在特定的 task 中,参数都是固定的。如果读者是希望用 task 数据更新 ELMo 所有的参数的话,是可以在 def custom_getter(.) 中做一些小修改 :
如果你的 task 需要处理很长的句子序列(例如阅读理解中的一篇文章),你可能会发现 ELMo 会占用很多的 GPU 内存,导致很容易就 OOM (Out-Of-Memory) , 可以考虑把 ELMo 放在另外一个 GPU ,甚至是 CPU 来运算。
bilm 的 scope 默认是空白的 ( Global scope ), 如果把上面的 def _elmo_embed() 放到其他的 tensorflow scope , 就会报错找不到 weight variables ,所以要多加注意。
ELMo 因其出色的性能和灵活的用法,现在已在越来越多 NLP 模型中成为标准组件。笔者认为 ELMo 首先向我们展示将上下文信息注入词向量带来的显著收益,同时,在近年来众多借助语言模型进行无监督预训练的工作中,ELMo 探索出来了一条比较通用且有效的做法。目前,AllenAI 已经开源了其预训练的语言模型和训练代码,这使得 ELMo 可以被更方便的应用到更多任务,感兴趣的读者,快快用起来吧!

 微信ID:WeChatAI
微信ID:WeChatAI
 长按左侧二维码关注
长按左侧二维码关注
登录查看更多
相关内容

专知会员服务
79+阅读 · 2019年12月29日
Arxiv
3+阅读 · 2019年8月22日




相关VIP内容
专知会员服务
79+阅读 · 2019年12月29日
相关资讯