动态 | 百度发布NLP模型ERNIE,基于知识增强,在多个中文NLP任务中表现超越BERT
AI 科技评论消息,Google 近期提出的 BERT 模型,通过预测屏蔽的词,利用 Transformer 的多层 self-attention 双向建模能力,取得了很好的效果。但是,BERT 模型的建模对象主要聚焦在原始语言信号上,较少利用语义知识单元建模。这个问题在中文方面尤为明显,例如,BERT 在处理中文语言时,通过预测汉字进行建模,模型很难学出更大语义单元的完整语义表示。例如,对于乒 [mask] 球,清明上 [mask] 图,[mask] 颜六色这些词,BERT 模型通过字的搭配,很容易推测出掩码的字信息,但没有显式地对语义概念单元 (如乒乓球、清明上河图) 以及其对应的语义关系进行建模。
设想如果能够让模型学习到海量文本中蕴含的潜在知识,势必会进一步提升各个 NLP 任务效果。基于此,百度提出了基于知识增强的 ERNIE 模型。

ERNIE 通过建模海量数据中的词、实体及实体关系,学习真实世界的语义知识。相较于 BERT 学习局部语言共现的语义表示,ERNIE 直接对语义知识进行建模,增强了模型语义表示能力。
例如以下例子:
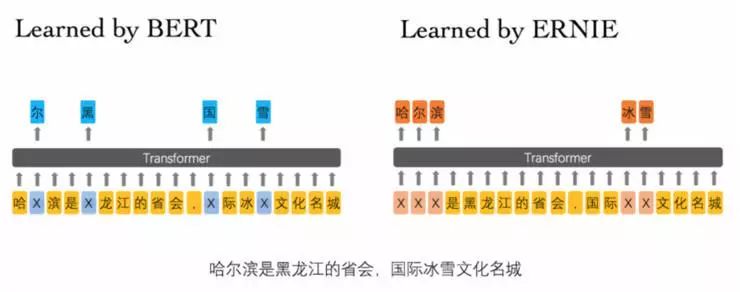
Learned by BERT :哈 [mask] 滨是 [mask] 龙江的省会,[mask] 际冰 [mask] 文化名城。
Learned by ERNIE:[mask] [mask] [mask] 是黑龙江的省会,国际 [mask] [mask] 文化名城。
在 BERT 模型中,通过『哈』与『滨』的局部共现,即可判断出『尔』字,模型没有学习与『哈尔滨』相关的知识。而 ERNIE 通过学习词与实体的表达,使模型能够建模出『哈尔滨』与『黑龙江』的关系,学到『哈尔滨』是『黑龙江』的省会以及『哈尔滨』是个冰雪城市。
训练数据方面,除百科类、资讯类中文语料外,ERNIE 还引入了论坛对话类数据,利用 DLM(Dialogue Language Model)建模 Query-Response 对话结构,将对话 Pair 对作为输入,引入 Dialogue Embedding 标识对话的角色,利用 Dialogue Response Loss 学习对话的隐式关系,进一步提升模型的语义表示能力。
通过在自然语言推断、语义相似度、命名实体识别、情感分析、问答匹配 5 个公开的中文数据集合上进行效果验证,ERNIE 模型相较 BERT 取得了更好的效果。
1. 自然语言推断任务 XNLI
XNLI 由 Facebook 和纽约大学的研究者联合构建,旨在评测模型多语言的句子理解能力。目标是判断两个句子的关系(矛盾、中立、蕴含)。
链接:https://github.com/facebookresearch/XNLI
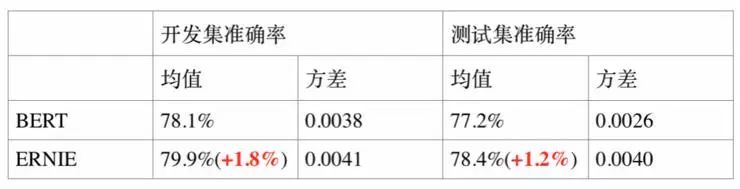
2. 语义相似度任务 LCQMC
LCQMC 是哈尔滨工业大学在自然语言处理国际顶会 COLING2018 构建的问题语义匹配数据集,其目标是判断两个问题的语义是否相同。
链接: http://aclweb.org/anthology/C18-1166
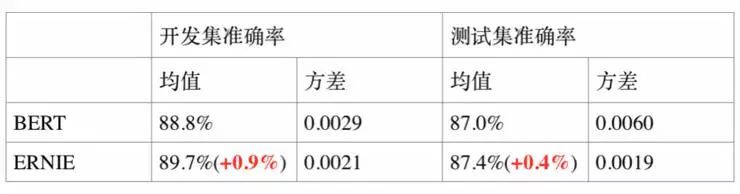
3. 情感分析任务 ChnSentiCorp
ChnSentiCorp 是中文情感分析数据集,其目标是判断一段话的情感态度。
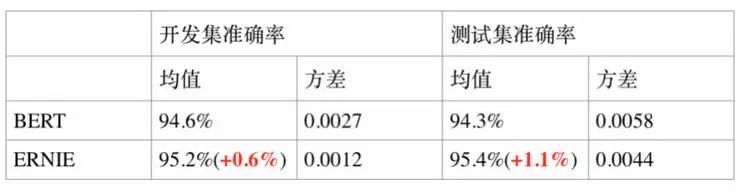
4. 命名实体识别任务 MSRA-NER
MSRA-NER 数据集由微软亚研院发布,其目标是命名实体识别,是指识别文本中具有特定意义的实体,主要包括人名、地名、机构名等。
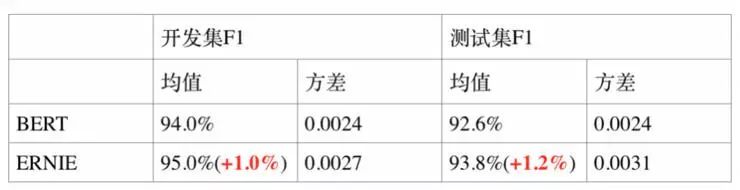
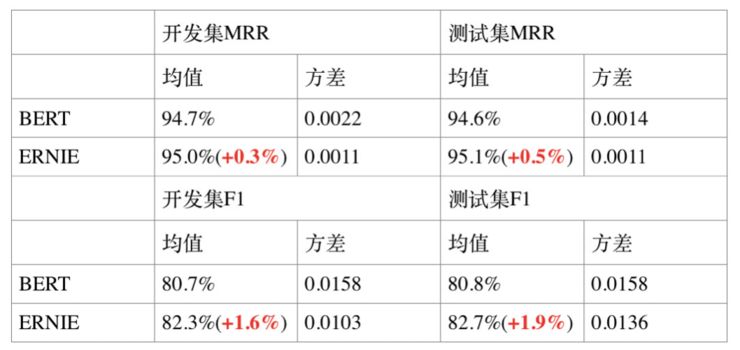
5. 检索式问答匹配任务 NLPCC-DBQA
NLPCC-DBQA 是由国际自然语言处理和中文计算会议 NLPCC 于 2016 年举办的评测任务,其目标是选择能够回答问题的答案。
地址: http://tcci.ccf.org.cn/conference/2016/dldoc/evagline2.pdf
预训练模型下载地址:
https://ernie.bj.bcebos.com/ERNIE.tgz
任务数据下载地址:
https://ernie.bj.bcebos.com/task_data.tgz
Github 地址:
https://github.com/PaddlePaddle/LARK/tree/develop/ERNIE

点击阅读原文,加入 AI 研习社组织的技术交流小组进行更多讨论



