哪种词向量模型更胜一筹?Word2Vec,WordRank or FastText?
“全球人工智能”拥有十多万AI产业用户,10000多名AI技术专家。主要来自:北大,清华,中科院,麻省理工,卡内基梅隆,斯坦福,哈佛,牛津,剑桥...以及谷歌,腾讯,百度,脸谱,微软,阿里,海康威视,英伟达......等全球名校和名企。
摘要: 本文在不同语料库下分析了FastText,Word2Vec和WordRank三种词嵌入模型的性能,发现没有单独的一种模型能够用于不同类型NLP任务。
在众多词嵌入(有的也称作词向量)模型中选择一个合适的模型是很困难的任务,是选择NLP常用的Word2Vec还是其他模型?如图1所示,用WordRank,Word2Vec和FastText三种模型分别找出与“king”最相似的词语,WordRank的结果更加倾向于“king”这个词本身的属性或者和“king”同时出现最多的词,而Word2Vec的结果多是和“king”出现在相似的上下文。

图1. WordRank, Word2Vec和FastText三种模型输出与"king"最相似的词
不同模型实验结果对比

图2. 三种模型实验结果对比
实验对比数据集:
1.使用Google类比数据集进行词类比实验,包含19K词类比问题,包含语义和语法类比;
2.使用SimLex-999和WS-353数据集进行词相似度实验,参考此处介绍。
从上表可以看出,每种模型用于不同任务时其效果表现出显著差异。如FastText在语法类比任务中效果最好,WordRank在语义类比任务中效果最好。其原因在于,FastText引入词的形态学信息,而WordRank则是把寻找最相似词形式化为一个排序问题。即,给定词w, WordRank输出一个序列化列表,将和词w共同出现最多的词排在列表前面。在词的相似度方面,Word2Vec在Simlex-999测试数据上表现效果更好,而wordrank在ws-353上表现更好。出现这些不同的结果可能是因为数据集使用了不同角度下的相似度,图1中三种模型输出"king"的最相似词的对比也说明了这些词嵌入模型对相似度理解方式的不同。
可视化比较
在使用TensorBoard对这三种词嵌入模型的结果进行可视化处理后,得出的结论和最开始三种模型的输出结果相似。TensorBoard使用PCA或者t-SNE方法将原始多维词向量降维至2维或者3维,原始词向量的信息会丢失一些,词之间的余弦相似度/距离会有所改变,但仍然是相关的,所以可视化的结果相对于图1中的结果会有所改变。
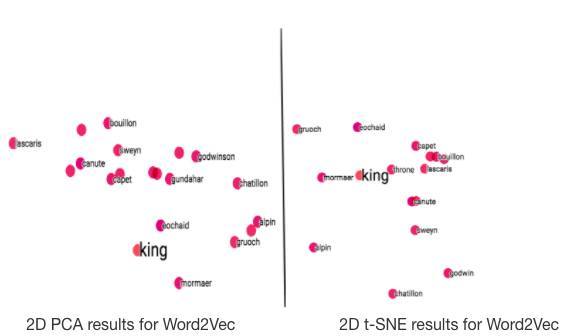


图3. 不同模型使用PCA与t-SNE的效果对比
从图3可以看出,在Word2Vec模型中,两种方法都表现不错。要注意的是,由于t-SNE是一种随机方法,所以即使是使用相同的参数设置,也可能得到不同结果。在FastText中,两种方法表现相似,稍次于Word2Vec。在WordRank模型上 ,t-SNE方法效果好于PCA,因为在PCA方法中,一些最相似的词反而在图中被置于较远的位置。
词频和模型性能
本节将会使用不同语料库分析不同词频范围上,词嵌入模型在词类比任务上的性能,如图4和图5所示。类比的四个词的平均频率会先算出来,然后和具有相似平均频率的类比一同存储。
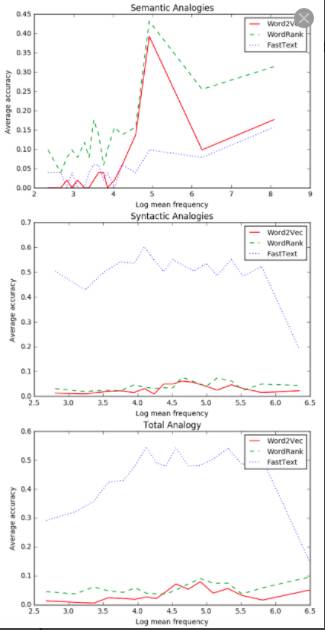
图4. 在 Brown corpus上,不同类比任务的准确率
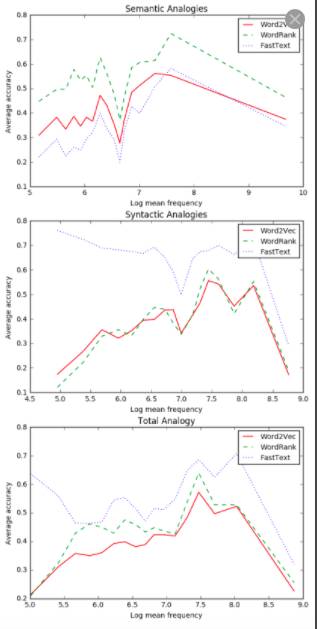
图5. 在 text8 corpus上,不同类比任务的准确率
由图4和图5分析表明:
1.在语义类比中,三种模型在低频词语上表现相对较差,在高频词语上表现效果较好;
2.在语法类比中,FastText优于Word2Vec和WordRank 。FastText模型在低频词语上表现的相当好,但是当词频升高时,准确率迅速降低,而WordRank和Word2Vec在很少出现和很频繁出现的词语上准确率较低;
3. FastText在综合类比中表现更好,最后一幅图说明整体类比结果与语法类比的结果比较相似,因为语法类比任务的数量远远多于语义类比,所以在综合结果中语法类比任务的结果占有更大的权重;
综上,WordRank更适合语义类比,FastText更适合不同语料库下所有词频的语法类比。
三种模型词类比
原文中作者展示了不同词向量模型在不同语料库(Brown corpus和text8)上进行类比任务的日志,结果表明WordRank在语义类比任务上效果优于其他两种模型,而FastText在语法类比上效果更好。值得一提的是,如果用WordRank模型生成两个集合(词集合和上下文集合),WordRank使用它们词向量的内积对他们之间的关系建模,内积和他们之间的关系是直接成比例的,如果该词和上下文越相关,内积就会越大。将两者结合考虑,如:
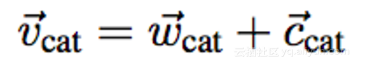
其中 w 和 c 分别表示词向量和上下文向量。实验结果表明这种向量合并的组合方法有助于降低过拟合和噪音的影响,并且能够进一步提升模型效果。
结论
1. 没有一种能够适用于不同NLP应用的词向量模型,应该根据你的具体使用场景选择合适的词向量模型。
2. 除了模型本身,词频也会对类比任务结果的准确率有重要影响。正如上面图中所示,语料库中词的频率不同,模型性能也不同,例如,如果词频很高,得到的精确度可能会比较低。

系统学习,进入全球人工智能学院


